 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Robust Contrastive Alignment Method For Multi-Domain Text Classification
Paper and Code
Apr 26, 2022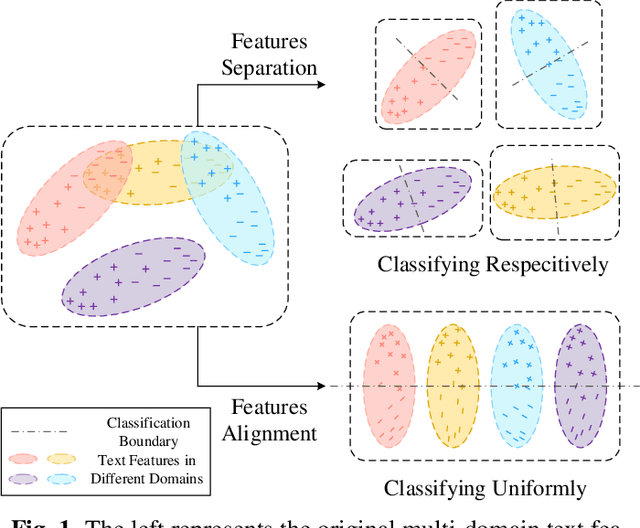
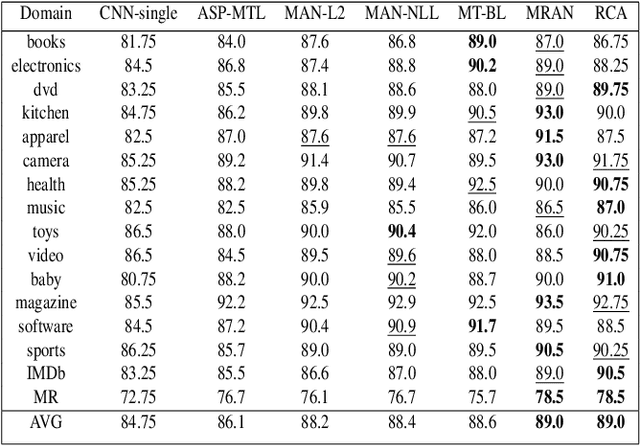
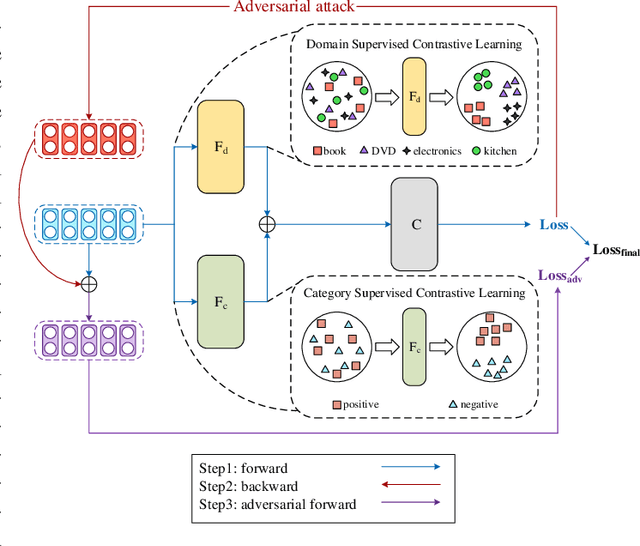
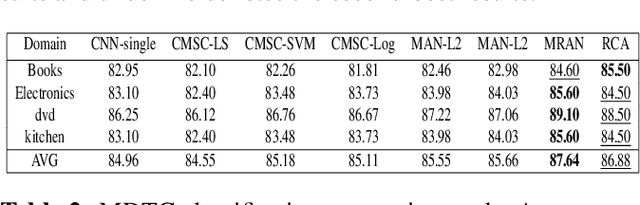
Multi-domain text classification can automatically classify texts in various scenarios. Due to the diversity of human languages, texts with the same label in different domains may differ greatly, which brings challenges to the multi-domain text classification. Current advanced methods use the private-shared paradigm, capturing domain-shared features by a shared encoder, and training a private encoder for each domain to extract domain-specific features. However, in realistic scenarios, these methods suffer from inefficiency as new domains are constantly emerging. In this paper, we propose a robust contrastive alignment method to align text classification features of various domains in the same feature space by supervised contrastive learning. By this means, we only need two universal feature extractors to achieve multi-domain text classification. Extensive experimental results show that our method performs on par with or sometimes better than the state-of-the-art method, which uses the complex multi-classifier in a private-shared framework.