 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Prompt Allocation and Tuning for Continual Test-Time Adaptation
Dec 12, 2024Continual test-time adaptation (CTTA) has recently emerged to adapt a pre-trained source model to continuously evolving target distributions, which accommodates the dynamic nature of real-world environments. To mitigate the risk of catastrophic forgetting in CTTA, existing methods typically incorporate explicit regularization terms to constrain the variation of model parameters. However, they cannot fundamentally resolve catastrophic forgetting because they rely on a single shared model to adapt across all target domains, which inevitably leads to severe inter-domain interference. In this paper, we introduce learnable domain-specific prompts that guide the model to adapt to corresponding target domains, thereby partially disentangling the parameter space of different domains. In the absence of domain identity for target samples, we propose a novel dynamic Prompt AllocatIon aNd Tuning (PAINT) method, which utilizes a query mechanism to dynamically determine whether the current samples come from a known domain or an unexplored one. For known domains, the corresponding domain-specific prompt is directly selected, while for previously unseen domains, a new prompt is allocated. Prompt tuning is subsequently performed using mutual information maximization along with structural regularization. Extensive experiments on three benchmark datasets demonstrate the effectiveness of our PAINT method for CTTA. We have released our code at https://github.com/Cadezzyr/PAINT.
Federated Domain Generalization via Prompt Learning and Aggregation
Nov 15, 2024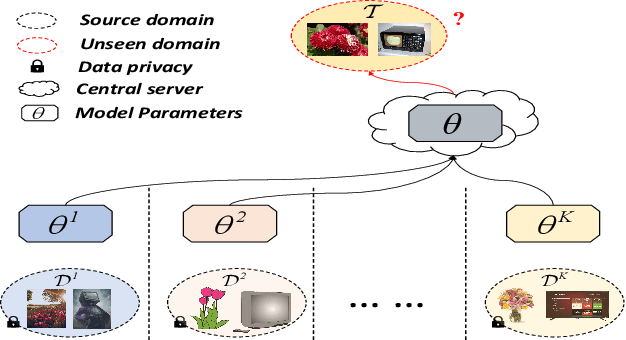
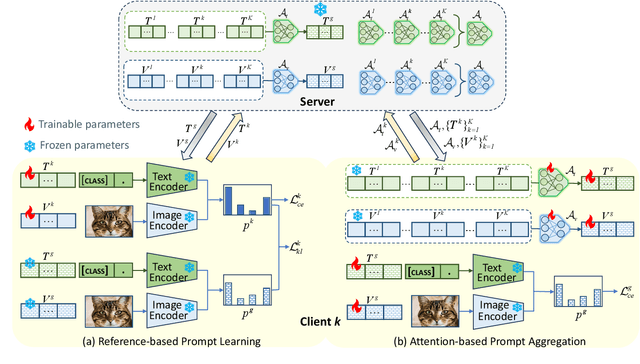
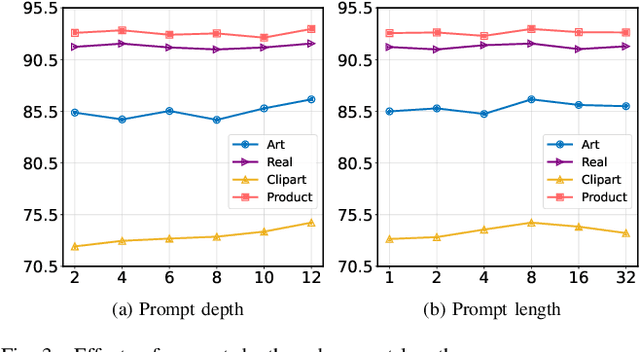
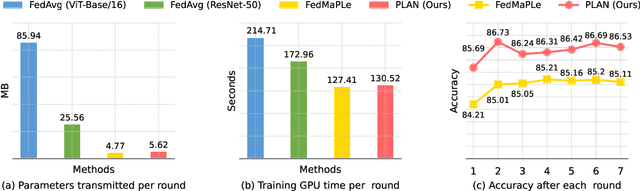
Federated domain generalization (FedDG) aims to improve the global model generalization in unseen domains by addressing data heterogeneity under privacy-preserving constraints. A common strategy in existing FedDG studies involves sharing domain-specific knowledge among clients, such as spectrum information, class prototypes, and data styles. However, this knowledge is extracted directly from local client samples, and sharing such sensitive information poses a potential risk of data leakage, which might not fully meet the requirements of FedDG. In this paper, we introduce prompt learning to adapt pre-trained vision-language models (VLMs) in the FedDG scenario, and leverage locally learned prompts as a more secure bridge to facilitate knowledge transfer among clients. Specifically, we propose a novel FedDG framework through Prompt Learning and AggregatioN (PLAN), which comprises two training stages to collaboratively generate local prompts and global prompts at each federated round. First, each client performs both text and visual prompt learning using their own data, with local prompts indirectly synchronized by regarding the global prompts as a common reference. Second, all domain-specific local prompts are exchanged among clients and selectively aggregated into the global prompts using lightweight attention-based aggregators. The global prompts are finally applied to adapt VLMs to unseen target domains. As our PLAN framework requires training only a limited number of prompts and lightweight aggregators, it offers notable advantages in computational and communication efficiency for FedDG. Extensive experiments demonstrate the superior generalization ability of PLAN across four benchmark datasets.
Do We Fully Understand Students' Knowledge States? Identifying and Mitigating Answer Bias in Knowledge Tracing
Aug 15, 2023



Knowledge tracing (KT) aims to monitor students' evolving knowledge states through their learning interactions with concept-related questions, and can be indirectly evaluated by predicting how students will perform on future questions. In this paper, we observe that there is a common phenomenon of answer bias, i.e., a highly unbalanced distribution of correct and incorrect answers for each question. Existing models tend to memorize the answer bias as a shortcut for achieving high prediction performance in KT, thereby failing to fully understand students' knowledge states. To address this issue, we approach the KT task from a causality perspective. A causal graph of KT is first established, from which we identify that the impact of answer bias lies in the direct causal effect of questions on students' responses. A novel COunterfactual REasoning (CORE) framework for KT is further proposed, which separately captures the total causal effect and direct causal effect during training, and mitigates answer bias by subtracting the latter from the former in testing. The CORE framework is applicable to various existing KT models, and we implement it based on the prevailing DKT, DKVMN, and AKT models, respectively. Extensive experiments on three benchmark datasets demonstrate the effectiveness of CORE in making the debiased inference for KT.
DGEKT: A Dual Graph Ensemble Learning Method for Knowledge Tracing
Nov 23, 2022


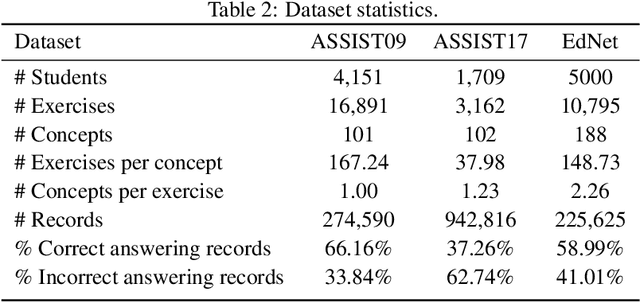
Knowledge tracing aims to trace students' evolving knowledge states by predicting their future performance on concept-related exercises. Recently, some graph-based models have been developed to incorporate the relationships between exercises to improve knowledge tracing, but only a single type of relationship information is generally explored. In this paper, we present a novel Dual Graph Ensemble learning method for Knowledge Tracing (DGEKT), which establishes a dual graph structure of students' learning interactions to capture the heterogeneous exercise-concept associations and interaction transitions by hypergraph modeling and directed graph modeling, respectively. To ensemble the dual graph models, we introduce the technique of online knowledge distillation, due to the fact that although the knowledge tracing model is expected to predict students' responses to the exercises related to different concepts, it is optimized merely with respect to the prediction accuracy on a single exercise at each step. With online knowledge distillation, the dual graph models are adaptively combined to form a stronger teacher model, which in turn provides its predictions on all exercises as extra supervision for better modeling ability. In the experiments, we compare DGEKT against eight knowledge tracing baselines on three benchmark datasets, and the results demonstrate that DGEKT achieves state-of-the-art performance.
A Robust Contrastive Alignment Method For Multi-Domain Text Classification
Apr 26, 2022
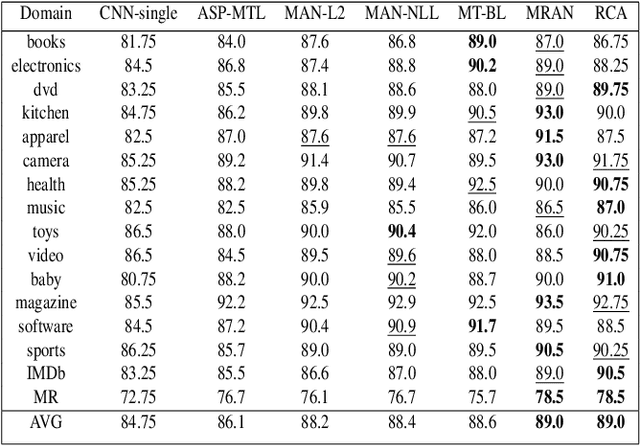
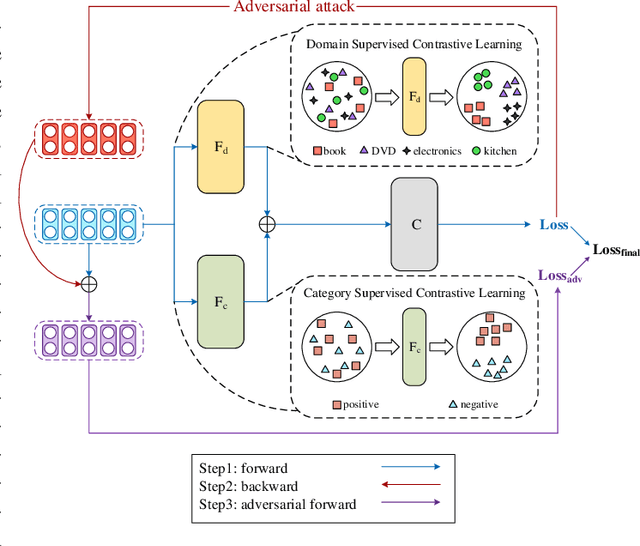
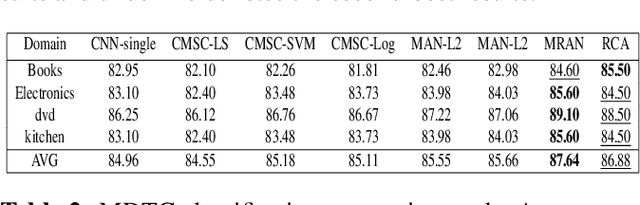
Multi-domain text classification can automatically classify texts in various scenarios. Due to the diversity of human languages, texts with the same label in different domains may differ greatly, which brings challenges to the multi-domain text classification. Current advanced methods use the private-shared paradigm, capturing domain-shared features by a shared encoder, and training a private encoder for each domain to extract domain-specific features. However, in realistic scenarios, these methods suffer from inefficiency as new domains are constantly emerging. In this paper, we propose a robust contrastive alignment method to align text classification features of various domains in the same feature space by supervised contrastive learning. By this means, we only need two universal feature extractors to achieve multi-domain text classification. Extensive experimental results show that our method performs on par with or sometimes better than the state-of-the-art method, which uses the complex multi-classifier in a private-shared framework.
Temporal-Relational Hypergraph Tri-Attention Networks for Stock Trend Prediction
Jul 22, 2021Predicting the future price trends of stocks is a challenging yet intriguing problem given its critical role to help investors make profitable decisions. In this paper, we present a collaborative temporal-relational modeling framework for end-to-end stock trend prediction. The temporal dynamics of stocks is firstly captured with an attention-based recurrent neural network. Then, different from existing studies relying on the pairwise correlations between stocks, we argue that stocks are naturally connected as a collective group, and introduce the hypergraph structures to jointly characterize the stock group-wise relationships of industry-belonging and fund-holding. A novel hypergraph tri-attention network (HGTAN) is proposed to augment the hypergraph convolutional networks with a hierarchical organization of intra-hyperedge, inter-hyperedge, and inter-hypergraph attention modules. In this manner, HGTAN adaptively determines the importance of nodes, hyperedges, and hypergraphs during the information propagation among stocks, so that the potential synergies between stock movements can be fully exploited. Extensive experiments on real-world data demonstrate the effectiveness of our approach. Also, the results of investment simulation show that our approach can achieve a more desirable risk-adjusted return. The data and codes of our work have been released at https://github.com/lixiaojieff/HGTAN.
Reinforced Generative Adversarial Network for Abstractive Text Summarization
May 31, 2021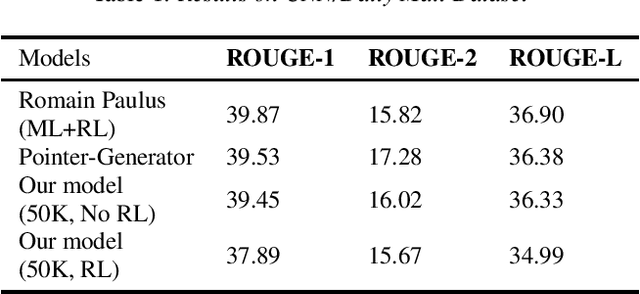
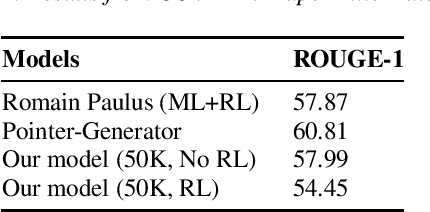
Sequence-to-sequence models provide a viable new approach to generative summarization, allowing models that are no longer limited to simply selecting and recombining sentences from the original text. However, these models have three drawbacks: their grasp of the details of the original text is often inaccurate, and the text generated by such models often has repetitions, while it is difficult to handle words that are beyond the word list. In this paper, we propose a new architecture that combines reinforcement learning and adversarial generative networks to enhance the sequence-to-sequence attention model. First, we use a hybrid pointer-generator network that copies words directly from the source text, contributing to accurate reproduction of information without sacrificing the ability of generators to generate new words. Second, we use both intra-temporal and intra-decoder attention to penalize summarized content and thus discourage repetition. We apply our model to our own proposed COVID-19 paper title summarization task and achieve close approximations to the current model on ROUEG, while bringing better readability.
Generative Adversarial Zero-Shot Relational Learning for Knowledge Graphs
Jan 08, 2020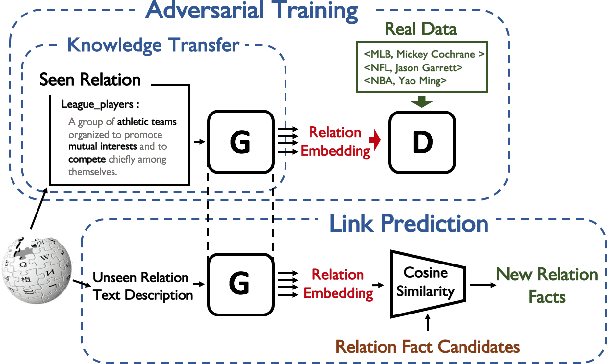

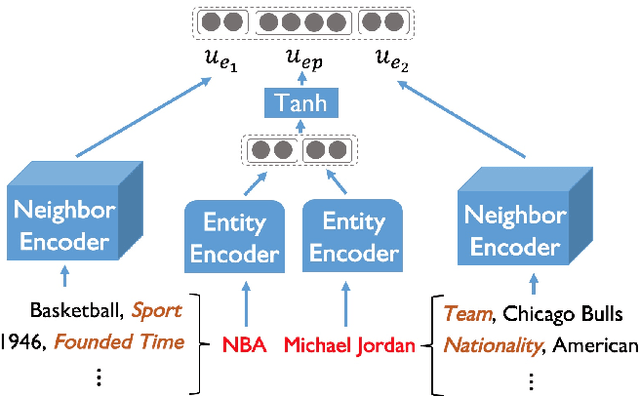
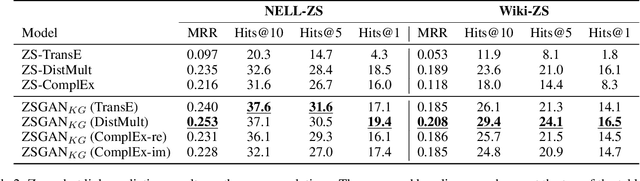
Large-scale knowledge graphs (KGs) are shown to become more important in current information systems. To expand the coverage of KGs, previous studies on knowledge graph completion need to collect adequate training instances for newly-added relations. In this paper, we consider a novel formulation, zero-shot learning, to free this cumbersome curation. For newly-added relations, we attempt to learn their semantic features from their text descriptions and hence recognize the facts of unseen relations with no examples being seen. For this purpose, we leverage Generative Adversarial Networks (GANs) to establish the connection between text and knowledge graph domain: The generator learns to generate the reasonable relation embeddings merely with noisy text descriptions. Under this setting, zero-shot learning is naturally converted to a traditional supervised classification task. Empirically, our method is model-agnostic that could be potentially applied to any version of KG embeddings, and consistently yields performance improvements on NELL and Wiki dataset.