 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo We Fully Understand Students' Knowledge States? Identifying and Mitigating Answer Bias in Knowledge Tracing
Aug 15, 2023



Knowledge tracing (KT) aims to monitor students' evolving knowledge states through their learning interactions with concept-related questions, and can be indirectly evaluated by predicting how students will perform on future questions. In this paper, we observe that there is a common phenomenon of answer bias, i.e., a highly unbalanced distribution of correct and incorrect answers for each question. Existing models tend to memorize the answer bias as a shortcut for achieving high prediction performance in KT, thereby failing to fully understand students' knowledge states. To address this issue, we approach the KT task from a causality perspective. A causal graph of KT is first established, from which we identify that the impact of answer bias lies in the direct causal effect of questions on students' responses. A novel COunterfactual REasoning (CORE) framework for KT is further proposed, which separately captures the total causal effect and direct causal effect during training, and mitigates answer bias by subtracting the latter from the former in testing. The CORE framework is applicable to various existing KT models, and we implement it based on the prevailing DKT, DKVMN, and AKT models, respectively. Extensive experiments on three benchmark datasets demonstrate the effectiveness of CORE in making the debiased inference for KT.
Improving Generalization in Meta-Learning via Meta-Gradient Augmentation
Jun 14, 2023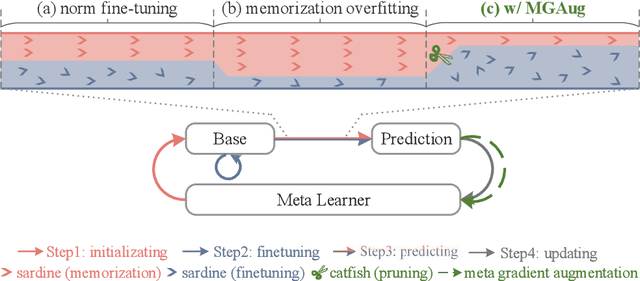
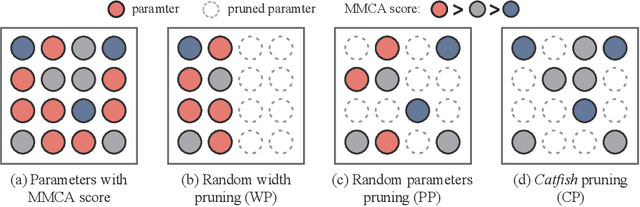
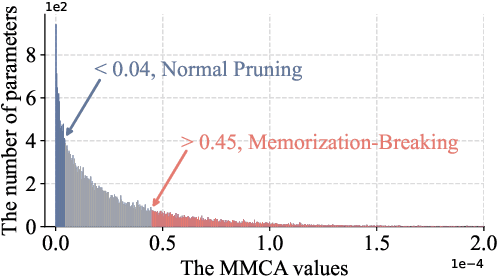
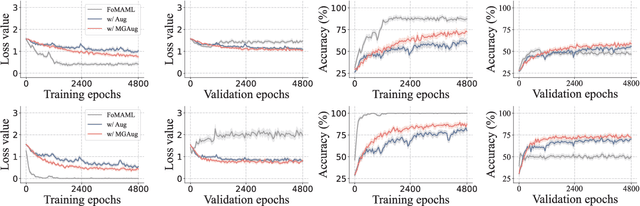
Meta-learning methods typically follow a two-loop framework, where each loop potentially suffers from notorious overfitting, hindering rapid adaptation and generalization to new tasks. Existing schemes solve it by enhancing the mutual-exclusivity or diversity of training samples, but these data manipulation strategies are data-dependent and insufficiently flexible. This work alleviates overfitting in meta-learning from the perspective of gradient regularization and proposes a data-independent \textbf{M}eta-\textbf{G}radient \textbf{Aug}mentation (\textbf{MGAug}) method. The key idea is to first break the rote memories by network pruning to address memorization overfitting in the inner loop, and then the gradients of pruned sub-networks naturally form the high-quality augmentation of the meta-gradient to alleviate learner overfitting in the outer loop. Specifically, we explore three pruning strategies, including \textit{random width pruning}, \textit{random parameter pruning}, and a newly proposed \textit{catfish pruning} that measures a Meta-Memorization Carrying Amount (MMCA) score for each parameter and prunes high-score ones to break rote memories as much as possible. The proposed MGAug is theoretically guaranteed by the generalization bound from the PAC-Bayes framework. In addition, we extend a lightweight version, called MGAug-MaxUp, as a trade-off between performance gains and resource overhead. Extensive experiments on multiple few-shot learning benchmarks validate MGAug's effectiveness and significant improvement over various meta-baselines. The code is publicly available at \url{https://github.com/xxLifeLover/Meta-Gradient-Augmentation}.
MetaViewer: Towards A Unified Multi-View Representation
Mar 11, 2023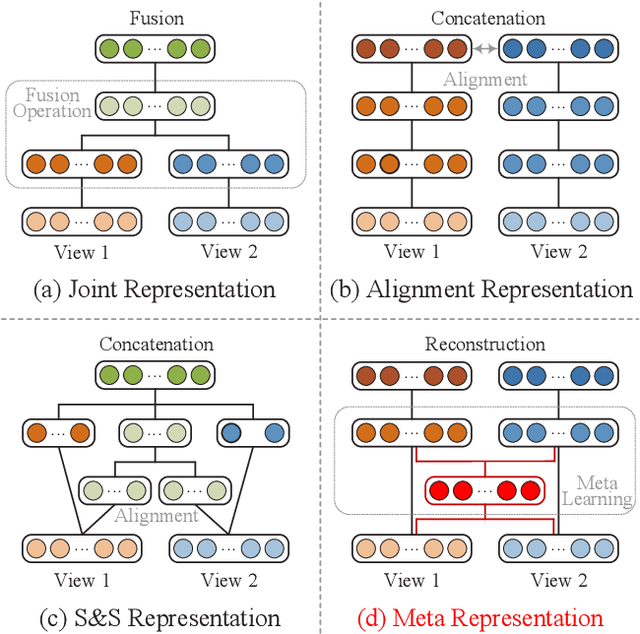
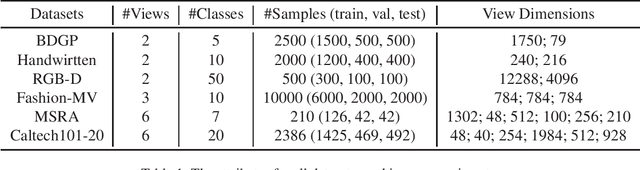
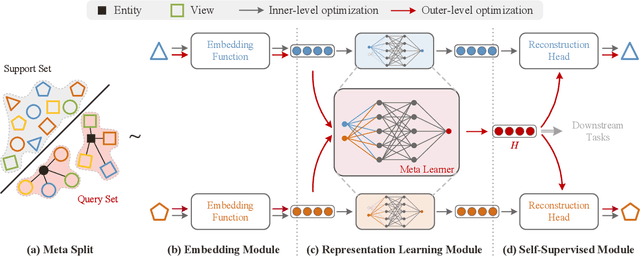
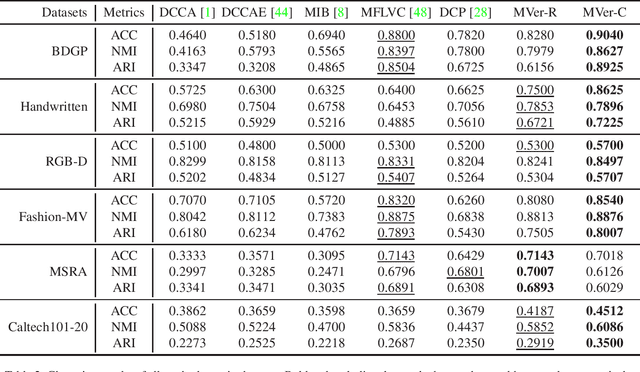
Existing multi-view representation learning methods typically follow a specific-to-uniform pipeline, extracting latent features from each view and then fusing or aligning them to obtain the unified object representation. However, the manually pre-specify fusion functions and view-private redundant information mixed in features potentially degrade the quality of the derived representation. To overcome them, we propose a novel bi-level-optimization-based multi-view learning framework, where the representation is learned in a uniform-to-specific manner. Specifically, we train a meta-learner, namely MetaViewer, to learn fusion and model the view-shared meta representation in outer-level optimization. Start with this meta representation, view-specific base-learners are then required to rapidly reconstruct the corresponding view in inner-level. MetaViewer eventually updates by observing reconstruction processes from uniform to specific over all views, and learns an optimal fusion scheme that separates and filters out view-private information. Extensive experimental results in downstream tasks such as classification and clustering demonstrate the effectiveness of our method.
DGEKT: A Dual Graph Ensemble Learning Method for Knowledge Tracing
Nov 23, 2022


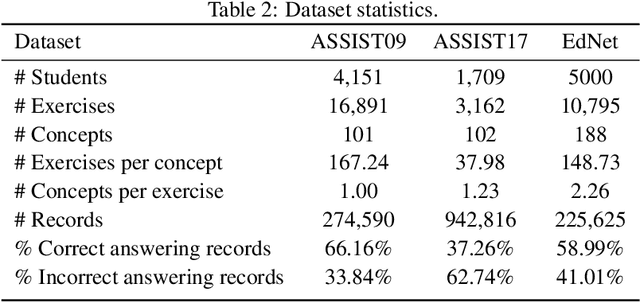
Knowledge tracing aims to trace students' evolving knowledge states by predicting their future performance on concept-related exercises. Recently, some graph-based models have been developed to incorporate the relationships between exercises to improve knowledge tracing, but only a single type of relationship information is generally explored. In this paper, we present a novel Dual Graph Ensemble learning method for Knowledge Tracing (DGEKT), which establishes a dual graph structure of students' learning interactions to capture the heterogeneous exercise-concept associations and interaction transitions by hypergraph modeling and directed graph modeling, respectively. To ensemble the dual graph models, we introduce the technique of online knowledge distillation, due to the fact that although the knowledge tracing model is expected to predict students' responses to the exercises related to different concepts, it is optimized merely with respect to the prediction accuracy on a single exercise at each step. With online knowledge distillation, the dual graph models are adaptively combined to form a stronger teacher model, which in turn provides its predictions on all exercises as extra supervision for better modeling ability. In the experiments, we compare DGEKT against eight knowledge tracing baselines on three benchmark datasets, and the results demonstrate that DGEKT achieves state-of-the-art performance.
Tri-Branch Convolutional Neural Networks for Top-$k$ Focused Academic Performance Prediction
Jul 22, 2021
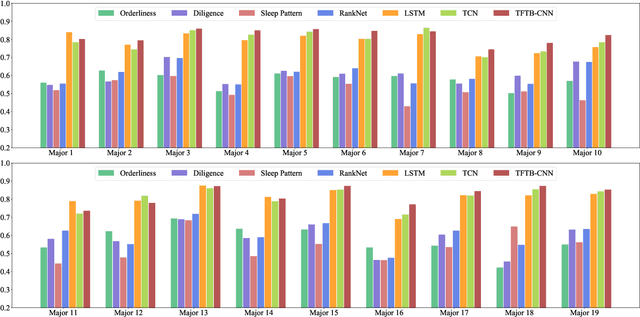
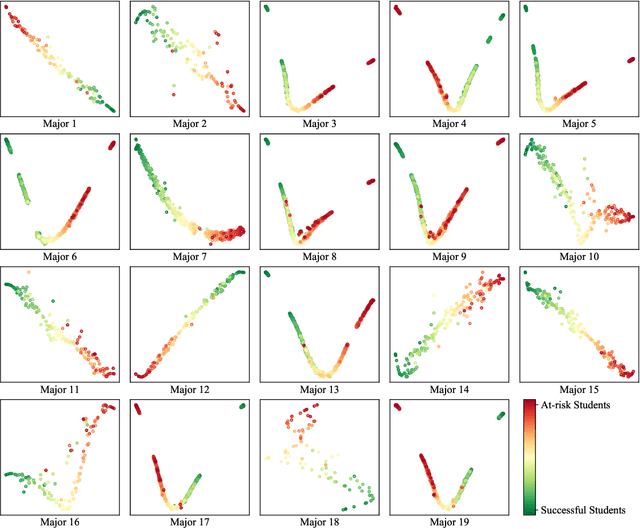

Academic performance prediction aims to leverage student-related information to predict their future academic outcomes, which is beneficial to numerous educational applications, such as personalized teaching and academic early warning. In this paper, we address the problem by analyzing students' daily behavior trajectories, which can be comprehensively tracked with campus smartcard records. Different from previous studies, we propose a novel Tri-Branch CNN architecture, which is equipped with row-wise, column-wise, and depth-wise convolution and attention operations, to capture the characteristics of persistence, regularity, and temporal distribution of student behavior in an end-to-end manner, respectively. Also, we cast academic performance prediction as a top-$k$ ranking problem, and introduce a top-$k$ focused loss to ensure the accuracy of identifying academically at-risk students. Extensive experiments were carried out on a large-scale real-world dataset, and we show that our approach substantially outperforms recently proposed methods for academic performance prediction. For the sake of reproducibility, our codes have been released at https://github.com/ZongJ1111/Academic-Performance-Prediction.