 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaViewer: Towards A Unified Multi-View Representation
Mar 11, 2023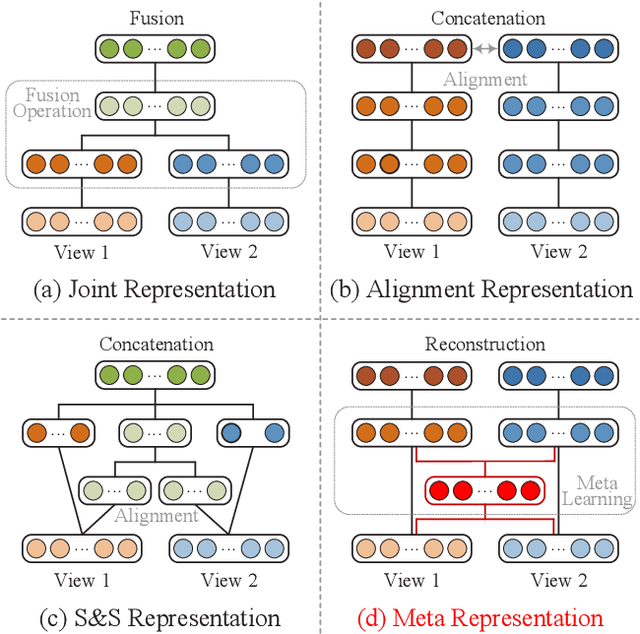
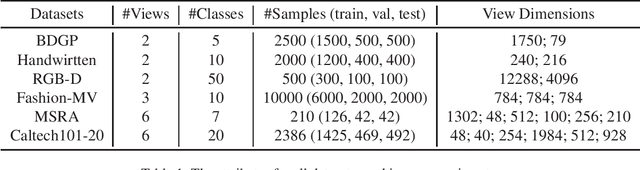
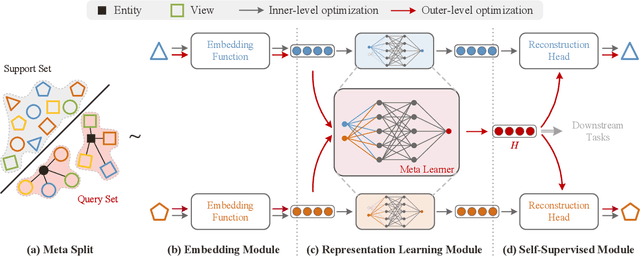
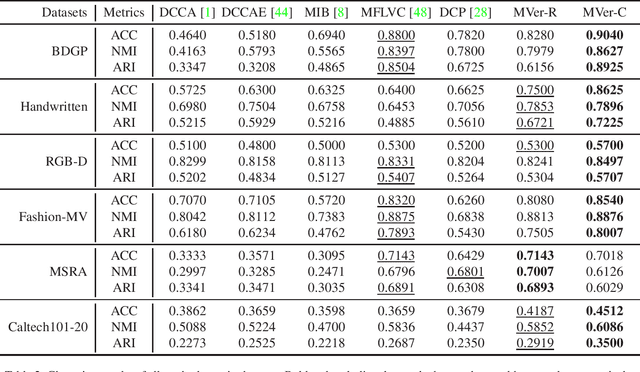
Existing multi-view representation learning methods typically follow a specific-to-uniform pipeline, extracting latent features from each view and then fusing or aligning them to obtain the unified object representation. However, the manually pre-specify fusion functions and view-private redundant information mixed in features potentially degrade the quality of the derived representation. To overcome them, we propose a novel bi-level-optimization-based multi-view learning framework, where the representation is learned in a uniform-to-specific manner. Specifically, we train a meta-learner, namely MetaViewer, to learn fusion and model the view-shared meta representation in outer-level optimization. Start with this meta representation, view-specific base-learners are then required to rapidly reconstruct the corresponding view in inner-level. MetaViewer eventually updates by observing reconstruction processes from uniform to specific over all views, and learns an optimal fusion scheme that separates and filters out view-private information. Extensive experimental results in downstream tasks such as classification and clustering demonstrate the effectiveness of our method.
Attention Model Enhanced Network for Classification of Breast Cancer Image
Oct 07, 2020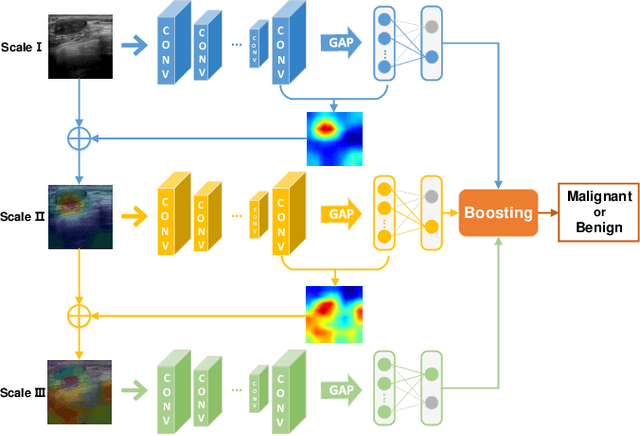
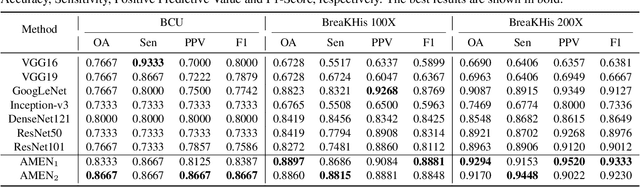
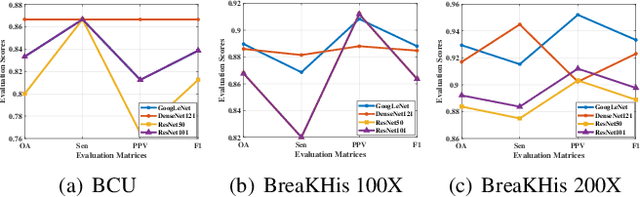
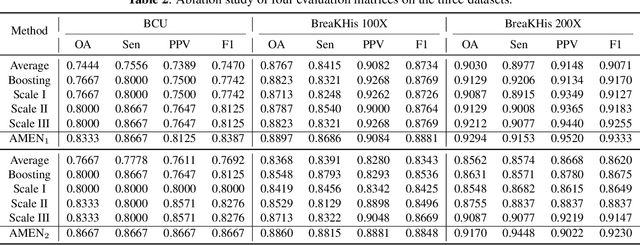
Breast cancer classification remains a challenging task due to inter-class ambiguity and intra-class variability. Existing deep learning-based methods try to confront this challenge by utilizing complex nonlinear projections. However, these methods typically extract global features from entire images, neglecting the fact that the subtle detail information can be crucial in extracting discriminative features. In this study, we propose a novel method named Attention Model Enhanced Network (AMEN), which is formulated in a multi-branch fashion with pixel-wised attention model and classification submodular. Specifically, the feature learning part in AMEN can generate pixel-wised attention map, while the classification submodular are utilized to classify the samples. To focus more on subtle detail information, the sample image is enhanced by the pixel-wised attention map generated from former branch. Furthermore, boosting strategy are adopted to fuse classification results from different branches for better performance. Experiments conducted on three benchmark datasets demonstrate the superiority of the proposed method under various scenarios.