 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCortical Policy: A Dual-Stream View Transformer for Robotic Manipulation
Mar 22, 2026View transformers process multi-view observations to predict actions and have shown impressive performance in robotic manipulation. Existing methods typically extract static visual representations in a view-specific manner, leading to inadequate 3D spatial reasoning ability and a lack of dynamic adaptation. Taking inspiration from how the human brain integrates static and dynamic views to address these challenges, we propose Cortical Policy, a novel dual-stream view transformer for robotic manipulation that jointly reasons from static-view and dynamic-view streams. The static-view stream enhances spatial understanding by aligning features of geometrically consistent keypoints extracted from a pretrained 3D foundation model. The dynamic-view stream achieves adaptive adjustment through position-aware pretraining of an egocentric gaze estimation model, computationally replicating the human cortical dorsal pathway. Subsequently, the complementary view representations of both streams are integrated to determine the final actions, enabling the model to handle spatially-complex and dynamically-changing tasks under language conditions. Empirical evaluations on RLBench, the challenging COLOSSEUM benchmark, and real-world tasks demonstrate that Cortical Policy outperforms state-of-the-art baselines substantially, validating the superiority of dual-stream design for visuomotor control. Our cortex-inspired framework offers a fresh perspective for robotic manipulation and holds potential for broader application in vision-based robot control.
Unveiling the Superior Paradigm: A Comparative Study of Source-Free Domain Adaptation and Unsupervised Domain Adaptation
Nov 24, 2024In domain adaptation, there are two popular paradigms: Unsupervised Domain Adaptation (UDA), which aligns distributions using source data, and Source-Free Domain Adaptation (SFDA), which leverages pre-trained source models without accessing source data. Evaluating the superiority of UDA versus SFDA is an open and timely question with significant implications for deploying adaptive algorithms in practical applications. In this study, we demonstrate through predictive coding theory and extensive experiments on multiple benchmark datasets that SFDA generally outperforms UDA in real-world scenarios. Specifically, SFDA offers advantages in time efficiency, storage requirements, targeted learning objectives, reduced risk of negative transfer, and increased robustness against overfitting. Notably, SFDA is particularly effective in mitigating negative transfer when there are substantial distribution discrepancies between source and target domains. Additionally, we introduce a novel data-model fusion scenario, where data sharing among stakeholders varies (e.g., some provide raw data while others provide only models), and reveal that traditional UDA and SFDA methods do not fully exploit their potential in this context. To address this limitation and capitalize on the strengths of SFDA, we propose a novel weight estimation method that effectively integrates available source data into multi-SFDA (MSFDA) approaches, thereby enhancing model performance within this scenario. This work provides a thorough analysis of UDA versus SFDA and advances a practical approach to model adaptation across diverse real-world environments.
Attention Model Enhanced Network for Classification of Breast Cancer Image
Oct 07, 2020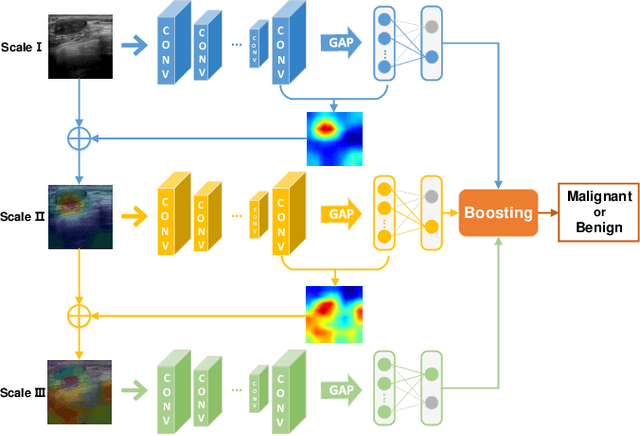
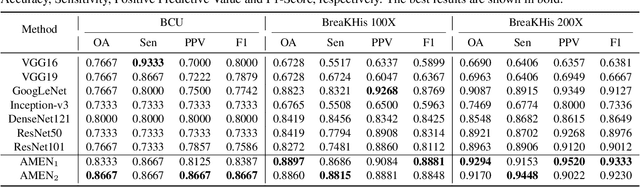
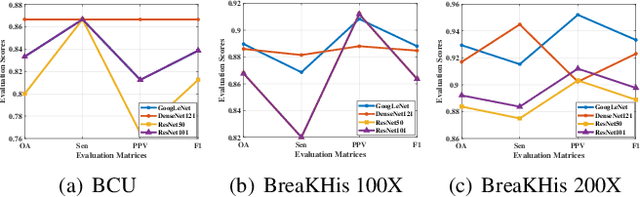
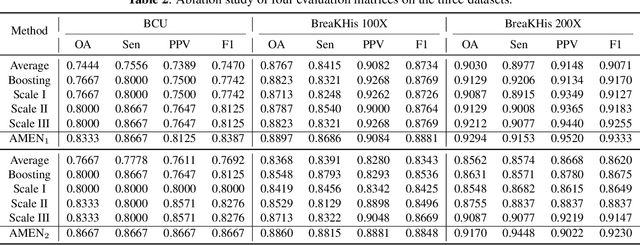
Breast cancer classification remains a challenging task due to inter-class ambiguity and intra-class variability. Existing deep learning-based methods try to confront this challenge by utilizing complex nonlinear projections. However, these methods typically extract global features from entire images, neglecting the fact that the subtle detail information can be crucial in extracting discriminative features. In this study, we propose a novel method named Attention Model Enhanced Network (AMEN), which is formulated in a multi-branch fashion with pixel-wised attention model and classification submodular. Specifically, the feature learning part in AMEN can generate pixel-wised attention map, while the classification submodular are utilized to classify the samples. To focus more on subtle detail information, the sample image is enhanced by the pixel-wised attention map generated from former branch. Furthermore, boosting strategy are adopted to fuse classification results from different branches for better performance. Experiments conducted on three benchmark datasets demonstrate the superiority of the proposed method under various scenarios.
Learning Binary Semantic Embedding for Histology Image Classification and Retrieval
Oct 07, 2020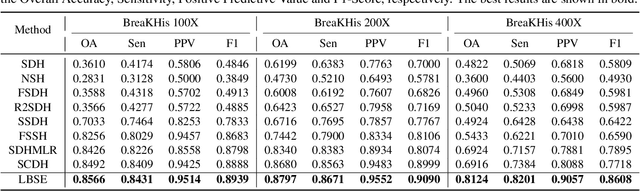
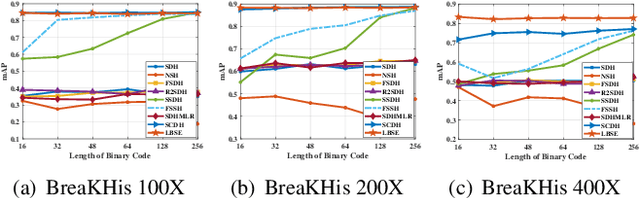
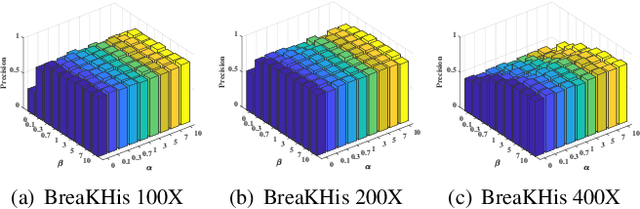
With the development of medical imaging technology and machine learning, computer-assisted diagnosis which can provide impressive reference to pathologists, attracts extensive research interests. The exponential growth of medical images and uninterpretability of traditional classification models have hindered the applications of computer-assisted diagnosis. To address these issues, we propose a novel method for Learning Binary Semantic Embedding (LBSE). Based on the efficient and effective embedding, classification and retrieval are performed to provide interpretable computer-assisted diagnosis for histology images. Furthermore, double supervision, bit uncorrelation and balance constraint, asymmetric strategy and discrete optimization are seamlessly integrated in the proposed method for learning binary embedding. Experiments conducted on three benchmark datasets validate the superiority of LBSE under various scenarios.
Reinforcing Short-Length Hashing
Apr 24, 2020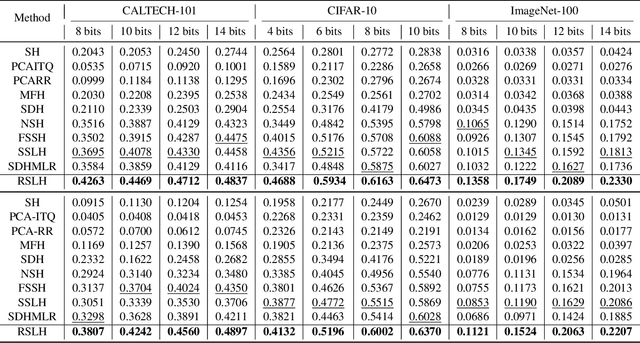
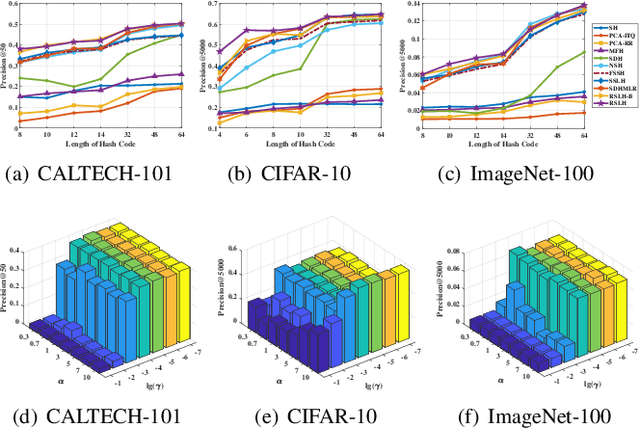
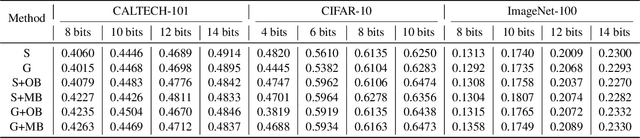
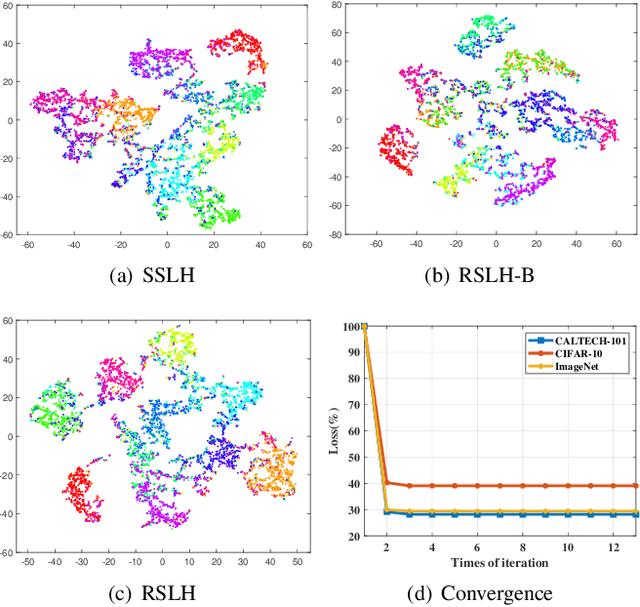
Due to the compelling efficiency in retrieval and storage, similarity-preserving hashing has been widely applied to approximate nearest neighbor search in large-scale image retrieval. However, existing methods have poor performance in retrieval using an extremely short-length hash code due to weak ability of classification and poor distribution of hash bit. To address this issue, in this study, we propose a novel reinforcing short-length hashing (RSLH). In this proposed RSLH, mutual reconstruction between the hash representation and semantic labels is performed to preserve the semantic information. Furthermore, to enhance the accuracy of hash representation, a pairwise similarity matrix is designed to make a balance between accuracy and training expenditure on memory. In addition, a parameter boosting strategy is integrated to reinforce the precision with hash bits fusion. Extensive experiments on three large-scale image benchmarks demonstrate the superior performance of RSLH under various short-length hashing scenarios.
Mutual Linear Regression-based Discrete Hashing
Mar 15, 2019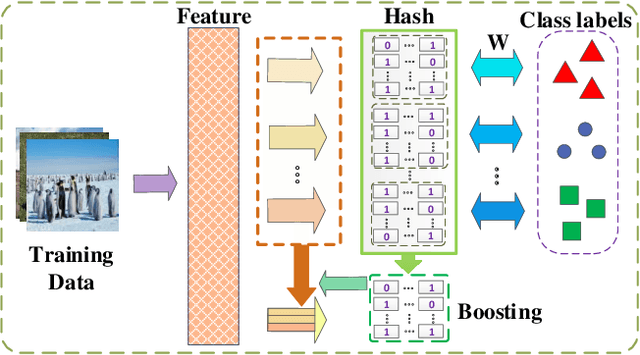

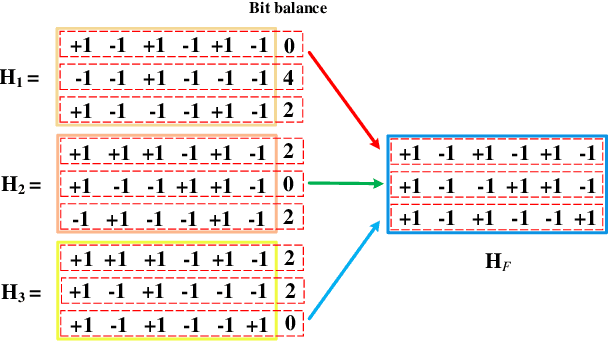
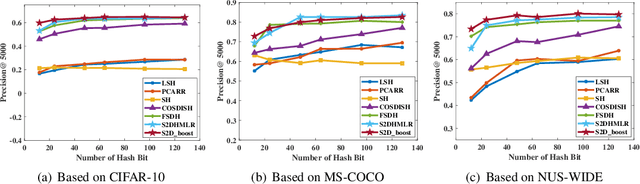
Label information is widely used in hashing methods because of its effectiveness of improving the precision. The existing hashing methods always use two different projections to represent the mutual regression between hash codes and class labels. In contrast to the existing methods, we propose a novel learning-based hashing method termed stable supervised discrete hashing with mutual linear regression (S2DHMLR) in this study, where only one stable projection is used to describe the linear correlation between hash codes and corresponding labels. To the best of our knowledge, this strategy has not been used for hashing previously. In addition, we further use a boosting strategy to improve the final performance of the proposed method without adding extra constraints and with little extra expenditure in terms of time and space. Extensive experiments conducted on three image benchmarks demonstrate the superior performance of the proposed method.