 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaViewer: Towards A Unified Multi-View Representation
Paper and Code
Mar 11, 2023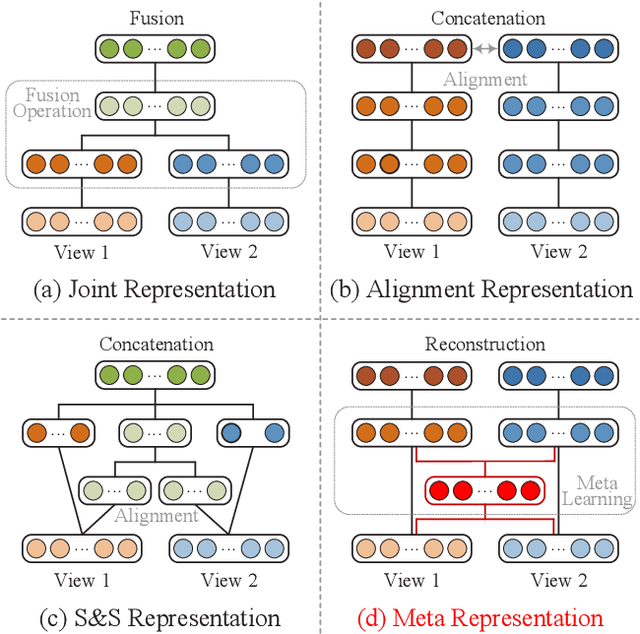
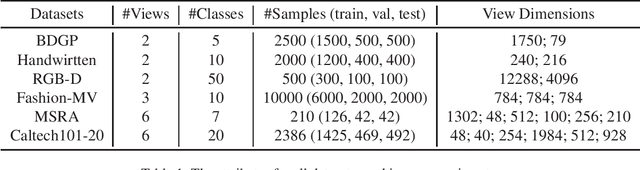
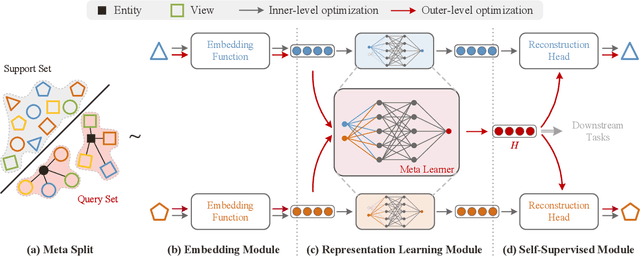
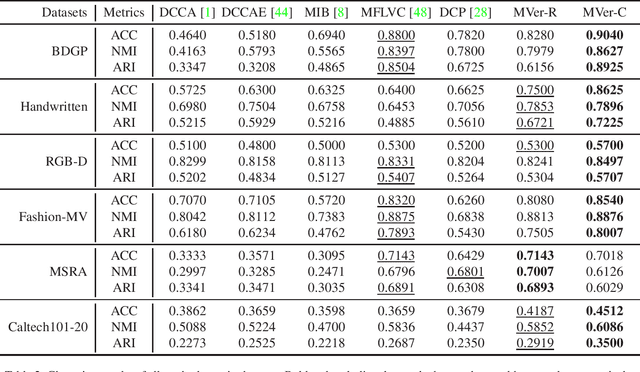
Existing multi-view representation learning methods typically follow a specific-to-uniform pipeline, extracting latent features from each view and then fusing or aligning them to obtain the unified object representation. However, the manually pre-specify fusion functions and view-private redundant information mixed in features potentially degrade the quality of the derived representation. To overcome them, we propose a novel bi-level-optimization-based multi-view learning framework, where the representation is learned in a uniform-to-specific manner. Specifically, we train a meta-learner, namely MetaViewer, to learn fusion and model the view-shared meta representation in outer-level optimization. Start with this meta representation, view-specific base-learners are then required to rapidly reconstruct the corresponding view in inner-level. MetaViewer eventually updates by observing reconstruction processes from uniform to specific over all views, and learns an optimal fusion scheme that separates and filters out view-private information. Extensive experimental results in downstream tasks such as classification and clustering demonstrate the effectiveness of our method.