 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActions Generation from Captions
Paper and Code
Feb 14, 2019

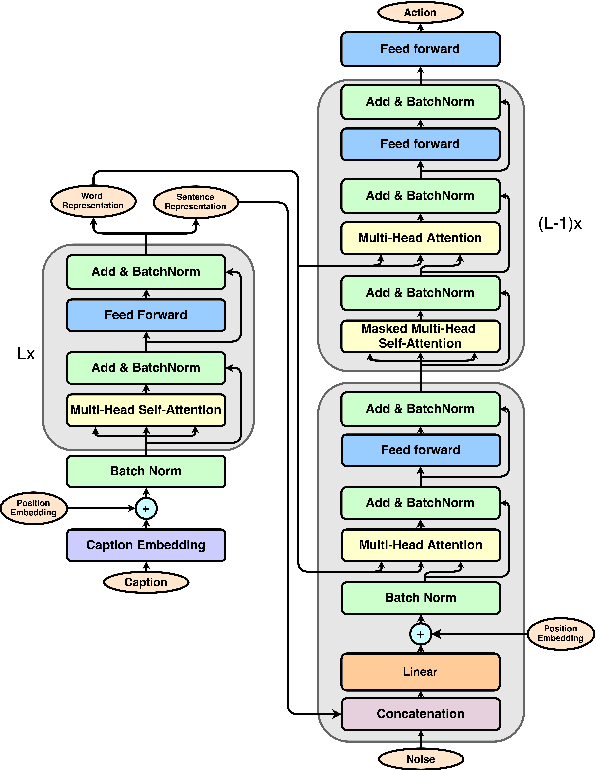
Sequence transduction models have been widely explored in many natural language processing tasks. However, the target sequence usually consists of discrete tokens which represent word indices in a given vocabulary. We barely see the case where target sequence is composed of continuous vectors, where each vector is an element of a time series taken successively in a temporal domain. In this work, we introduce a new data set, named Action Generation Data Set (AGDS) which is specifically designed to carry out the task of caption-to-action generation. This data set contains caption-action pairs. The caption is comprised of a sequence of words describing the interactive movement between two people, and the action is a captured sequence of poses representing the movement. This data set is introduced to study the ability of generating continuous sequences through sequence transduction models. We also propose a model to innovatively combine Multi-Head Attention (MHA) and Generative Adversarial Network (GAN) together. In our model, we have one generator to generate actions from captions and three discriminators where each of them is designed to carry out a unique functionality: caption-action consistency discriminator, pose discriminator and pose transition discriminator. This novel design allowed us to achieve plausible generation performance which is demonstrated in the experiments.