 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Role of Rehearsal Scale in Continual Learning under Varying Model Capacities
Feb 24, 2026Rehearsal is one of the key techniques for mitigating catastrophic forgetting and has been widely adopted in continual learning algorithms due to its simplicity and practicality. However, the theoretical understanding of how rehearsal scale influences learning dynamics remains limited. To address this gap, we formulate rehearsal-based continual learning as a multidimensional effectiveness-driven iterative optimization problem, providing a unified characterization across diverse performance metrics. Within this framework, we derive a closed-form analysis of adaptability, memorability, and generalization from the perspective of rehearsal scale. Our results uncover several intriguing and counterintuitive findings. First, rehearsal can impair model's adaptability, in sharp contrast to its traditionally recognized benefits. Second, increasing the rehearsal scale does not necessarily improve memory retention. When tasks are similar and noise levels are low, the memory error exhibits a diminishing lower bound. Finally, we validate these insights through numerical simulations and extended analyses on deep neural networks across multiple real-world datasets, revealing statistical patterns of rehearsal mechanisms in continual learning.
Exploring the Impact of Parameter Update Magnitude on Forgetting and Generalization of Continual Learning
Feb 24, 2026The magnitude of parameter updates are considered a key factor in continual learning. However, most existing studies focus on designing diverse update strategies, while a theoretical understanding of the underlying mechanisms remains limited. Therefore, we characterize model's forgetting from the perspective of parameter update magnitude and formalize it as knowledge degradation induced by task-specific drift in the parameter space, which has not been fully captured in previous studies due to their assumption of a unified parameter space. By deriving the optimal parameter update magnitude that minimizes forgetting, we unify two representative update paradigms, frozen training and initialized training, within an optimization framework for constrained parameter updates. Our theoretical results further reveals that sequence tasks with small parameter distances exhibit better generalization and less forgetting under frozen training rather than initialized training. These theoretical insights inspire a novel hybrid parameter update strategy that adaptively adjusts update magnitude based on gradient directions. Experiments on deep neural networks demonstrate that this hybrid approach outperforms standard training strategies, providing new theoretical perspectives and practical inspiration for designing efficient and scalable continual learning algorithms.
LLM-Guided Diagnostic Evidence Alignment for Medical Vision-Language Pretraining under Limited Pairing
Feb 07, 2026Most existing CLIP-style medical vision--language pretraining methods rely on global or local alignment with substantial paired data. However, global alignment is easily dominated by non-diagnostic information, while local alignment fails to integrate key diagnostic evidence. As a result, learning reliable diagnostic representations becomes difficult, which limits their applicability in medical scenarios with limited paired data. To address this issue, we propose an LLM-Guided Diagnostic Evidence Alignment method (LGDEA), which shifts the pretraining objective toward evidence-level alignment that is more consistent with the medical diagnostic process. Specifically, we leverage LLMs to extract key diagnostic evidence from radiology reports and construct a shared diagnostic evidence space, enabling evidence-aware cross-modal alignment and allowing LGDEA to effectively exploit abundant unpaired medical images and reports, thereby substantially alleviating the reliance on paired data. Extensive experimental results demonstrate that our method achieves consistent and significant improvements on phrase grounding, image--text retrieval, and zero-shot classification, and even rivals pretraining methods that rely on substantial paired data.
Bipartite Graph Attention-based Clustering for Large-scale scRNA-seq Data
Feb 07, 2026scRNA-seq clustering is a critical task for analyzing single-cell RNA sequencing (scRNA-seq) data, as it groups cells with similar gene expression profiles. Transformers, as powerful foundational models, have been applied to scRNA-seq clustering. Their self-attention mechanism automatically assigns higher attention weights to cells within the same cluster, enhancing the distinction between clusters. Existing methods for scRNA-seq clustering, such as graph transformer-based models, treat each cell as a token in a sequence. Their computational and space complexities are $\mathcal{O}(n^2)$ with respect to the number of cells, limiting their applicability to large-scale scRNA-seq datasets.To address this challenge, we propose a Bipartite Graph Transformer-based clustering model (BGFormer) for scRNA-seq data. We introduce a set of learnable anchor tokens as shared reference points to represent the entire dataset. A bipartite graph attention mechanism is introduced to learn the similarity between cells and anchor tokens, bringing cells of the same class closer together in the embedding space. BGFormer achieves linear computational complexity with respect to the number of cells, making it scalable to large datasets. Experimental results on multiple large-scale scRNA-seq datasets demonstrate the effectiveness and scalability of BGFormer.
One-Step Generative Policies with Q-Learning: A Reformulation of MeanFlow
Nov 17, 2025We introduce a one-step generative policy for offline reinforcement learning that maps noise directly to actions via a residual reformulation of MeanFlow, making it compatible with Q-learning. While one-step Gaussian policies enable fast inference, they struggle to capture complex, multimodal action distributions. Existing flow-based methods improve expressivity but typically rely on distillation and two-stage training when trained with Q-learning. To overcome these limitations, we propose to reformulate MeanFlow to enable direct noise-to-action generation by integrating the velocity field and noise-to-action transformation into a single policy network-eliminating the need for separate velocity estimation. We explore several reformulation variants and identify an effective residual formulation that supports expressive and stable policy learning. Our method offers three key advantages: 1) efficient one-step noise-to-action generation, 2) expressive modelling of multimodal action distributions, and 3) efficient and stable policy learning via Q-learning in a single-stage training setup. Extensive experiments on 73 tasks across the OGBench and D4RL benchmarks demonstrate that our method achieves strong performance in both offline and offline-to-online reinforcement learning settings. Code is available at https://github.com/HiccupRL/MeanFlowQL.
FoCLIP: A Feature-Space Misalignment Framework for CLIP-Based Image Manipulation and Detection
Nov 10, 2025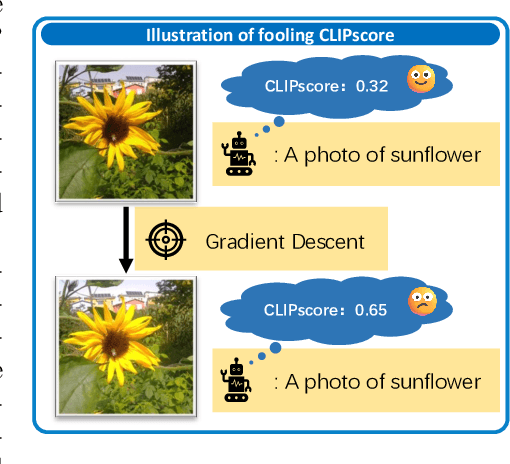
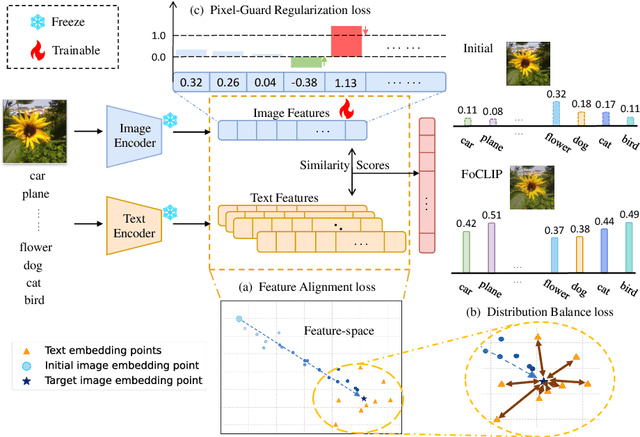
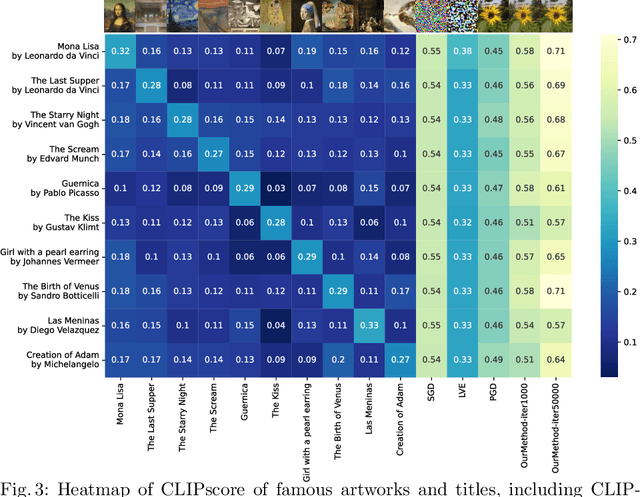
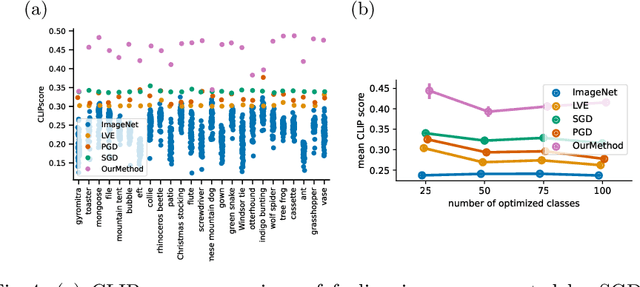
The well-aligned attribute of CLIP-based models enables its effective application like CLIPscore as a widely adopted image quality assessment metric. However, such a CLIP-based metric is vulnerable for its delicate multimodal alignment. In this work, we propose \textbf{FoCLIP}, a feature-space misalignment framework for fooling CLIP-based image quality metric. Based on the stochastic gradient descent technique, FoCLIP integrates three key components to construct fooling examples: feature alignment as the core module to reduce image-text modality gaps, the score distribution balance module and pixel-guard regularization, which collectively optimize multimodal output equilibrium between CLIPscore performance and image quality. Such a design can be engineered to maximize the CLIPscore predictions across diverse input prompts, despite exhibiting either visual unrecognizability or semantic incongruence with the corresponding adversarial prompts from human perceptual perspectives. Experiments on ten artistic masterpiece prompts and ImageNet subsets demonstrate that optimized images can achieve significant improvement in CLIPscore while preserving high visual fidelity. In addition, we found that grayscale conversion induces significant feature degradation in fooling images, exhibiting noticeable CLIPscore reduction while preserving statistical consistency with original images. Inspired by this phenomenon, we propose a color channel sensitivity-driven tampering detection mechanism that achieves 91% accuracy on standard benchmarks. In conclusion, this work establishes a practical pathway for feature misalignment in CLIP-based multimodal systems and the corresponding defense method.
Sculpting Margin Penalty: Intra-Task Adapter Merging and Classifier Calibration for Few-Shot Class-Incremental Learning
Aug 07, 2025Real-world applications often face data privacy constraints and high acquisition costs, making the assumption of sufficient training data in incremental tasks unrealistic and leading to significant performance degradation in class-incremental learning. Forward-compatible learning, which prospectively prepares for future tasks during base task training, has emerged as a promising solution for Few-Shot Class-Incremental Learning (FSCIL). However, existing methods still struggle to balance base-class discriminability and new-class generalization. Moreover, limited access to original data during incremental tasks often results in ambiguous inter-class decision boundaries. To address these challenges, we propose SMP (Sculpting Margin Penalty), a novel FSCIL method that strategically integrates margin penalties at different stages within the parameter-efficient fine-tuning paradigm. Specifically, we introduce the Margin-aware Intra-task Adapter Merging (MIAM) mechanism for base task learning. MIAM trains two sets of low-rank adapters with distinct classification losses: one with a margin penalty to enhance base-class discriminability, and the other without margin constraints to promote generalization to future new classes. These adapters are then adaptively merged to improve forward compatibility. For incremental tasks, we propose a Margin Penalty-based Classifier Calibration (MPCC) strategy to refine decision boundaries by fine-tuning classifiers on all seen classes' embeddings with a margin penalty. Extensive experiments on CIFAR100, ImageNet-R, and CUB200 demonstrate that SMP achieves state-of-the-art performance in FSCIL while maintaining a better balance between base and new classes.
C-LoRA: Continual Low-Rank Adaptation for Pre-trained Models
Feb 25, 2025



Low-Rank Adaptation (LoRA) is an efficient fine-tuning method that has been extensively applied in areas such as natural language processing and computer vision. Existing LoRA fine-tuning approaches excel in static environments but struggle in dynamic learning due to reliance on multiple adapter modules, increasing overhead and complicating inference. We propose Continual Low-Rank Adaptation (C-LoRA), a novel extension of LoRA for continual learning. C-LoRA uses a learnable routing matrix to dynamically manage parameter updates across tasks, ensuring efficient reuse of learned subspaces while enforcing orthogonality to minimize interference and forgetting. Unlike existing approaches that require separate adapters for each task, C-LoRA enables a integrated approach for task adaptation, achieving both scalability and parameter efficiency in sequential learning scenarios. C-LoRA achieves state-of-the-art accuracy and parameter efficiency on benchmarks while providing theoretical insights into its routing matrix's role in retaining and transferring knowledge, establishing a scalable framework for continual learning.
Progressive Local Alignment for Medical Multimodal Pre-training
Feb 25, 2025Local alignment between medical images and text is essential for accurate diagnosis, though it remains challenging due to the absence of natural local pairings and the limitations of rigid region recognition methods. Traditional approaches rely on hard boundaries, which introduce uncertainty, whereas medical imaging demands flexible soft region recognition to handle irregular structures. To overcome these challenges, we propose the Progressive Local Alignment Network (PLAN), which designs a novel contrastive learning-based approach for local alignment to establish meaningful word-pixel relationships and introduces a progressive learning strategy to iteratively refine these relationships, enhancing alignment precision and robustness. By combining these techniques, PLAN effectively improves soft region recognition while suppressing noise interference. Extensive experiments on multiple medical datasets demonstrate that PLAN surpasses state-of-the-art methods in phrase grounding, image-text retrieval, object detection, and zero-shot classification, setting a new benchmark for medical image-text alignment.
Unlocking Multimodal Integration in EHRs: A Prompt Learning Framework for Language and Time Series Fusion
Feb 19, 2025Large language models (LLMs) have shown remarkable performance in vision-language tasks, but their application in the medical field remains underexplored, particularly for integrating structured time series data with unstructured clinical notes. In clinical practice, dynamic time series data such as lab test results capture critical temporal patterns, while clinical notes provide rich semantic context. Merging these modalities is challenging due to the inherent differences between continuous signals and discrete text. To bridge this gap, we introduce ProMedTS, a novel self-supervised multimodal framework that employs prompt-guided learning to unify these heterogeneous data types. Our approach leverages lightweight anomaly detection to generate anomaly captions that serve as prompts, guiding the encoding of raw time series data into informative embeddings. These embeddings are aligned with textual representations in a shared latent space, preserving fine-grained temporal nuances alongside semantic insights. Furthermore, our framework incorporates tailored self-supervised objectives to enhance both intra- and inter-modal alignment. We evaluate ProMedTS on disease diagnosis tasks using real-world datasets, and the results demonstrate that our method consistently outperforms state-of-the-art approaches.