 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Visual Speech Analysis: A Survey
May 22, 2022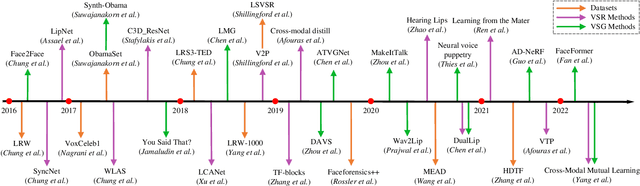
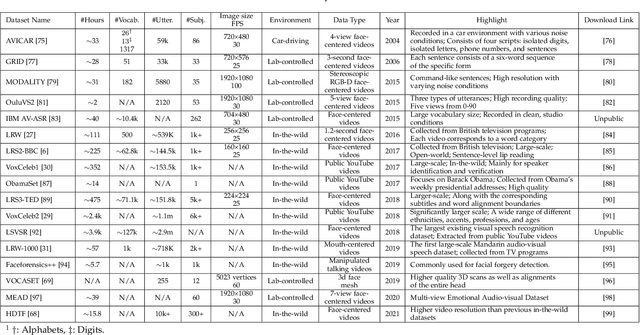
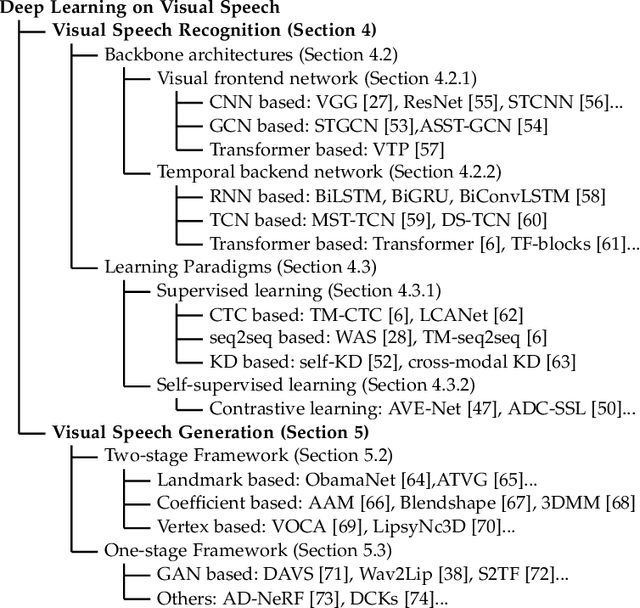

Visual speech, referring to the visual domain of speech, has attracted increasing attention due to its wide applications, such as public security, medical treatment, military defense, and film entertainment. As a powerful AI strategy, deep learning techniques have extensively promoted the development of visual speech learning. Over the past five years, numerous deep learning based methods have been proposed to address various problems in this area, especially automatic visual speech recognition and generation. To push forward future research on visual speech, this paper aims to present a comprehensive review of recent progress in deep learning methods on visual speech analysis. We cover different aspects of visual speech, including fundamental problems, challenges, benchmark datasets, a taxonomy of existing methods, and state-of-the-art performance. Besides, we also identify gaps in current research and discuss inspiring future research directions.