 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrecting Visual Blur Induced by Attention Distraction to Reduce Hallucinations: Algorithm and Theory
May 23, 2026Multimodal large language models (MLLMs) frequently suffer from object hallucinations, yet the visual perceptual mechanism underlying this failure remains poorly understood. In this work, we reveal that hallucinations are strongly associated with a human-like attention distraction phenomenon, where humans under divided focus experience degraded visual clarity and produce inaccurate descriptions, while in models the same mechanism manifests as spatial inconsistency in multi-head attention and temporal fading of attention to image tokens during decoding. We further provide theoretical insights that attention dispersion increases model complexity and degrades classification generalization. Motivated by these findings, we propose an Attention-Focused Approach for Improved Image Perception (AFIP), which corrects attention distraction via cross-head attention enrichment and reinforces visual grounding through dynamic historical attention enhancement. Extensive experiments on multiple benchmarks and models validate the effectiveness of AFIP without additional training.
Feature Incremental Clustering with Generalization Bounds
Mar 23, 2026In many learning systems, such as activity recognition systems, as new data collection methods continue to emerge in various dynamic environmental applications, the attributes of instances accumulate incrementally, with data being stored in gradually expanding feature spaces. How to design theoretically guaranteed algorithms to effectively cluster this special type of data stream, commonly referred to as activity recognition, remains unexplored. Compared to traditional scenarios, we will face at least two fundamental questions in this feature incremental scenario. (i) How to design preliminary and effective algorithms to address the feature incremental clustering problem? (ii) How to analyze the generalization bounds for the proposed algorithms and under what conditions do these algorithms provide a strong generalization guarantee? To address these problems, by tailoring the most common clustering algorithm, i.e., $k$-means, as an example, we propose four types of Feature Incremental Clustering (FIC) algorithms corresponding to different situations of data access: Feature Tailoring (FT), Data Reconstruction (DR), Data Adaptation (DA), and Model Reuse (MR), abbreviated as FIC-FT, FIC-DR, FIC-DA, and FIC-MR. Subsequently, we offer a detailed analysis of the generalization error bounds for these four algorithms and highlight the critical factors influencing these bounds, such as the amounts of training data, the complexity of the hypothesis space, the quality of pre-trained models, and the discrepancy of the reconstruction feature distribution. The numerical experiments show the effectiveness of the proposed algorithms, particularly in their application to activity recognition clustering tasks.
Adaptive Disentangled Representation Learning for Incomplete Multi-View Multi-Label Classification
Jan 09, 2026Multi-view multi-label learning frequently suffers from simultaneous feature absence and incomplete annotations, due to challenges in data acquisition and cost-intensive supervision. To tackle the complex yet highly practical problem while overcoming the existing limitations of feature recovery, representation disentanglement, and label semantics modeling, we propose an Adaptive Disentangled Representation Learning method (ADRL). ADRL achieves robust view completion by propagating feature-level affinity across modalities with neighborhood awareness, and reinforces reconstruction effectiveness by leveraging a stochastic masking strategy. Through disseminating category-level association across label distributions, ADRL refines distribution parameters for capturing interdependent label prototypes. Besides, we formulate a mutual-information-based objective to promote consistency among shared representations and suppress information overlap between view-specific representation and other modalities. Theoretically, we derive the tractable bounds to train the dual-channel network. Moreover, ADRL performs prototype-specific feature selection by enabling independent interactions between label embeddings and view representations, accompanied by the generation of pseudo-labels for each category. The structural characteristics of the pseudo-label space are then exploited to guide a discriminative trade-off during view fusion. Finally, extensive experiments on public datasets and real-world applications demonstrate the superior performance of ADRL.
Continuous Subspace Optimization for Continual Learning
May 17, 2025Continual learning aims to learn multiple tasks sequentially while preserving prior knowledge, but faces the challenge of catastrophic forgetting when acquiring new knowledge. Recently, approaches leveraging pre-trained models have gained increasing popularity to mitigate this issue, due to the strong generalization ability of foundation models. To adjust pre-trained models for new tasks, existing methods usually employ low-rank adaptation, which restricts parameter updates to a fixed low-rank subspace. However, constraining the optimization space inherently compromises the model's learning capacity, resulting in inferior performance. To address the limitation, we propose Continuous Subspace Optimization for Continual Learning (CoSO) to fine-tune the model in a series of subspaces rather than a single one. These sequential subspaces are dynamically determined through the singular value decomposition of gradients. CoSO updates the model by projecting gradients into these subspaces, ensuring memory-efficient optimization. To mitigate forgetting, the optimization subspaces of each task are set to be orthogonal to the historical task subspace. During task learning, CoSO maintains a task-specific component that captures the critical update directions associated with the current task. Upon completing a task, this component is used to update the historical task subspace, laying the groundwork for subsequent learning. Extensive experiments on multiple datasets demonstrate that CoSO significantly outperforms state-of-the-art methods, especially in challenging scenarios with long task sequences.
Theory-inspired Label Shift Adaptation via Aligned Distribution Mixture
Nov 05, 2024



As a prominent challenge in addressing real-world issues within a dynamic environment, label shift, which refers to the learning setting where the source (training) and target (testing) label distributions do not match, has recently received increasing attention. Existing label shift methods solely use unlabeled target samples to estimate the target label distribution, and do not involve them during the classifier training, resulting in suboptimal utilization of available information. One common solution is to directly blend the source and target distributions during the training of the target classifier. However, we illustrate the theoretical deviation and limitations of the direct distribution mixture in the label shift setting. To tackle this crucial yet unexplored issue, we introduce the concept of aligned distribution mixture, showcasing its theoretical optimality and generalization error bounds. By incorporating insights from generalization theory, we propose an innovative label shift framework named as Aligned Distribution Mixture (ADM). Within this framework, we enhance four typical label shift methods by introducing modifications to the classifier training process. Furthermore, we also propose a one-step approach that incorporates a pioneering coupling weight estimation strategy. Considering the distinctiveness of the proposed one-step approach, we develop an efficient bi-level optimization strategy. Experimental results demonstrate the effectiveness of our approaches, together with their effectiveness in COVID-19 diagnosis applications.
Theoretically Guaranteed Distribution Adaptable Learning
Nov 05, 2024In many open environment applications, data are collected in the form of a stream, which exhibits an evolving distribution over time. How to design algorithms to track these evolving data distributions with provable guarantees, particularly in terms of the generalization ability, remains a formidable challenge. To handle this crucial but rarely studied problem and take a further step toward robust artificial intelligence, we propose a novel framework called Distribution Adaptable Learning (DAL). It enables the model to effectively track the evolving data distributions. By Encoding Feature Marginal Distribution Information (EFMDI), we broke the limitations of optimal transport to characterize the environmental changes and enable model reuse across diverse data distributions. It can enhance the reusable and evolvable properties of DAL in accommodating evolving distributions. Furthermore, to obtain the model interpretability, we not only analyze the generalization error bound of the local step in the evolution process, but also investigate the generalization error bound associated with the entire classifier trajectory of the evolution based on the Fisher-Rao distance. For demonstration, we also present two special cases within the framework, together with their optimizations and convergence analyses. Experimental results over both synthetic and real-world data distribution evolving tasks validate the effectiveness and practical utility of the proposed framework.
A Novel Adaptive Causal Sampling Method for Physics-Informed Neural Networks
Oct 24, 2022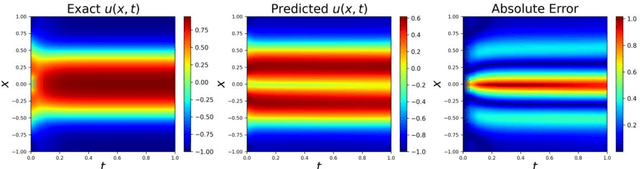
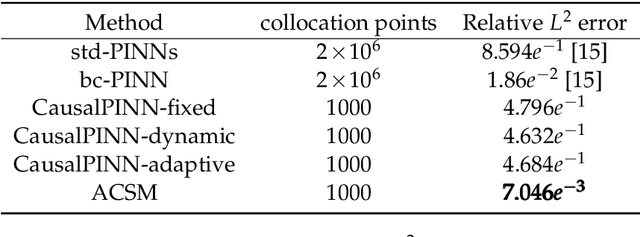
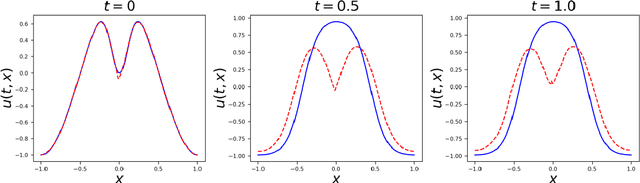
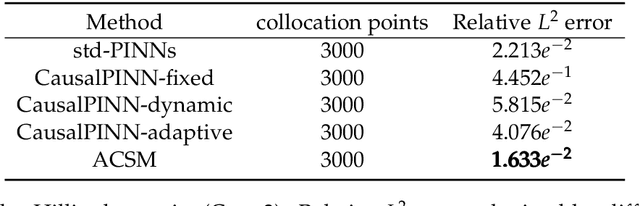
Physics-Informed Neural Networks (PINNs) have become a kind of attractive machine learning method for obtaining solutions of partial differential equations (PDEs). Training PINNs can be seen as a semi-supervised learning task, in which only exact values of initial and boundary points can be obtained in solving forward problems, and in the whole spatio-temporal domain collocation points are sampled without exact labels, which brings training difficulties. Thus the selection of collocation points and sampling methods are quite crucial in training PINNs. Existing sampling methods include fixed and dynamic types, and in the more popular latter one, sampling is usually controlled by PDE residual loss. We point out that it is not sufficient to only consider the residual loss in adaptive sampling and sampling should obey temporal causality. We further introduce temporal causality into adaptive sampling and propose a novel adaptive causal sampling method to improve the performance and efficiency of PINNs. Numerical experiments of several PDEs with high-order derivatives and strong nonlinearity, including Cahn Hilliard and KdV equations, show that the proposed sampling method can improve the performance of PINNs with few collocation points. We demonstrate that by utilizing such a relatively simple sampling method, prediction performance can be improved up to two orders of magnitude compared with state-of-the-art results with almost no extra computation cost, especially when points are limited.
Deep Learning for Visual Speech Analysis: A Survey
May 22, 2022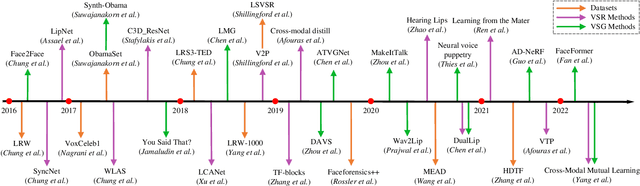
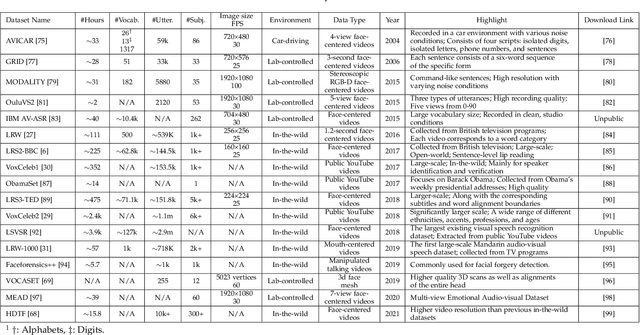
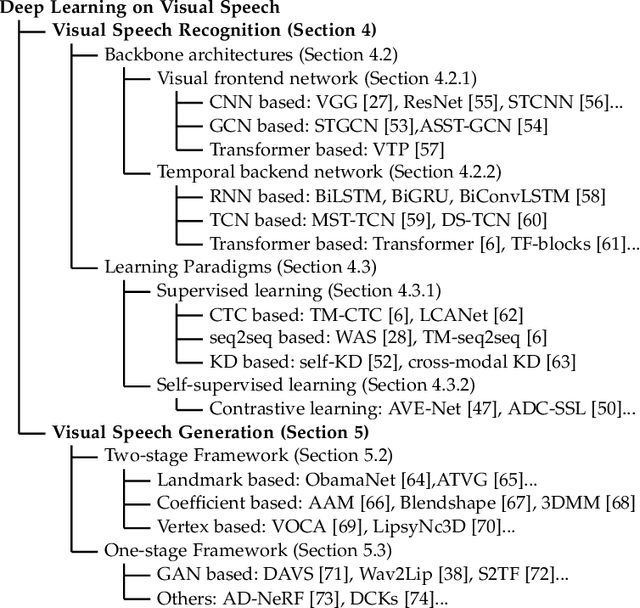

Visual speech, referring to the visual domain of speech, has attracted increasing attention due to its wide applications, such as public security, medical treatment, military defense, and film entertainment. As a powerful AI strategy, deep learning techniques have extensively promoted the development of visual speech learning. Over the past five years, numerous deep learning based methods have been proposed to address various problems in this area, especially automatic visual speech recognition and generation. To push forward future research on visual speech, this paper aims to present a comprehensive review of recent progress in deep learning methods on visual speech analysis. We cover different aspects of visual speech, including fundamental problems, challenges, benchmark datasets, a taxonomy of existing methods, and state-of-the-art performance. Besides, we also identify gaps in current research and discuss inspiring future research directions.
Latent Complete Row Space Recovery for Multi-view Subspace Clustering
Dec 16, 2019
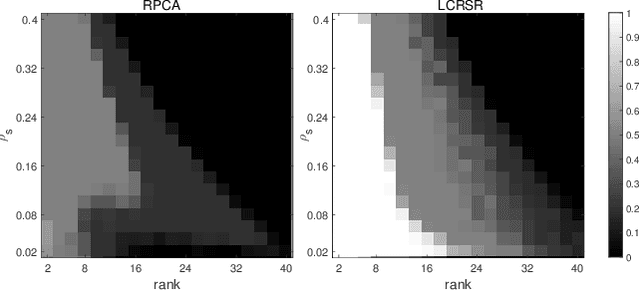


Multi-view subspace clustering has been applied to applications such as image processing and video surveillance, and has attracted increasing attention. Most existing methods learn view-specific self-representation matrices, and construct a combined affinity matrix from multiple views. The affinity construction process is time-consuming, and the combined affinity matrix is not guaranteed to reflect the whole true subspace structure. To overcome these issues, the Latent Complete Row Space Recovery (LCRSR) method is proposed. Concretely, LCRSR is based on the assumption that the multi-view observations are generated from an underlying latent representation, which is further assumed to collect the authentic samples drawn exactly from multiple subspaces. LCRSR is able to recover the row space of the latent representation, which not only carries complete information from multiple views but also determines the subspace membership under certain conditions. LCRSR does not involve the graph construction procedure and is solved with an efficient and convergent algorithm, thereby being more scalable to large-scale datasets. The effectiveness and efficiency of LCRSR are validated by clustering various kinds of multi-view data and illustrated in the background subtraction task.
Joint Embedding Learning and Low-Rank Approximation: A Framework for Incomplete Multi-view Learning
Dec 25, 2018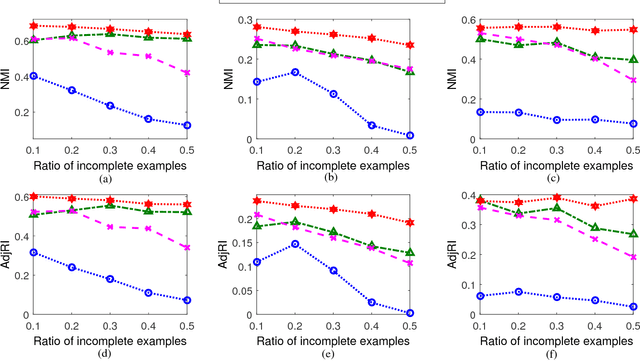
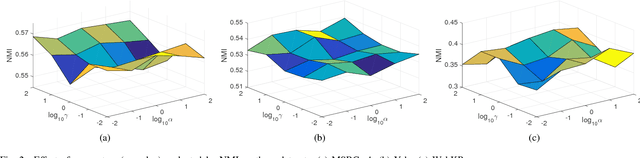
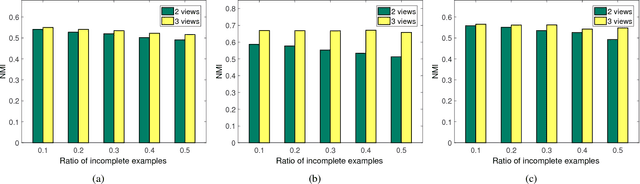
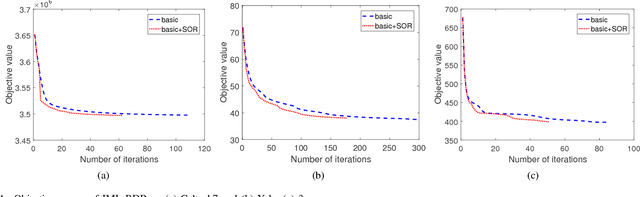
In real-world applications, not all instances in multi-view data are fully represented. To deal with incomplete multi-view data, traditional multi-view algorithms usually throw away the incomplete instances, resulting in loss of available information. To overcome this loss, Incomplete Multi-view Learning (IML) has become a hot research topic. In this paper, we propose a general IML framework for unifying existing IML methods and gaining insight into IML. The proposed framework jointly performs embedding learning and low-rank approximation. Concretely, it approximates the incomplete data by a set of low-rank matrices and learns a full and common embedding by linear transformation. Several existing IML methods can be unified as special cases of the framework. More interestingly, some linear transformation based full-view methods can be adapted to IML directly with the guidance of the framework. This bridges the gap between full multi-view learning and IML. Moreover, the framework can provide guidance for developing new algorithms. For illustration, within the framework, we propose a specific method, termed as Incomplete Multi-view Learning with Block Diagonal Representation (IML-BDR). Based on the assumption that the sampled examples have approximate linear subspace structure, IML-BDR uses the block diagonal structure prior to learn the full embedding, which would lead to more correct clustering. A convergent alternating iterative algorithm with the Successive Over-Relaxation (SOR) optimization technique is devised for optimization. Experimental results on various datasets demonstrate the effectiveness of IML-BDR.