 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid Salient Object Detection with Difference Convolutional Neural Networks
Jul 01, 2025This paper addresses the challenge of deploying salient object detection (SOD) on resource-constrained devices with real-time performance. While recent advances in deep neural networks have improved SOD, existing top-leading models are computationally expensive. We propose an efficient network design that combines traditional wisdom on SOD and the representation power of modern CNNs. Like biologically-inspired classical SOD methods relying on computing contrast cues to determine saliency of image regions, our model leverages Pixel Difference Convolutions (PDCs) to encode the feature contrasts. Differently, PDCs are incorporated in a CNN architecture so that the valuable contrast cues are extracted from rich feature maps. For efficiency, we introduce a difference convolution reparameterization (DCR) strategy that embeds PDCs into standard convolutions, eliminating computation and parameters at inference. Additionally, we introduce SpatioTemporal Difference Convolution (STDC) for video SOD, enhancing the standard 3D convolution with spatiotemporal contrast capture. Our models, SDNet for image SOD and STDNet for video SOD, achieve significant improvements in efficiency-accuracy trade-offs. On a Jetson Orin device, our models with $<$ 1M parameters operate at 46 FPS and 150 FPS on streamed images and videos, surpassing the second-best lightweight models in our experiments by more than $2\times$ and $3\times$ in speed with superior accuracy. Code will be available at https://github.com/hellozhuo/stdnet.git.
Lightweight Pixel Difference Networks for Efficient Visual Representation Learning
Feb 01, 2024



Recently, there have been tremendous efforts in developing lightweight Deep Neural Networks (DNNs) with satisfactory accuracy, which can enable the ubiquitous deployment of DNNs in edge devices. The core challenge of developing compact and efficient DNNs lies in how to balance the competing goals of achieving high accuracy and high efficiency. In this paper we propose two novel types of convolutions, dubbed \emph{Pixel Difference Convolution (PDC) and Binary PDC (Bi-PDC)} which enjoy the following benefits: capturing higher-order local differential information, computationally efficient, and able to be integrated with existing DNNs. With PDC and Bi-PDC, we further present two lightweight deep networks named \emph{Pixel Difference Networks (PiDiNet)} and \emph{Binary PiDiNet (Bi-PiDiNet)} respectively to learn highly efficient yet more accurate representations for visual tasks including edge detection and object recognition. Extensive experiments on popular datasets (BSDS500, ImageNet, LFW, YTF, \emph{etc.}) show that PiDiNet and Bi-PiDiNet achieve the best accuracy-efficiency trade-off. For edge detection, PiDiNet is the first network that can be trained without ImageNet, and can achieve the human-level performance on BSDS500 at 100 FPS and with $<$1M parameters. For object recognition, among existing Binary DNNs, Bi-PiDiNet achieves the best accuracy and a nearly $2\times$ reduction of computational cost on ResNet18. Code available at \href{https://github.com/hellozhuo/pidinet}{https://github.com/hellozhuo/pidinet}.
Few-shot Class-incremental Learning: A Survey
Aug 13, 2023



Few-shot Class-Incremental Learning (FSCIL) presents a unique challenge in machine learning, as it necessitates the continuous learning of new classes from sparse labeled training samples without forgetting previous knowledge. While this field has seen recent progress, it remains an active area of exploration. This paper aims to provide a comprehensive and systematic review of FSCIL. In our in-depth examination, we delve into various facets of FSCIL, encompassing the problem definition, the discussion of primary challenges of unreliable empirical risk minimization and the stability-plasticity dilemma, general schemes, and relevant problems of incremental learning and few-shot learning. Besides, we offer an overview of benchmark datasets and evaluation metrics. Furthermore, we introduce the classification methods in FSCIL from data-based, structure-based, and optimization-based approaches and the object detection methods in FSCIL from anchor-free and anchor-based approaches. Beyond these, we illuminate several promising research directions within FSCIL that merit further investigation.
Boosting Convolutional Neural Networks with Middle Spectrum Grouped Convolution
Apr 13, 2023This paper proposes a novel module called middle spectrum grouped convolution (MSGC) for efficient deep convolutional neural networks (DCNNs) with the mechanism of grouped convolution. It explores the broad "middle spectrum" area between channel pruning and conventional grouped convolution. Compared with channel pruning, MSGC can retain most of the information from the input feature maps due to the group mechanism; compared with grouped convolution, MSGC benefits from the learnability, the core of channel pruning, for constructing its group topology, leading to better channel division. The middle spectrum area is unfolded along four dimensions: group-wise, layer-wise, sample-wise, and attention-wise, making it possible to reveal more powerful and interpretable structures. As a result, the proposed module acts as a booster that can reduce the computational cost of the host backbones for general image recognition with even improved predictive accuracy. For example, in the experiments on ImageNet dataset for image classification, MSGC can reduce the multiply-accumulates (MACs) of ResNet-18 and ResNet-50 by half but still increase the Top-1 accuracy by more than 1%. With 35% reduction of MACs, MSGC can also increase the Top-1 accuracy of the MobileNetV2 backbone. Results on MS COCO dataset for object detection show similar observations. Our code and trained models are available at https://github.com/hellozhuo/msgc.
From Local Binary Patterns to Pixel Difference Networks for Efficient Visual Representation Learning
Mar 15, 2023LBP is a successful hand-crafted feature descriptor in computer vision. However, in the deep learning era, deep neural networks, especially convolutional neural networks (CNNs) can automatically learn powerful task-aware features that are more discriminative and of higher representational capacity. To some extent, such hand-crafted features can be safely ignored when designing deep computer vision models. Nevertheless, due to LBP's preferable properties in visual representation learning, an interesting topic has arisen to explore the value of LBP in enhancing modern deep models in terms of efficiency, memory consumption, and predictive performance. In this paper, we provide a comprehensive review on such efforts which aims to incorporate the LBP mechanism into the design of CNN modules to make deep models stronger. In retrospect of what has been achieved so far, the paper discusses open challenges and directions for future research.
Boosting Binary Neural Networks via Dynamic Thresholds Learning
Nov 04, 2022



Developing lightweight Deep Convolutional Neural Networks (DCNNs) and Vision Transformers (ViTs) has become one of the focuses in vision research since the low computational cost is essential for deploying vision models on edge devices. Recently, researchers have explored highly computational efficient Binary Neural Networks (BNNs) by binarizing weights and activations of Full-precision Neural Networks. However, the binarization process leads to an enormous accuracy gap between BNN and its full-precision version. One of the primary reasons is that the Sign function with predefined or learned static thresholds limits the representation capacity of binarized architectures since single-threshold binarization fails to utilize activation distributions. To overcome this issue, we introduce the statistics of channel information into explicit thresholds learning for the Sign Function dubbed DySign to generate various thresholds based on input distribution. Our DySign is a straightforward method to reduce information loss and boost the representative capacity of BNNs, which can be flexibly applied to both DCNNs and ViTs (i.e., DyBCNN and DyBinaryCCT) to achieve promising performance improvement. As shown in our extensive experiments. For DCNNs, DyBCNNs based on two backbones (MobileNetV1 and ResNet18) achieve 71.2% and 67.4% top1-accuracy on ImageNet dataset, outperforming baselines by a large margin (i.e., 1.8% and 1.5% respectively). For ViTs, DyBinaryCCT presents the superiority of the convolutional embedding layer in fully binarized ViTs and achieves 56.1% on the ImageNet dataset, which is nearly 9% higher than the baseline.
SVNet: Where SO(3) Equivariance Meets Binarization on Point Cloud Representation
Sep 20, 2022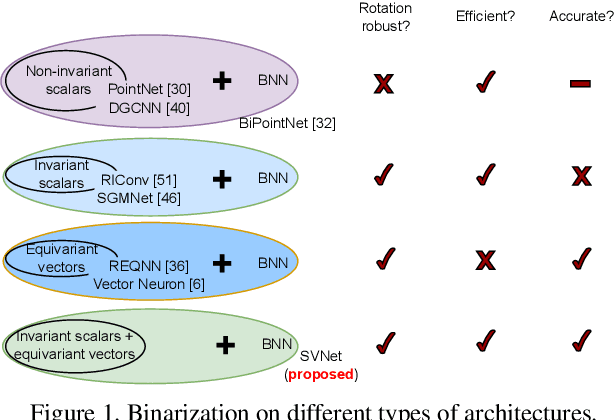


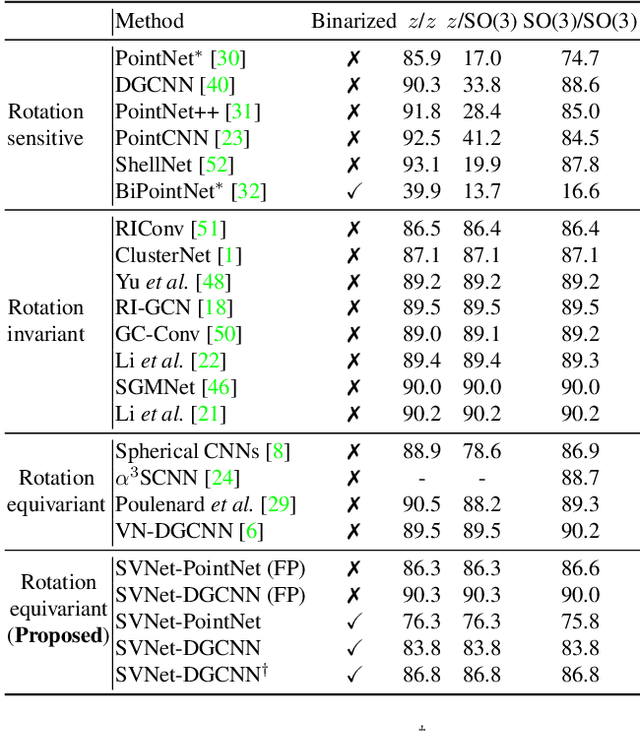
Efficiency and robustness are increasingly needed for applications on 3D point clouds, with the ubiquitous use of edge devices in scenarios like autonomous driving and robotics, which often demand real-time and reliable responses. The paper tackles the challenge by designing a general framework to construct 3D learning architectures with SO(3) equivariance and network binarization. However, a naive combination of equivariant networks and binarization either causes sub-optimal computational efficiency or geometric ambiguity. We propose to locate both scalar and vector features in our networks to avoid both cases. Precisely, the presence of scalar features makes the major part of the network binarizable, while vector features serve to retain rich structural information and ensure SO(3) equivariance. The proposed approach can be applied to general backbones like PointNet and DGCNN. Meanwhile, experiments on ModelNet40, ShapeNet, and the real-world dataset ScanObjectNN, demonstrated that the method achieves a great trade-off between efficiency, rotation robustness, and accuracy. The codes are available at https://github.com/zhuoinoulu/svnet.
Deep Learning for Visual Speech Analysis: A Survey
May 22, 2022
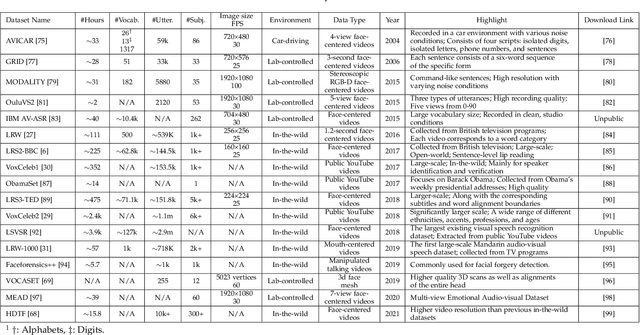
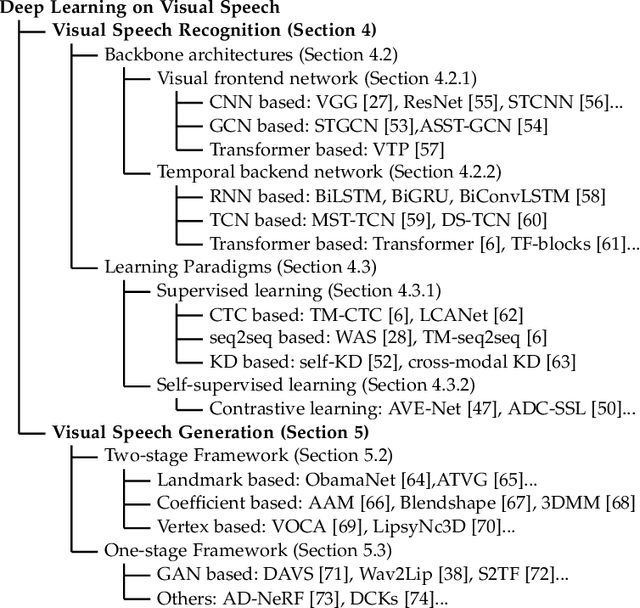

Visual speech, referring to the visual domain of speech, has attracted increasing attention due to its wide applications, such as public security, medical treatment, military defense, and film entertainment. As a powerful AI strategy, deep learning techniques have extensively promoted the development of visual speech learning. Over the past five years, numerous deep learning based methods have been proposed to address various problems in this area, especially automatic visual speech recognition and generation. To push forward future research on visual speech, this paper aims to present a comprehensive review of recent progress in deep learning methods on visual speech analysis. We cover different aspects of visual speech, including fundamental problems, challenges, benchmark datasets, a taxonomy of existing methods, and state-of-the-art performance. Besides, we also identify gaps in current research and discuss inspiring future research directions.
Challenges of Artificial Intelligence -- From Machine Learning and Computer Vision to Emotional Intelligence
Jan 05, 2022


Artificial intelligence (AI) has become a part of everyday conversation and our lives. It is considered as the new electricity that is revolutionizing the world. AI is heavily invested in both industry and academy. However, there is also a lot of hype in the current AI debate. AI based on so-called deep learning has achieved impressive results in many problems, but its limits are already visible. AI has been under research since the 1940s, and the industry has seen many ups and downs due to over-expectations and related disappointments that have followed. The purpose of this book is to give a realistic picture of AI, its history, its potential and limitations. We believe that AI is a helper, not a ruler of humans. We begin by describing what AI is and how it has evolved over the decades. After fundamentals, we explain the importance of massive data for the current mainstream of artificial intelligence. The most common representations for AI, methods, and machine learning are covered. In addition, the main application areas are introduced. Computer vision has been central to the development of AI. The book provides a general introduction to computer vision, and includes an exposure to the results and applications of our own research. Emotions are central to human intelligence, but little use has been made in AI. We present the basics of emotional intelligence and our own research on the topic. We discuss super-intelligence that transcends human understanding, explaining why such achievement seems impossible on the basis of present knowledge,and how AI could be improved. Finally, a summary is made of the current state of AI and what to do in the future. In the appendix, we look at the development of AI education, especially from the perspective of contents at our own university.
Dynamic Binary Neural Network by learning channel-wise thresholds
Oct 08, 2021
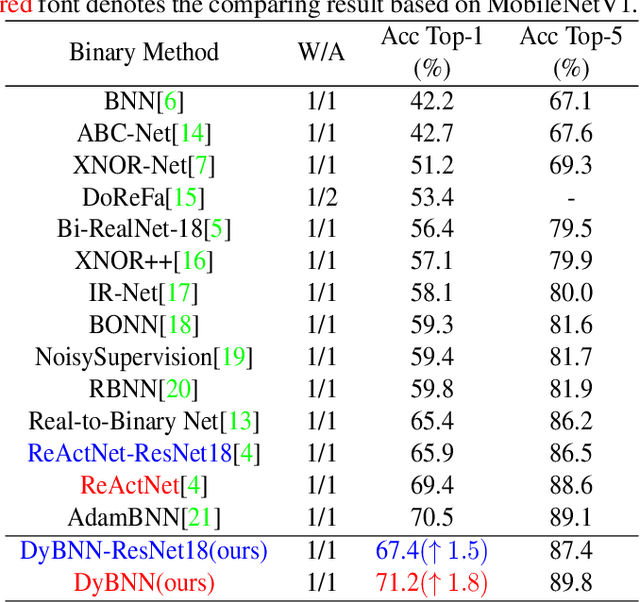
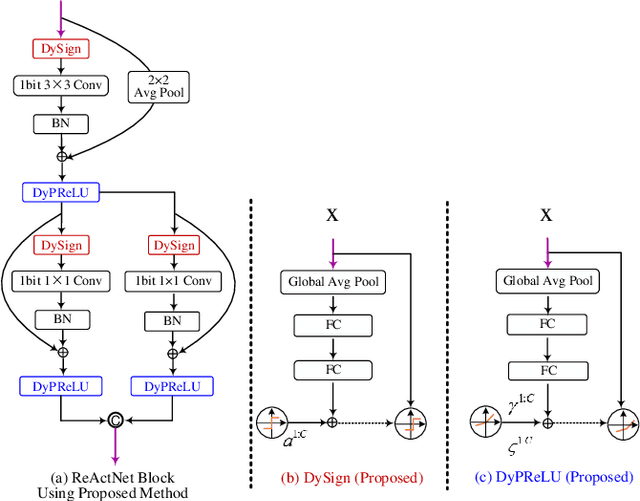
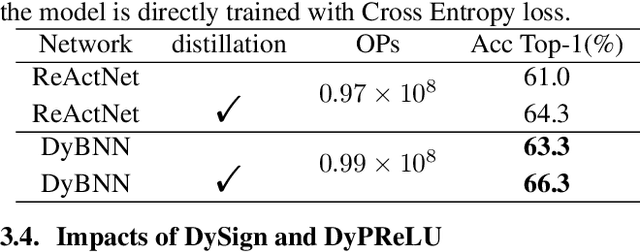
Binary neural networks (BNNs) constrain weights and activations to +1 or -1 with limited storage and computational cost, which is hardware-friendly for portable devices. Recently, BNNs have achieved remarkable progress and been adopted into various fields. However, the performance of BNNs is sensitive to activation distribution. The existing BNNs utilized the Sign function with predefined or learned static thresholds to binarize activations. This process limits representation capacity of BNNs since different samples may adapt to unequal thresholds. To address this problem, we propose a dynamic BNN (DyBNN) incorporating dynamic learnable channel-wise thresholds of Sign function and shift parameters of PReLU. The method aggregates the global information into the hyper function and effectively increases the feature expression ability. The experimental results prove that our method is an effective and straightforward way to reduce information loss and enhance performance of BNNs. The DyBNN based on two backbones of ReActNet (MobileNetV1 and ResNet18) achieve 71.2% and 67.4% top1-accuracy on ImageNet dataset, outperforming baselines by a large margin (i.e., 1.8% and 1.5% respectively).