 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Binary Neural Network by learning channel-wise thresholds
Paper and Code
Oct 08, 2021
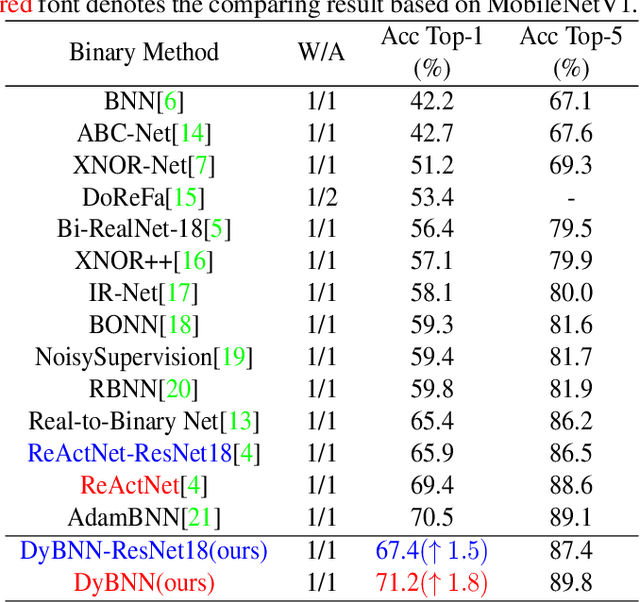
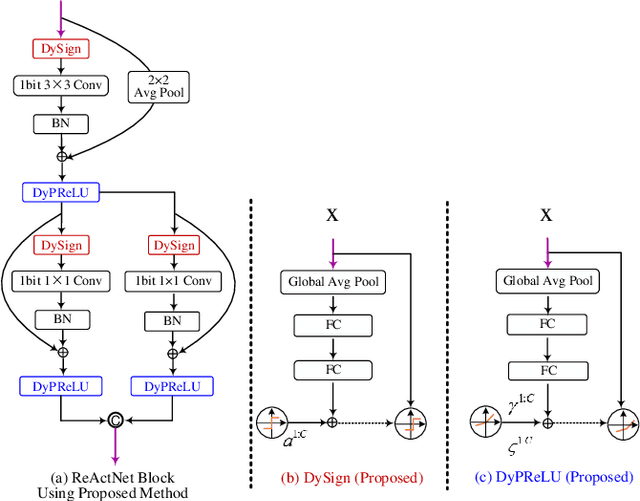
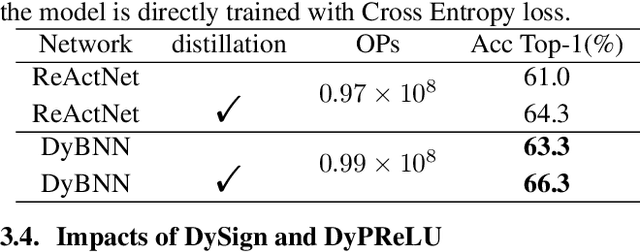
Binary neural networks (BNNs) constrain weights and activations to +1 or -1 with limited storage and computational cost, which is hardware-friendly for portable devices. Recently, BNNs have achieved remarkable progress and been adopted into various fields. However, the performance of BNNs is sensitive to activation distribution. The existing BNNs utilized the Sign function with predefined or learned static thresholds to binarize activations. This process limits representation capacity of BNNs since different samples may adapt to unequal thresholds. To address this problem, we propose a dynamic BNN (DyBNN) incorporating dynamic learnable channel-wise thresholds of Sign function and shift parameters of PReLU. The method aggregates the global information into the hyper function and effectively increases the feature expression ability. The experimental results prove that our method is an effective and straightforward way to reduce information loss and enhance performance of BNNs. The DyBNN based on two backbones of ReActNet (MobileNetV1 and ResNet18) achieve 71.2% and 67.4% top1-accuracy on ImageNet dataset, outperforming baselines by a large margin (i.e., 1.8% and 1.5% respectively).