 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLight-ResKAN: A Parameter-Sharing Lightweight KAN with Gram Polynomials for Efficient SAR Image Recognition
Apr 02, 2026Synthetic Aperture Radar (SAR) image recognition is vital for disaster monitoring, military reconnaissance, and ocean observation. However, large SAR image sizes hinder deep learning deployment on resource-constrained edge devices, and existing lightweight models struggle to balance high-precision feature extraction with low computational requirements. The emerging Kolmogorov-Arnold Network (KAN) enhances fitting by replacing fixed activations with learnable ones, reducing parameters and computation. Inspired by KAN, we propose Light-ResKAN to achieve a better balance between precision and efficiency. First, Light-ResKAN modifies ResNet by replacing convolutions with KAN convolutions, enabling adaptive feature extraction for SAR images. Second, we use Gram Polynomials as activations, which are well-suited for SAR data to capture complex non-linear relationships. Third, we employ a parameter-sharing strategy: each kernel shares parameters per channel, preserving unique features while reducing parameters and FLOPs. Our model achieves 99.09%, 93.01%, and 97.26% accuracy on MSTAR, FUSAR-Ship, and SAR-ACD datasets, respectively. Experiments on MSTAR resized to $1024 \times 1024$ show that compared to VGG16, our model reduces FLOPs by $82.90 \times$ and parameters by $163.78 \times$. This work establishes an efficient solution for edge SAR image recognition.
Rapid Salient Object Detection with Difference Convolutional Neural Networks
Jul 01, 2025This paper addresses the challenge of deploying salient object detection (SOD) on resource-constrained devices with real-time performance. While recent advances in deep neural networks have improved SOD, existing top-leading models are computationally expensive. We propose an efficient network design that combines traditional wisdom on SOD and the representation power of modern CNNs. Like biologically-inspired classical SOD methods relying on computing contrast cues to determine saliency of image regions, our model leverages Pixel Difference Convolutions (PDCs) to encode the feature contrasts. Differently, PDCs are incorporated in a CNN architecture so that the valuable contrast cues are extracted from rich feature maps. For efficiency, we introduce a difference convolution reparameterization (DCR) strategy that embeds PDCs into standard convolutions, eliminating computation and parameters at inference. Additionally, we introduce SpatioTemporal Difference Convolution (STDC) for video SOD, enhancing the standard 3D convolution with spatiotemporal contrast capture. Our models, SDNet for image SOD and STDNet for video SOD, achieve significant improvements in efficiency-accuracy trade-offs. On a Jetson Orin device, our models with $<$ 1M parameters operate at 46 FPS and 150 FPS on streamed images and videos, surpassing the second-best lightweight models in our experiments by more than $2\times$ and $3\times$ in speed with superior accuracy. Code will be available at https://github.com/hellozhuo/stdnet.git.
Multi-Granularity Class Prototype Topology Distillation for Class-Incremental Source-Free Unsupervised Domain Adaptation
Nov 25, 2024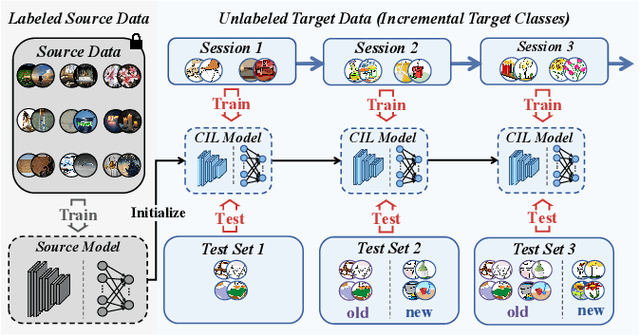

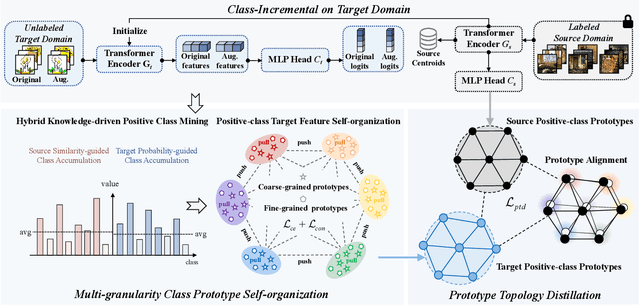

This paper explores the Class-Incremental Source-Free Unsupervised Domain Adaptation (CI-SFUDA) problem, where the unlabeled target data come incrementally without access to labeled source instances. This problem poses two challenges, the disturbances of similar source-class knowledge to target-class representation learning and the new target knowledge to old ones. To address them, we propose the Multi-Granularity Class Prototype Topology Distillation (GROTO) algorithm, which effectively transfers the source knowledge to the unlabeled class-incremental target domain. Concretely, we design the multi-granularity class prototype self-organization module and prototype topology distillation module. Firstly, the positive classes are mined by modeling two accumulation distributions. Then, we generate reliable pseudo-labels by introducing multi-granularity class prototypes, and use them to promote the positive-class target feature self-organization. Secondly, the positive-class prototypes are leveraged to construct the topological structures of source and target feature spaces. Then, we perform the topology distillation to continually mitigate the interferences of new target knowledge to old ones. Extensive experiments demonstrate that our proposed method achieves state-of-the-art performances on three public datasets.
Generating High-quality Symbolic Music Using Fine-grained Discriminators
Aug 03, 2024



Existing symbolic music generation methods usually utilize discriminator to improve the quality of generated music via global perception of music. However, considering the complexity of information in music, such as rhythm and melody, a single discriminator cannot fully reflect the differences in these two primary dimensions of music. In this work, we propose to decouple the melody and rhythm from music, and design corresponding fine-grained discriminators to tackle the aforementioned issues. Specifically, equipped with a pitch augmentation strategy, the melody discriminator discerns the melody variations presented by the generated samples. By contrast, the rhythm discriminator, enhanced with bar-level relative positional encoding, focuses on the velocity of generated notes. Such a design allows the generator to be more explicitly aware of which aspects should be adjusted in the generated music, making it easier to mimic human-composed music. Experimental results on the POP909 benchmark demonstrate the favorable performance of the proposed method compared to several state-of-the-art methods in terms of both objective and subjective metrics.
Progressive Depth Decoupling and Modulating for Flexible Depth Completion
May 15, 2024Image-guided depth completion aims at generating a dense depth map from sparse LiDAR data and RGB image. Recent methods have shown promising performance by reformulating it as a classification problem with two sub-tasks: depth discretization and probability prediction. They divide the depth range into several discrete depth values as depth categories, serving as priors for scene depth distributions. However, previous depth discretization methods are easy to be impacted by depth distribution variations across different scenes, resulting in suboptimal scene depth distribution priors. To address the above problem, we propose a progressive depth decoupling and modulating network, which incrementally decouples the depth range into bins and adaptively generates multi-scale dense depth maps in multiple stages. Specifically, we first design a Bins Initializing Module (BIM) to construct the seed bins by exploring the depth distribution information within a sparse depth map, adapting variations of depth distribution. Then, we devise an incremental depth decoupling branch to progressively refine the depth distribution information from global to local. Meanwhile, an adaptive depth modulating branch is developed to progressively improve the probability representation from coarse-grained to fine-grained. And the bi-directional information interactions are proposed to strengthen the information interaction between those two branches (sub-tasks) for promoting information complementation in each branch. Further, we introduce a multi-scale supervision mechanism to learn the depth distribution information in latent features and enhance the adaptation capability across different scenes. Experimental results on public datasets demonstrate that our method outperforms the state-of-the-art methods. The code will be open-sourced at [this https URL](https://github.com/Cisse-away/PDDM).
Lightweight Pixel Difference Networks for Efficient Visual Representation Learning
Feb 01, 2024



Recently, there have been tremendous efforts in developing lightweight Deep Neural Networks (DNNs) with satisfactory accuracy, which can enable the ubiquitous deployment of DNNs in edge devices. The core challenge of developing compact and efficient DNNs lies in how to balance the competing goals of achieving high accuracy and high efficiency. In this paper we propose two novel types of convolutions, dubbed \emph{Pixel Difference Convolution (PDC) and Binary PDC (Bi-PDC)} which enjoy the following benefits: capturing higher-order local differential information, computationally efficient, and able to be integrated with existing DNNs. With PDC and Bi-PDC, we further present two lightweight deep networks named \emph{Pixel Difference Networks (PiDiNet)} and \emph{Binary PiDiNet (Bi-PiDiNet)} respectively to learn highly efficient yet more accurate representations for visual tasks including edge detection and object recognition. Extensive experiments on popular datasets (BSDS500, ImageNet, LFW, YTF, \emph{etc.}) show that PiDiNet and Bi-PiDiNet achieve the best accuracy-efficiency trade-off. For edge detection, PiDiNet is the first network that can be trained without ImageNet, and can achieve the human-level performance on BSDS500 at 100 FPS and with $<$1M parameters. For object recognition, among existing Binary DNNs, Bi-PiDiNet achieves the best accuracy and a nearly $2\times$ reduction of computational cost on ResNet18. Code available at \href{https://github.com/hellozhuo/pidinet}{https://github.com/hellozhuo/pidinet}.
ARBiBench: Benchmarking Adversarial Robustness of Binarized Neural Networks
Dec 21, 2023



Network binarization exhibits great potential for deployment on resource-constrained devices due to its low computational cost. Despite the critical importance, the security of binarized neural networks (BNNs) is rarely investigated. In this paper, we present ARBiBench, a comprehensive benchmark to evaluate the robustness of BNNs against adversarial perturbations on CIFAR-10 and ImageNet. We first evaluate the robustness of seven influential BNNs on various white-box and black-box attacks. The results reveal that 1) The adversarial robustness of BNNs exhibits a completely opposite performance on the two datasets under white-box attacks. 2) BNNs consistently exhibit better adversarial robustness under black-box attacks. 3) Different BNNs exhibit certain similarities in their robustness performance. Then, we conduct experiments to analyze the adversarial robustness of BNNs based on these insights. Our research contributes to inspiring future research on enhancing the robustness of BNNs and advancing their application in real-world scenarios.
Animal3D: A Comprehensive Dataset of 3D Animal Pose and Shape
Aug 22, 2023



Accurately estimating the 3D pose and shape is an essential step towards understanding animal behavior, and can potentially benefit many downstream applications, such as wildlife conservation. However, research in this area is held back by the lack of a comprehensive and diverse dataset with high-quality 3D pose and shape annotations. In this paper, we propose Animal3D, the first comprehensive dataset for mammal animal 3D pose and shape estimation. Animal3D consists of 3379 images collected from 40 mammal species, high-quality annotations of 26 keypoints, and importantly the pose and shape parameters of the SMAL model. All annotations were labeled and checked manually in a multi-stage process to ensure highest quality results. Based on the Animal3D dataset, we benchmark representative shape and pose estimation models at: (1) supervised learning from only the Animal3D data, (2) synthetic to real transfer from synthetically generated images, and (3) fine-tuning human pose and shape estimation models. Our experimental results demonstrate that predicting the 3D shape and pose of animals across species remains a very challenging task, despite significant advances in human pose estimation. Our results further demonstrate that synthetic pre-training is a viable strategy to boost the model performance. Overall, Animal3D opens new directions for facilitating future research in animal 3D pose and shape estimation, and is publicly available.
Boosting Convolutional Neural Networks with Middle Spectrum Grouped Convolution
Apr 13, 2023This paper proposes a novel module called middle spectrum grouped convolution (MSGC) for efficient deep convolutional neural networks (DCNNs) with the mechanism of grouped convolution. It explores the broad "middle spectrum" area between channel pruning and conventional grouped convolution. Compared with channel pruning, MSGC can retain most of the information from the input feature maps due to the group mechanism; compared with grouped convolution, MSGC benefits from the learnability, the core of channel pruning, for constructing its group topology, leading to better channel division. The middle spectrum area is unfolded along four dimensions: group-wise, layer-wise, sample-wise, and attention-wise, making it possible to reveal more powerful and interpretable structures. As a result, the proposed module acts as a booster that can reduce the computational cost of the host backbones for general image recognition with even improved predictive accuracy. For example, in the experiments on ImageNet dataset for image classification, MSGC can reduce the multiply-accumulates (MACs) of ResNet-18 and ResNet-50 by half but still increase the Top-1 accuracy by more than 1%. With 35% reduction of MACs, MSGC can also increase the Top-1 accuracy of the MobileNetV2 backbone. Results on MS COCO dataset for object detection show similar observations. Our code and trained models are available at https://github.com/hellozhuo/msgc.
PhysFormer++: Facial Video-based Physiological Measurement with SlowFast Temporal Difference Transformer
Feb 07, 2023Remote photoplethysmography (rPPG), which aims at measuring heart activities and physiological signals from facial video without any contact, has great potential in many applications (e.g., remote healthcare and affective computing). Recent deep learning approaches focus on mining subtle rPPG clues using convolutional neural networks with limited spatio-temporal receptive fields, which neglect the long-range spatio-temporal perception and interaction for rPPG modeling. In this paper, we propose two end-to-end video transformer based architectures, namely PhysFormer and PhysFormer++, to adaptively aggregate both local and global spatio-temporal features for rPPG representation enhancement. As key modules in PhysFormer, the temporal difference transformers first enhance the quasi-periodic rPPG features with temporal difference guided global attention, and then refine the local spatio-temporal representation against interference. To better exploit the temporal contextual and periodic rPPG clues, we also extend the PhysFormer to the two-pathway SlowFast based PhysFormer++ with temporal difference periodic and cross-attention transformers. Furthermore, we propose the label distribution learning and a curriculum learning inspired dynamic constraint in frequency domain, which provide elaborate supervisions for PhysFormer and PhysFormer++ and alleviate overfitting. Comprehensive experiments are performed on four benchmark datasets to show our superior performance on both intra- and cross-dataset testings. Unlike most transformer networks needed pretraining from large-scale datasets, the proposed PhysFormer family can be easily trained from scratch on rPPG datasets, which makes it promising as a novel transformer baseline for the rPPG community.