 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Resolution Alignment for Voxel Sparsity in Camera-Based 3D Semantic Scene Completion
Feb 03, 2026Camera-based 3D semantic scene completion (SSC) offers a cost-effective solution for assessing the geometric occupancy and semantic labels of each voxel in the surrounding 3D scene with image inputs, providing a voxel-level scene perception foundation for the perception-prediction-planning autonomous driving systems. Although significant progress has been made in existing methods, their optimization rely solely on the supervision from voxel labels and face the challenge of voxel sparsity as a large portion of voxels in autonomous driving scenarios are empty, which limits both optimization efficiency and model performance. To address this issue, we propose a \textit{Multi-Resolution Alignment (MRA)} approach to mitigate voxel sparsity in camera-based 3D semantic scene completion, which exploits the scene and instance level alignment across multi-resolution 3D features as auxiliary supervision. Specifically, we first propose the Multi-resolution View Transformer module, which projects 2D image features into multi-resolution 3D features and aligns them at the scene level through fusing discriminative seed features. Furthermore, we design the Cubic Semantic Anisotropy module to identify the instance-level semantic significance of each voxel, accounting for the semantic differences of a specific voxel against its neighboring voxels within a cubic area. Finally, we devise a Critical Distribution Alignment module, which selects critical voxels as instance-level anchors with the guidance of cubic semantic anisotropy, and applies a circulated loss for auxiliary supervision on the critical feature distribution consistency across different resolutions. The code is available at https://github.com/PKU-ICST-MIPL/MRA_TIP.
CausalFSFG: Rethinking Few-Shot Fine-Grained Visual Categorization from Causal Perspective
Dec 25, 2025Few-shot fine-grained visual categorization (FS-FGVC) focuses on identifying various subcategories within a common superclass given just one or few support examples. Most existing methods aim to boost classification accuracy by enriching the extracted features with discriminative part-level details. However, they often overlook the fact that the set of support samples acts as a confounding variable, which hampers the FS-FGVC performance by introducing biased data distribution and misguiding the extraction of discriminative features. To address this issue, we propose a new causal FS-FGVC (CausalFSFG) approach inspired by causal inference for addressing biased data distributions through causal intervention. Specifically, based on the structural causal model (SCM), we argue that FS-FGVC infers the subcategories (i.e., effect) from the inputs (i.e., cause), whereas both the few-shot condition disturbance and the inherent fine-grained nature (i.e., large intra-class variance and small inter-class variance) lead to unobservable variables that bring spurious correlations, compromising the final classification performance. To further eliminate the spurious correlations, our CausalFSFG approach incorporates two key components: (1) Interventional multi-scale encoder (IMSE) conducts sample-level interventions, (2) Interventional masked feature reconstruction (IMFR) conducts feature-level interventions, which together reveal real causalities from inputs to subcategories. Extensive experiments and thorough analyses on the widely-used public datasets, including CUB-200-2011, Stanford Dogs, and Stanford Cars, demonstrate that our CausalFSFG achieves new state-of-the-art performance. The code is available at https://github.com/PKU-ICST-MIPL/CausalFSFG_TMM.
TAT: Task-Adaptive Transformer for All-in-One Medical Image Restoration
Dec 16, 2025Medical image restoration (MedIR) aims to recover high-quality medical images from their low-quality counterparts. Recent advancements in MedIR have focused on All-in-One models capable of simultaneously addressing multiple different MedIR tasks. However, due to significant differences in both modality and degradation types, using a shared model for these diverse tasks requires careful consideration of two critical inter-task relationships: task interference, which occurs when conflicting gradient update directions arise across tasks on the same parameter, and task imbalance, which refers to uneven optimization caused by varying learning difficulties inherent to each task. To address these challenges, we propose a task-adaptive Transformer (TAT), a novel framework that dynamically adapts to different tasks through two key innovations. First, a task-adaptive weight generation strategy is introduced to mitigate task interference by generating task-specific weight parameters for each task, thereby eliminating potential gradient conflicts on shared weight parameters. Second, a task-adaptive loss balancing strategy is introduced to dynamically adjust loss weights based on task-specific learning difficulties, preventing task domination or undertraining. Extensive experiments demonstrate that our proposed TAT achieves state-of-the-art performance in three MedIR tasks--PET synthesis, CT denoising, and MRI super-resolution--both in task-specific and All-in-One settings. Code is available at https://github.com/Yaziwel/TAT.
HD$^2$-SSC: High-Dimension High-Density Semantic Scene Completion for Autonomous Driving
Nov 13, 2025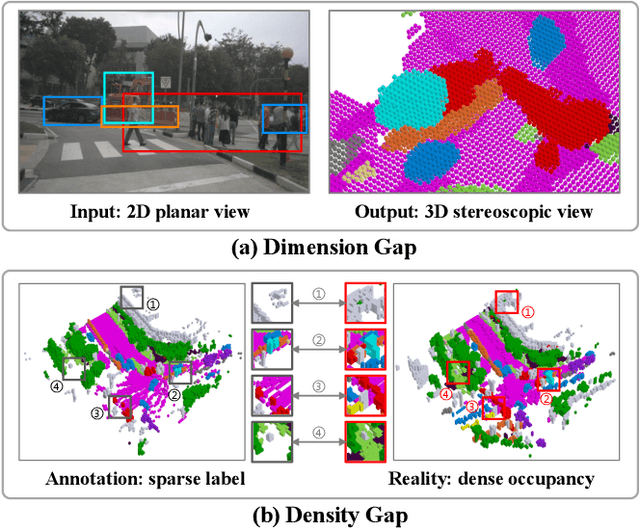
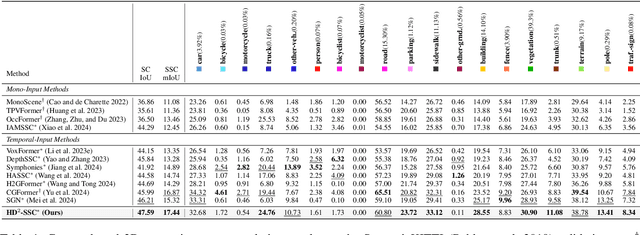
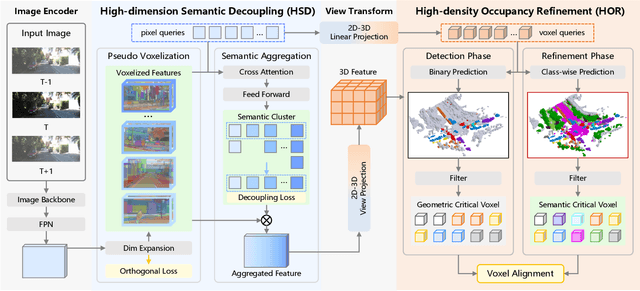
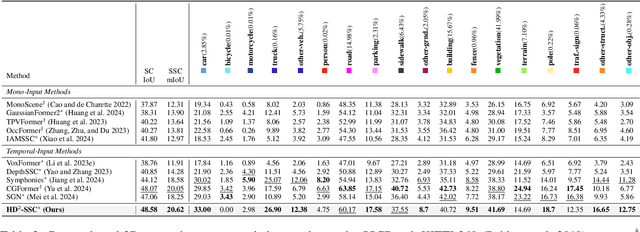
Camera-based 3D semantic scene completion (SSC) plays a crucial role in autonomous driving, enabling voxelized 3D scene understanding for effective scene perception and decision-making. Existing SSC methods have shown efficacy in improving 3D scene representations, but suffer from the inherent input-output dimension gap and annotation-reality density gap, where the 2D planner view from input images with sparse annotated labels leads to inferior prediction of real-world dense occupancy with a 3D stereoscopic view. In light of this, we propose the corresponding High-Dimension High-Density Semantic Scene Completion (HD$^2$-SSC) framework with expanded pixel semantics and refined voxel occupancies. To bridge the dimension gap, a High-dimension Semantic Decoupling module is designed to expand 2D image features along a pseudo third dimension, decoupling coarse pixel semantics from occlusions, and then identify focal regions with fine semantics to enrich image features. To mitigate the density gap, a High-density Occupancy Refinement module is devised with a "detect-and-refine" architecture to leverage contextual geometric and semantic structures for enhanced semantic density with the completion of missing voxels and correction of erroneous ones. Extensive experiments and analyses on the SemanticKITTI and SSCBench-KITTI-360 datasets validate the effectiveness of our HD$^2$-SSC framework.
FEAT: Full-Dimensional Efficient Attention Transformer for Medical Video Generation
Jun 05, 2025Synthesizing high-quality dynamic medical videos remains a significant challenge due to the need for modeling both spatial consistency and temporal dynamics. Existing Transformer-based approaches face critical limitations, including insufficient channel interactions, high computational complexity from self-attention, and coarse denoising guidance from timestep embeddings when handling varying noise levels. In this work, we propose FEAT, a full-dimensional efficient attention Transformer, which addresses these issues through three key innovations: (1) a unified paradigm with sequential spatial-temporal-channel attention mechanisms to capture global dependencies across all dimensions, (2) a linear-complexity design for attention mechanisms in each dimension, utilizing weighted key-value attention and global channel attention, and (3) a residual value guidance module that provides fine-grained pixel-level guidance to adapt to different noise levels. We evaluate FEAT on standard benchmarks and downstream tasks, demonstrating that FEAT-S, with only 23\% of the parameters of the state-of-the-art model Endora, achieves comparable or even superior performance. Furthermore, FEAT-L surpasses all comparison methods across multiple datasets, showcasing both superior effectiveness and scalability. Code is available at https://github.com/Yaziwel/FEAT.
Restore-RWKV: Efficient and Effective Medical Image Restoration with RWKV
Jul 14, 2024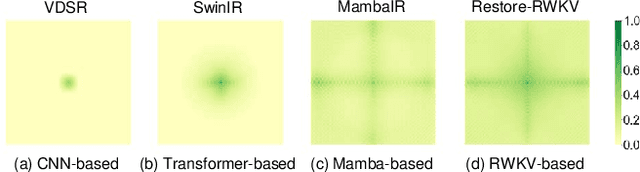



Transformers have revolutionized medical image restoration, but the quadratic complexity still poses limitations for their application to high-resolution medical images. The recent advent of RWKV in the NLP field has attracted much attention as it can process long sequences efficiently. To leverage its advanced design, we propose Restore-RWKV, the first RWKV-based model for medical image restoration. Since the original RWKV model is designed for 1D sequences, we make two necessary modifications for modeling spatial relations in 2D images. First, we present a recurrent WKV (Re-WKV) attention mechanism that captures global dependencies with linear computational complexity. Re-WKV incorporates bidirectional attention as basic for a global receptive field and recurrent attention to effectively model 2D dependencies from various scan directions. Second, we develop an omnidirectional token shift (Omni-Shift) layer that enhances local dependencies by shifting tokens from all directions and across a wide context range. These adaptations make the proposed Restore-RWKV an efficient and effective model for medical image restoration. Extensive experiments demonstrate that Restore-RWKV achieves superior performance across various medical image restoration tasks, including MRI image super-resolution, CT image denoising, PET image synthesis, and all-in-one medical image restoration. Code is available at: \href{https://github.com/Yaziwel/Restore-RWKV.git}{https://github.com/Yaziwel/Restore-RWKV}.
Region Attention Transformer for Medical Image Restoration
Jul 12, 2024



Transformer-based methods have demonstrated impressive results in medical image restoration, attributed to the multi-head self-attention (MSA) mechanism in the spatial dimension. However, the majority of existing Transformers conduct attention within fixed and coarsely partitioned regions (\text{e.g.} the entire image or fixed patches), resulting in interference from irrelevant regions and fragmentation of continuous image content. To overcome these challenges, we introduce a novel Region Attention Transformer (RAT) that utilizes a region-based multi-head self-attention mechanism (R-MSA). The R-MSA dynamically partitions the input image into non-overlapping semantic regions using the robust Segment Anything Model (SAM) and then performs self-attention within these regions. This region partitioning is more flexible and interpretable, ensuring that only pixels from similar semantic regions complement each other, thereby eliminating interference from irrelevant regions. Moreover, we introduce a focal region loss to guide our model to adaptively focus on recovering high-difficulty regions. Extensive experiments demonstrate the effectiveness of RAT in various medical image restoration tasks, including PET image synthesis, CT image denoising, and pathological image super-resolution. Code is available at \href{https://github.com/Yaziwel/Region-Attention-Transformer-for-Medical-Image-Restoration.git}{https://github.com/RAT}.
All-In-One Medical Image Restoration via Task-Adaptive Routing
May 30, 2024



Although single-task medical image restoration (MedIR) has witnessed remarkable success, the limited generalizability of these methods poses a substantial obstacle to wider application. In this paper, we focus on the task of all-in-one medical image restoration, aiming to address multiple distinct MedIR tasks with a single universal model. Nonetheless, due to significant differences between different MedIR tasks, training a universal model often encounters task interference issues, where different tasks with shared parameters may conflict with each other in the gradient update direction. This task interference leads to deviation of the model update direction from the optimal path, thereby affecting the model's performance. To tackle this issue, we propose a task-adaptive routing strategy, allowing conflicting tasks to select different network paths in spatial and channel dimensions, thereby mitigating task interference. Experimental results demonstrate that our proposed \textbf{A}ll-in-one \textbf{M}edical \textbf{I}mage \textbf{R}estoration (\textbf{AMIR}) network achieves state-of-the-art performance in three MedIR tasks: MRI super-resolution, CT denoising, and PET synthesis, both in single-task and all-in-one settings. The code and data will be available at \href{https://github.com/Yaziwel/All-In-One-Medical-Image-Restoration-via-Task-Adaptive-Routing.git}{https://github.com/Yaziwel/AMIR}.
Progressive Depth Decoupling and Modulating for Flexible Depth Completion
May 15, 2024Image-guided depth completion aims at generating a dense depth map from sparse LiDAR data and RGB image. Recent methods have shown promising performance by reformulating it as a classification problem with two sub-tasks: depth discretization and probability prediction. They divide the depth range into several discrete depth values as depth categories, serving as priors for scene depth distributions. However, previous depth discretization methods are easy to be impacted by depth distribution variations across different scenes, resulting in suboptimal scene depth distribution priors. To address the above problem, we propose a progressive depth decoupling and modulating network, which incrementally decouples the depth range into bins and adaptively generates multi-scale dense depth maps in multiple stages. Specifically, we first design a Bins Initializing Module (BIM) to construct the seed bins by exploring the depth distribution information within a sparse depth map, adapting variations of depth distribution. Then, we devise an incremental depth decoupling branch to progressively refine the depth distribution information from global to local. Meanwhile, an adaptive depth modulating branch is developed to progressively improve the probability representation from coarse-grained to fine-grained. And the bi-directional information interactions are proposed to strengthen the information interaction between those two branches (sub-tasks) for promoting information complementation in each branch. Further, we introduce a multi-scale supervision mechanism to learn the depth distribution information in latent features and enhance the adaptation capability across different scenes. Experimental results on public datasets demonstrate that our method outperforms the state-of-the-art methods. The code will be open-sourced at [this https URL](https://github.com/Cisse-away/PDDM).
DRMC: A Generalist Model with Dynamic Routing for Multi-Center PET Image Synthesis
Jul 11, 2023Multi-center positron emission tomography (PET) image synthesis aims at recovering low-dose PET images from multiple different centers. The generalizability of existing methods can still be suboptimal for a multi-center study due to domain shifts, which result from non-identical data distribution among centers with different imaging systems/protocols. While some approaches address domain shifts by training specialized models for each center, they are parameter inefficient and do not well exploit the shared knowledge across centers. To address this, we develop a generalist model that shares architecture and parameters across centers to utilize the shared knowledge. However, the generalist model can suffer from the center interference issue, \textit{i.e.} the gradient directions of different centers can be inconsistent or even opposite owing to the non-identical data distribution. To mitigate such interference, we introduce a novel dynamic routing strategy with cross-layer connections that routes data from different centers to different experts. Experiments show that our generalist model with dynamic routing (DRMC) exhibits excellent generalizability across centers. Code and data are available at: https://github.com/Yaziwel/Multi-Center-PET-Image-Synthesis.