 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSalient Object Detection in Complex Weather Conditions via Noise Indicators
Dec 11, 2025Salient object detection (SOD), a foundational task in computer vision, has advanced from single-modal to multi-modal paradigms to enhance generalization. However, most existing SOD methods assume low-noise visual conditions, overlooking the degradation of segmentation accuracy caused by weather-induced noise in real-world scenarios. In this paper, we propose a SOD framework tailored for diverse weather conditions, encompassing a specific encoder and a replaceable decoder. To enable handling of varying weather noises, we introduce a one-hot vector as a noise indicator to represent different weather types and design a Noise Indicator Fusion Module (NIFM). The NIFM takes both semantic features and the noise indicator as dual inputs and is inserted between consecutive stages of the encoder to embed weather-aware priors via adaptive feature modulation. Critically, the proposed specific encoder retains compatibility with mainstream SOD decoders. Extensive experiments are conducted on the WXSOD dataset under varying training data scales (100%, 50%, 30% of the full training set), three encoder and seven decoder configurations. Results show that the proposed SOD framework (particularly the NIFM-enhanced specific encoder) improves segmentation accuracy under complex weather conditions compared to a vanilla encoder.
VGNC: Reducing the Overfitting of Sparse-view 3DGS via Validation-guided Gaussian Number Control
Apr 20, 2025Sparse-view 3D reconstruction is a fundamental yet challenging task in practical 3D reconstruction applications. Recently, many methods based on the 3D Gaussian Splatting (3DGS) framework have been proposed to address sparse-view 3D reconstruction. Although these methods have made considerable advancements, they still show significant issues with overfitting. To reduce the overfitting, we introduce VGNC, a novel Validation-guided Gaussian Number Control (VGNC) approach based on generative novel view synthesis (NVS) models. To the best of our knowledge, this is the first attempt to alleviate the overfitting issue of sparse-view 3DGS with generative validation images. Specifically, we first introduce a validation image generation method based on a generative NVS model. We then propose a Gaussian number control strategy that utilizes generated validation images to determine the optimal Gaussian numbers, thereby reducing the issue of overfitting. We conducted detailed experiments on various sparse-view 3DGS baselines and datasets to evaluate the effectiveness of VGNC. Extensive experiments show that our approach not only reduces overfitting but also improves rendering quality on the test set while decreasing the number of Gaussian points. This reduction lowers storage demands and accelerates both training and rendering. The code will be released.
Multi-Granularity Class Prototype Topology Distillation for Class-Incremental Source-Free Unsupervised Domain Adaptation
Nov 25, 2024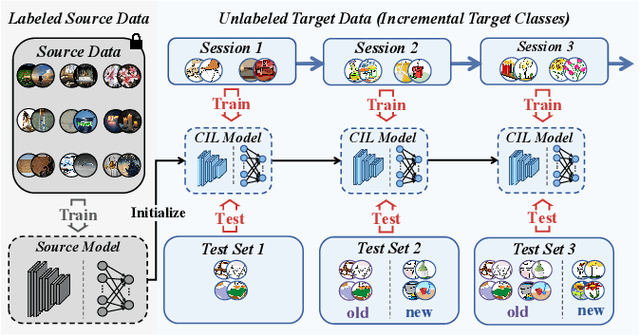

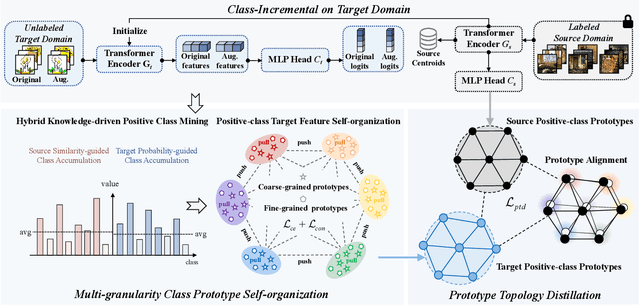

This paper explores the Class-Incremental Source-Free Unsupervised Domain Adaptation (CI-SFUDA) problem, where the unlabeled target data come incrementally without access to labeled source instances. This problem poses two challenges, the disturbances of similar source-class knowledge to target-class representation learning and the new target knowledge to old ones. To address them, we propose the Multi-Granularity Class Prototype Topology Distillation (GROTO) algorithm, which effectively transfers the source knowledge to the unlabeled class-incremental target domain. Concretely, we design the multi-granularity class prototype self-organization module and prototype topology distillation module. Firstly, the positive classes are mined by modeling two accumulation distributions. Then, we generate reliable pseudo-labels by introducing multi-granularity class prototypes, and use them to promote the positive-class target feature self-organization. Secondly, the positive-class prototypes are leveraged to construct the topological structures of source and target feature spaces. Then, we perform the topology distillation to continually mitigate the interferences of new target knowledge to old ones. Extensive experiments demonstrate that our proposed method achieves state-of-the-art performances on three public datasets.
Progressive Depth Decoupling and Modulating for Flexible Depth Completion
May 15, 2024Image-guided depth completion aims at generating a dense depth map from sparse LiDAR data and RGB image. Recent methods have shown promising performance by reformulating it as a classification problem with two sub-tasks: depth discretization and probability prediction. They divide the depth range into several discrete depth values as depth categories, serving as priors for scene depth distributions. However, previous depth discretization methods are easy to be impacted by depth distribution variations across different scenes, resulting in suboptimal scene depth distribution priors. To address the above problem, we propose a progressive depth decoupling and modulating network, which incrementally decouples the depth range into bins and adaptively generates multi-scale dense depth maps in multiple stages. Specifically, we first design a Bins Initializing Module (BIM) to construct the seed bins by exploring the depth distribution information within a sparse depth map, adapting variations of depth distribution. Then, we devise an incremental depth decoupling branch to progressively refine the depth distribution information from global to local. Meanwhile, an adaptive depth modulating branch is developed to progressively improve the probability representation from coarse-grained to fine-grained. And the bi-directional information interactions are proposed to strengthen the information interaction between those two branches (sub-tasks) for promoting information complementation in each branch. Further, we introduce a multi-scale supervision mechanism to learn the depth distribution information in latent features and enhance the adaptation capability across different scenes. Experimental results on public datasets demonstrate that our method outperforms the state-of-the-art methods. The code will be open-sourced at [this https URL](https://github.com/Cisse-away/PDDM).
Quality-aware Selective Fusion Network for V-D-T Salient Object Detection
May 13, 2024Depth images and thermal images contain the spatial geometry information and surface temperature information, which can act as complementary information for the RGB modality. However, the quality of the depth and thermal images is often unreliable in some challenging scenarios, which will result in the performance degradation of the two-modal based salient object detection (SOD). Meanwhile, some researchers pay attention to the triple-modal SOD task, where they attempt to explore the complementarity of the RGB image, the depth image, and the thermal image. However, existing triple-modal SOD methods fail to perceive the quality of depth maps and thermal images, which leads to performance degradation when dealing with scenes with low-quality depth and thermal images. Therefore, we propose a quality-aware selective fusion network (QSF-Net) to conduct VDT salient object detection, which contains three subnets including the initial feature extraction subnet, the quality-aware region selection subnet, and the region-guided selective fusion subnet. Firstly, except for extracting features, the initial feature extraction subnet can generate a preliminary prediction map from each modality via a shrinkage pyramid architecture. Then, we design the weakly-supervised quality-aware region selection subnet to generate the quality-aware maps. Concretely, we first find the high-quality and low-quality regions by using the preliminary predictions, which further constitute the pseudo label that can be used to train this subnet. Finally, the region-guided selective fusion subnet purifies the initial features under the guidance of the quality-aware maps, and then fuses the triple-modal features and refines the edge details of prediction maps through the intra-modality and inter-modality attention (IIA) module and the edge refinement (ER) module, respectively. Extensive experiments are performed on VDT-2048
SDPL: Shifting-Dense Partition Learning for UAV-View Geo-Localization
Mar 07, 2024



Cross-view geo-localization aims to match images of the same target from different platforms, e.g., drone and satellite. It is a challenging task due to the changing both appearance of targets and environmental content from different views. Existing methods mainly focus on digging more comprehensive information through feature maps segmentation, while inevitably destroy the image structure and are sensitive to the shifting and scale of the target in the query. To address the above issues, we introduce a simple yet effective part-based representation learning, called shifting-dense partition learning (SDPL). Specifically, we propose the dense partition strategy (DPS), which divides the image into multiple parts to explore contextual-information while explicitly maintain the global structure. To handle scenarios with non-centered targets, we further propose the shifting-fusion strategy, which generates multiple sets of parts in parallel based on various segmentation centers and then adaptively fuses all features to select the best partitions. Extensive experiments show that our SDPL is robust to position shifting and scale variations, and achieves competitive performance on two prevailing benchmarks, i.e., University-1652 and SUES-200.
DEFN: Dual-Encoder Fourier Group Harmonics Network for Three-Dimensional Macular Hole Reconstruction with Stochastic Retinal Defect Augmentation and Dynamic Weight Composition
Nov 01, 2023The spatial and quantitative parameters of macular holes are vital for diagnosis, surgical choices, and post-op monitoring. Macular hole diagnosis and treatment rely heavily on spatial and quantitative data, yet the scarcity of such data has impeded the progress of deep learning techniques for effective segmentation and real-time 3D reconstruction. To address this challenge, we assembled the world's largest macular hole dataset, Retinal OCTfor Macular Hole Enhancement (ROME-3914), and a Comprehensive Archive for Retinal Segmentation (CARS-30k), both expertly annotated. In addition, we developed an innovative 3D segmentation network, the Dual-Encoder FuGH Network (DEFN), which integrates three innovative modules: Fourier Group Harmonics (FuGH), Simplified 3D Spatial Attention (S3DSA) and Harmonic Squeeze-and-Excitation Module (HSE). These three modules synergistically filter noise, reduce computational complexity, emphasize detailed features, and enhance the network's representation ability. We also proposed a novel data augmentation method, Stochastic Retinal Defect Injection (SRDI), and a network optimization strategy DynamicWeightCompose (DWC), to further improve the performance of DEFN. Compared with 13 baselines, our DEFN shows the best performance. We also offer precise 3D retinal reconstruction and quantitative metrics, bringing revolutionary diagnostic and therapeutic decision-making tools for ophthalmologists, and is expected to completely reshape the diagnosis and treatment patterns of difficult-to-treat macular degeneration. The source code is publicly available at: https://github.com/IIPL-HangzhouDianUniversity/DEFN-Pytorch.
Multiple-environment Self-adaptive Network for Aerial-view Geo-localization
Apr 18, 2022

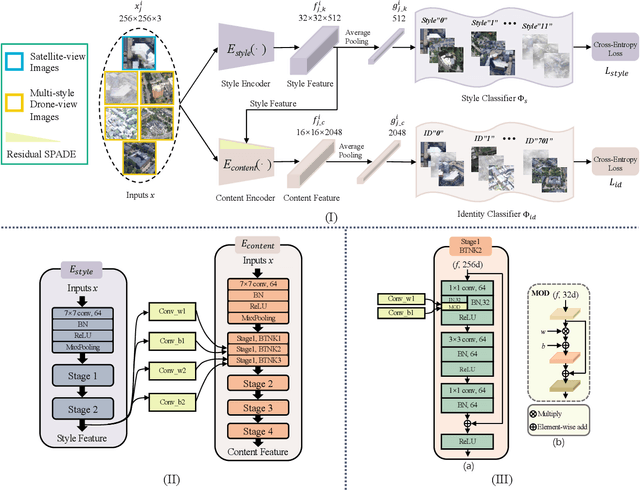

Aerial-view geo-localization tends to determine an unknown position through matching the drone-view image with the geo-tagged satellite-view image. This task is mostly regarded as an image retrieval problem. The key underpinning this task is to design a series of deep neural networks to learn discriminative image descriptors. However, existing methods meet large performance drops under realistic weather, such as rain and fog, since they do not take the domain shift between the training data and multiple test environments into consideration. To minor this domain gap, we propose a Multiple-environment Self-adaptive Network (MuSe-Net) to dynamically adjust the domain shift caused by environmental changing. In particular, MuSe-Net employs a two-branch neural network containing one multiple-environment style extraction network and one self-adaptive feature extraction network. As the name implies, the multiple-environment style extraction network is to extract the environment-related style information, while the self-adaptive feature extraction network utilizes an adaptive modulation module to dynamically minimize the environment-related style gap. Extensive experiments on two widely-used benchmarks, i.e., University-1652 and CVUSA, demonstrate that the proposed MuSe-Net achieves a competitive result for geo-localization in multiple environments. Furthermore, we observe that the proposed method also shows great potential to the unseen extreme weather, such as mixing the fog, rain and snow.
Image Classification base on PCA of Multi-view Deep Representation
Mar 12, 2019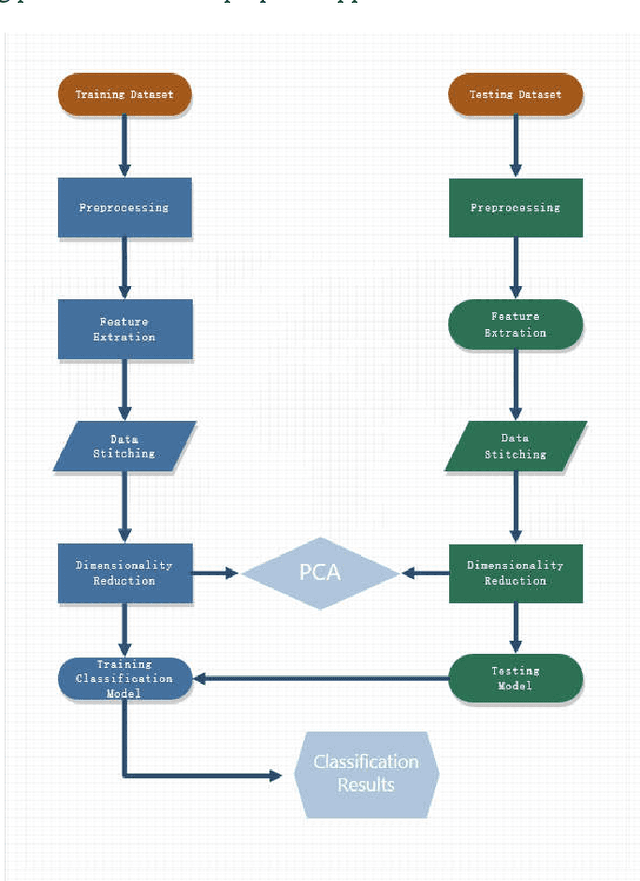

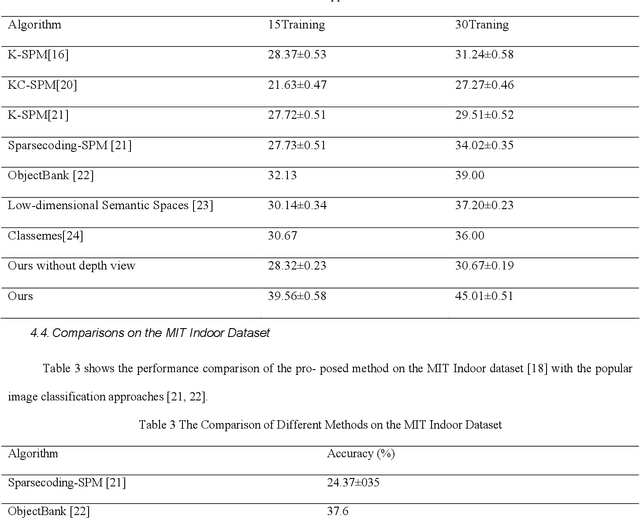
In the age of information explosion, image classification is the key technology of dealing with and organizing a large number of image data. Currently, the classical image classification algorithms are mostly based on RGB images or grayscale images, and fail to make good use of the depth information about objects or scenes. The depth information in the images has a strong complementary effect, which can enhance the classification accuracy significantly. In this paper, we propose an image classification technology using principal component analysis based on multi-view depth characters. In detail, firstly, the depth image of the original image is estimated; secondly, depth characters are extracted from the RGB views and the depth view separately, and then the reducing dimension operation through the PCA is implemented. Eventually, the SVM is applied to image classification. The experimental results show that the method has good performance.