 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMouseGPT: A Large-scale Vision-Language Model for Mouse Behavior Analysis
Mar 13, 2025Analyzing animal behavior is crucial in advancing neuroscience, yet quantifying and deciphering its intricate dynamics remains a significant challenge. Traditional machine vision approaches, despite their ability to detect spontaneous behaviors, fall short due to limited interpretability and reliance on manual labeling, which restricts the exploration of the full behavioral spectrum. Here, we introduce MouseGPT, a Vision-Language Model (VLM) that integrates visual cues with natural language to revolutionize mouse behavior analysis. Built upon our first-of-its-kind dataset - incorporating pose dynamics and open-vocabulary behavioral annotations across over 42 million frames of diverse psychiatric conditions - MouseGPT provides a novel, context-rich method for comprehensive behavior interpretation. Our holistic analysis framework enables detailed behavior profiling, clustering, and novel behavior discovery, offering deep insights without the need for labor - intensive manual annotation. Evaluations reveal that MouseGPT surpasses existing models in precision, adaptability, and descriptive richness, positioning it as a transformative tool for ethology and for unraveling complex behavioral dynamics in animal models.
DEFN: Dual-Encoder Fourier Group Harmonics Network for Three-Dimensional Macular Hole Reconstruction with Stochastic Retinal Defect Augmentation and Dynamic Weight Composition
Nov 01, 2023The spatial and quantitative parameters of macular holes are vital for diagnosis, surgical choices, and post-op monitoring. Macular hole diagnosis and treatment rely heavily on spatial and quantitative data, yet the scarcity of such data has impeded the progress of deep learning techniques for effective segmentation and real-time 3D reconstruction. To address this challenge, we assembled the world's largest macular hole dataset, Retinal OCTfor Macular Hole Enhancement (ROME-3914), and a Comprehensive Archive for Retinal Segmentation (CARS-30k), both expertly annotated. In addition, we developed an innovative 3D segmentation network, the Dual-Encoder FuGH Network (DEFN), which integrates three innovative modules: Fourier Group Harmonics (FuGH), Simplified 3D Spatial Attention (S3DSA) and Harmonic Squeeze-and-Excitation Module (HSE). These three modules synergistically filter noise, reduce computational complexity, emphasize detailed features, and enhance the network's representation ability. We also proposed a novel data augmentation method, Stochastic Retinal Defect Injection (SRDI), and a network optimization strategy DynamicWeightCompose (DWC), to further improve the performance of DEFN. Compared with 13 baselines, our DEFN shows the best performance. We also offer precise 3D retinal reconstruction and quantitative metrics, bringing revolutionary diagnostic and therapeutic decision-making tools for ophthalmologists, and is expected to completely reshape the diagnosis and treatment patterns of difficult-to-treat macular degeneration. The source code is publicly available at: https://github.com/IIPL-HangzhouDianUniversity/DEFN-Pytorch.
Detection of Information Hiding at Anti-Copying 2D Barcodes
Mar 20, 2020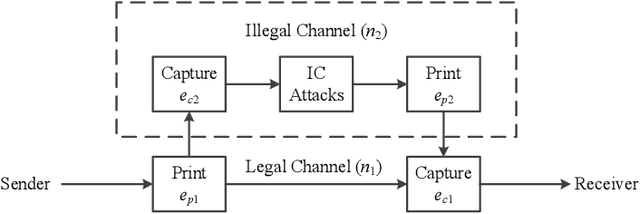
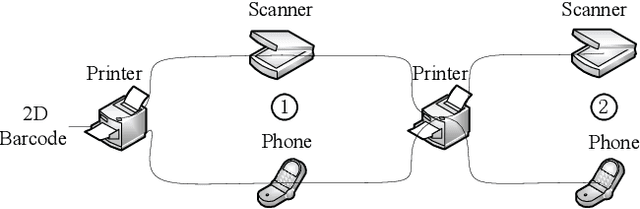
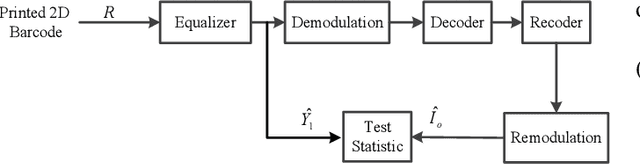
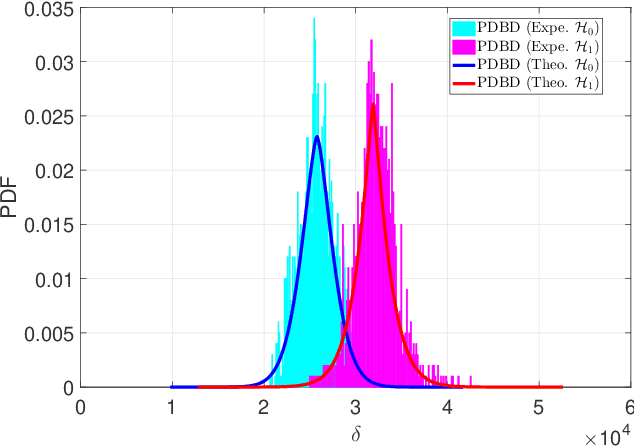
This paper concerns the problem of detecting the use of information hiding at anti-copying 2D barcodes. Prior hidden information detection schemes are either heuristicbased or Machine Learning (ML) based. The key limitation of prior heuristics-based schemes is that they do not answer the fundamental question of why the information hidden at a 2D barcode can be detected. The key limitation of prior MLbased information schemes is that they lack robustness because a printed 2D barcode is very much environmentally dependent, and thus an information hiding detection scheme trained in one environment often does not work well in another environment. In this paper, we propose two hidden information detection schemes at the existing anti-copying 2D barcodes. The first scheme is to directly use the pixel distance to detect the use of an information hiding scheme in a 2D barcode, referred as to the Pixel Distance Based Detection (PDBD) scheme. The second scheme is first to calculate the variance of the raw signal and the covariance between the recovered signal and the raw signal, and then based on the variance results, detects the use of information hiding scheme in a 2D barcode, referred as to the Pixel Variance Based Detection (PVBD) scheme. Moreover, we design advanced IC attacks to evaluate the security of two existing anti-copying 2D barcodes. We implemented our schemes and conducted extensive performance comparison between our schemes and prior schemes under different capturing devices, such as a scanner and a camera phone. Our experimental results show that the PVBD scheme can correctly detect the existence of the hidden information at both the 2LQR code and the LCAC 2D barcode. Moreover, the probability of successfully attacking of our IC attacks achieves 0.6538 for the 2LQR code and 1 for the LCAC 2D barcode.
Image Classification base on PCA of Multi-view Deep Representation
Mar 12, 2019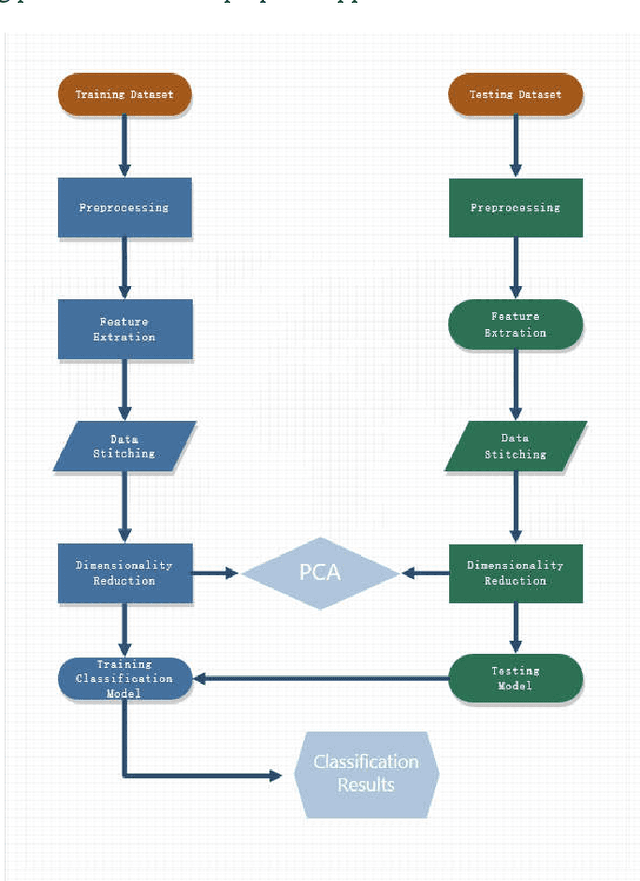

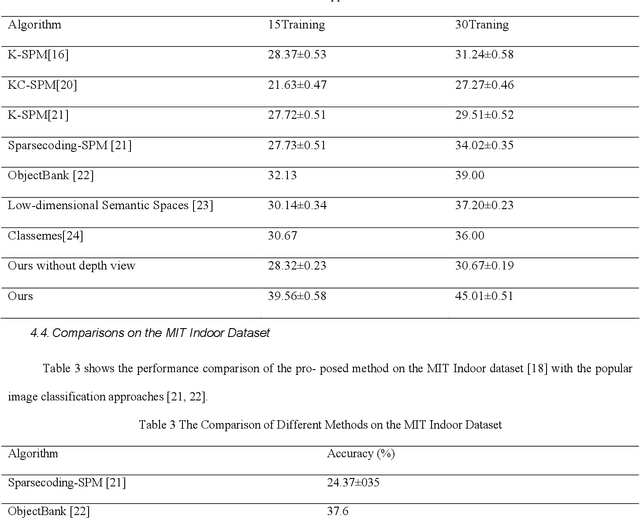
In the age of information explosion, image classification is the key technology of dealing with and organizing a large number of image data. Currently, the classical image classification algorithms are mostly based on RGB images or grayscale images, and fail to make good use of the depth information about objects or scenes. The depth information in the images has a strong complementary effect, which can enhance the classification accuracy significantly. In this paper, we propose an image classification technology using principal component analysis based on multi-view depth characters. In detail, firstly, the depth image of the original image is estimated; secondly, depth characters are extracted from the RGB views and the depth view separately, and then the reducing dimension operation through the PCA is implemented. Eventually, the SVM is applied to image classification. The experimental results show that the method has good performance.