 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlind Super-Resolution via Meta-learning and Markov Chain Monte Carlo Simulation
Jun 13, 2024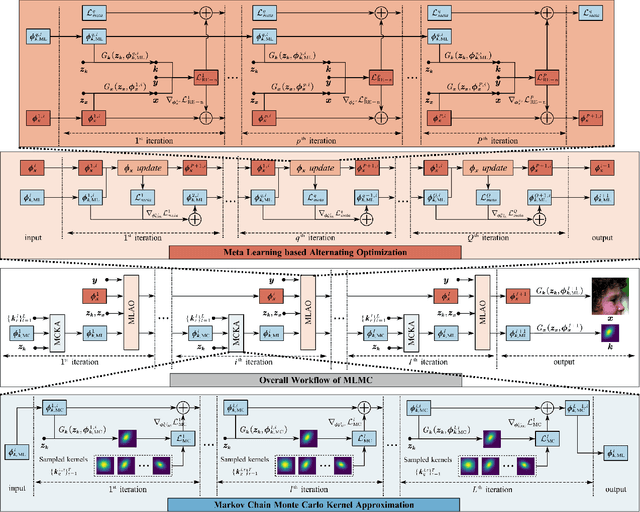
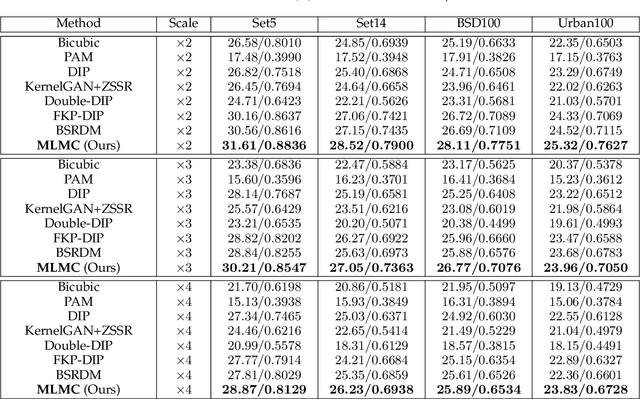
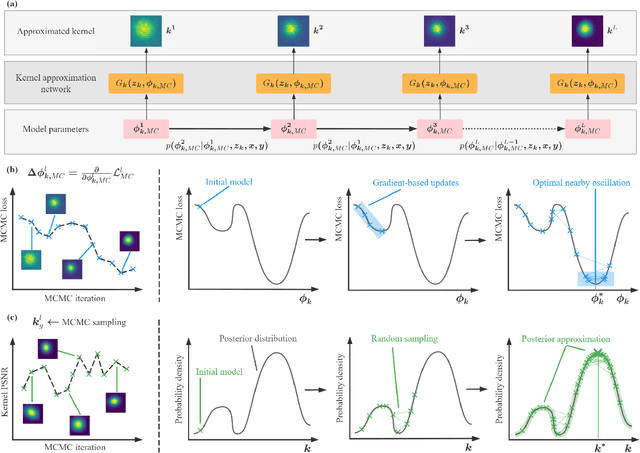
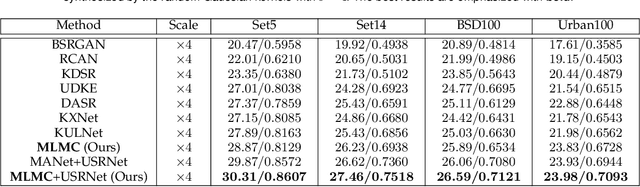
Learning-based approaches have witnessed great successes in blind single image super-resolution (SISR) tasks, however, handcrafted kernel priors and learning based kernel priors are typically required. In this paper, we propose a Meta-learning and Markov Chain Monte Carlo (MCMC) based SISR approach to learn kernel priors from organized randomness. In concrete, a lightweight network is adopted as kernel generator, and is optimized via learning from the MCMC simulation on random Gaussian distributions. This procedure provides an approximation for the rational blur kernel, and introduces a network-level Langevin dynamics into SISR optimization processes, which contributes to preventing bad local optimal solutions for kernel estimation. Meanwhile, a meta-learning-based alternating optimization procedure is proposed to optimize the kernel generator and image restorer, respectively. In contrast to the conventional alternating minimization strategy, a meta-learning-based framework is applied to learn an adaptive optimization strategy, which is less-greedy and results in better convergence performance. These two procedures are iteratively processed in a plug-and-play fashion, for the first time, realizing a learning-based but plug-and-play blind SISR solution in unsupervised inference. Extensive simulations demonstrate the superior performance and generalization ability of the proposed approach when comparing with state-of-the-arts on synthesis and real-world datasets. The code is available at https://github.com/XYLGroup/MLMC.
A Dynamic Kernel Prior Model for Unsupervised Blind Image Super-Resolution
Apr 26, 2024



Deep learning-based methods have achieved significant successes on solving the blind super-resolution (BSR) problem. However, most of them request supervised pre-training on labelled datasets. This paper proposes an unsupervised kernel estimation model, named dynamic kernel prior (DKP), to realize an unsupervised and pre-training-free learning-based algorithm for solving the BSR problem. DKP can adaptively learn dynamic kernel priors to realize real-time kernel estimation, and thereby enables superior HR image restoration performances. This is achieved by a Markov chain Monte Carlo sampling process on random kernel distributions. The learned kernel prior is then assigned to optimize a blur kernel estimation network, which entails a network-based Langevin dynamic optimization strategy. These two techniques ensure the accuracy of the kernel estimation. DKP can be easily used to replace the kernel estimation models in the existing methods, such as Double-DIP and FKP-DIP, or be added to the off-the-shelf image restoration model, such as diffusion model. In this paper, we incorporate our DKP model with DIP and diffusion model, referring to DIP-DKP and Diff-DKP, for validations. Extensive simulations on Gaussian and motion kernel scenarios demonstrate that the proposed DKP model can significantly improve the kernel estimation with comparable runtime and memory usage, leading to state-of-the-art BSR results. The code is available at https://github.com/XYLGroup/DKP.
Boosting Convolutional Neural Networks with Middle Spectrum Grouped Convolution
Apr 13, 2023This paper proposes a novel module called middle spectrum grouped convolution (MSGC) for efficient deep convolutional neural networks (DCNNs) with the mechanism of grouped convolution. It explores the broad "middle spectrum" area between channel pruning and conventional grouped convolution. Compared with channel pruning, MSGC can retain most of the information from the input feature maps due to the group mechanism; compared with grouped convolution, MSGC benefits from the learnability, the core of channel pruning, for constructing its group topology, leading to better channel division. The middle spectrum area is unfolded along four dimensions: group-wise, layer-wise, sample-wise, and attention-wise, making it possible to reveal more powerful and interpretable structures. As a result, the proposed module acts as a booster that can reduce the computational cost of the host backbones for general image recognition with even improved predictive accuracy. For example, in the experiments on ImageNet dataset for image classification, MSGC can reduce the multiply-accumulates (MACs) of ResNet-18 and ResNet-50 by half but still increase the Top-1 accuracy by more than 1%. With 35% reduction of MACs, MSGC can also increase the Top-1 accuracy of the MobileNetV2 backbone. Results on MS COCO dataset for object detection show similar observations. Our code and trained models are available at https://github.com/hellozhuo/msgc.
A Learning Aided Gradient Descent for MISO Beamforming
Jun 21, 2022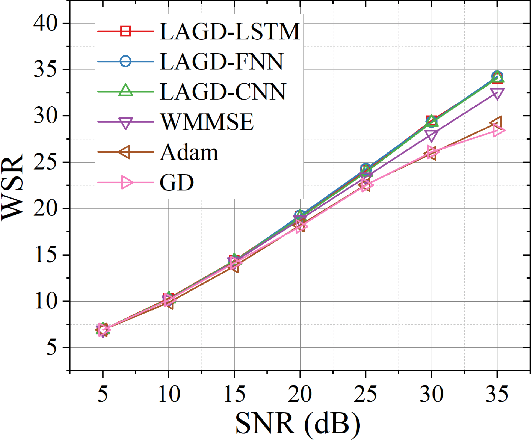

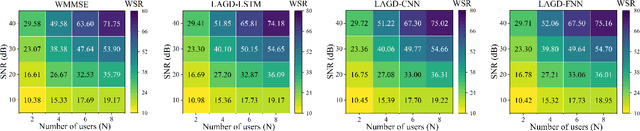
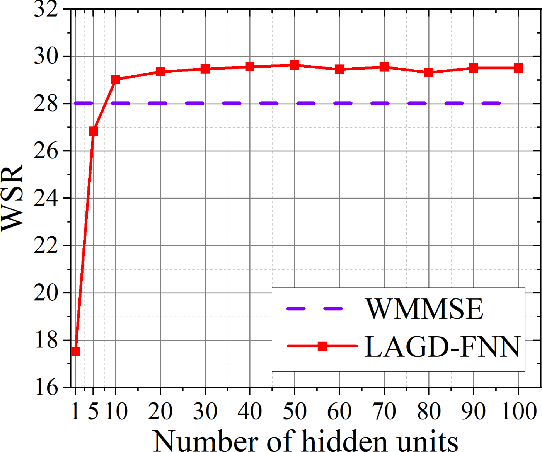
This paper proposes a learning aided gradient descent (LAGD) algorithm to solve the weighted sum rate (WSR) maximization problem for multiple-input single-output (MISO) beamforming. The proposed LAGD algorithm directly optimizes the transmit precoder through implicit gradient descent based iterations, at each of which the optimization strategy is determined by a neural network, and thus, is dynamic and adaptive. At each instance of the problem, this network is initialized randomly, and updated throughout the iterative solution process. Therefore, the LAGD algorithm can be implemented at any signal-to-noise ratio (SNR) and for arbitrary antenna/user numbers, does not require labelled data or training prior to deployment. Numerical results show that the LAGD algorithm can outperform of the well-known WMMSE algorithm as well as other learning-based solutions with a modest computational complexity. Our code is available at https://github.com/XiaGroup/LAGD.