 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaveform Design Based on Mutual Information Upper Bound For Joint Detection and Estimation
Apr 30, 2025



Adaptive radar waveform design grounded in information-theoretic principles is critical for advancing cognitive radar performance in complex environments. This paper investigates the optimization of phase-coded waveforms under constant modulus constraints to jointly enhance target detection and parameter estimation. We introduce a unified design framework based on maximizing a Mutual Information Upper Bound (MIUB), which inherently reconciles the trade-off between detection sensitivity and estimation precision without relying on ad hoc weighting schemes. To model realistic, potentially non-Gaussian statistics of target returns and clutter, we adopt Gaussian Mixture Distributions (GMDs), enabling analytically tractable approximations of the MIUB's constituent Kullback-Leibler divergence and mutual information terms. To address the resulting non-convex problem, we propose the Phase-Coded Dream Optimization Algorithm (PC-DOA), a tailored metaheuristic that leverages hybrid initialization and adaptive exploration-exploitation mechanisms specifically designed for phase-variable optimization. Numerical simulations demonstrate the effectiveness of the proposed method in achieving modestly better detection-estimation trade-off.
SE-BSFV: Online Subspace Learning based Shadow Enhancement and Background Suppression for ViSAR under Complex Background
Jan 16, 2025



Video synthetic aperture radar (ViSAR) has attracted substantial attention in the moving target detection (MTD) field due to its ability to continuously monitor changes in the target area. In ViSAR, the moving targets' shadows will not offset and defocus, which is widely used as a feature for MTD. However, the shadows are difficult to distinguish from the low scattering region in the background, which will cause more missing and false alarms. Therefore, it is worth investigating how to enhance the distinction between the shadows and background. In this study, we proposed the Shadow Enhancement and Background Suppression for ViSAR (SE-BSFV) algorithm. The SE-BSFV algorithm is based on the low-rank representation (LRR) theory and adopts online subspace learning technique to enhance shadows and suppress background for ViSAR images. Firstly, we use a registration algorithm to register the ViSAR images and utilize Gaussian mixture distribution (GMD) to model the ViSAR data. Secondly, the knowledge learned from the previous frames is leveraged to estimate the GMD parameters of the current frame, and the Expectation-maximization (EM) algorithm is used to estimate the subspace parameters. Then, the foreground matrix of the current frame can be obtained. Finally, the alternating direction method of multipliers (ADMM) is used to eliminate strong scattering objects in the foreground matrix to obtain the final results. The experimental results indicate that the SE-BSFV algorithm significantly enhances the shadows' saliency and greatly improves the detection performance while ensuring efficiency compared with several other advanced pre-processing algorithms.
Blind Super-Resolution via Meta-learning and Markov Chain Monte Carlo Simulation
Jun 13, 2024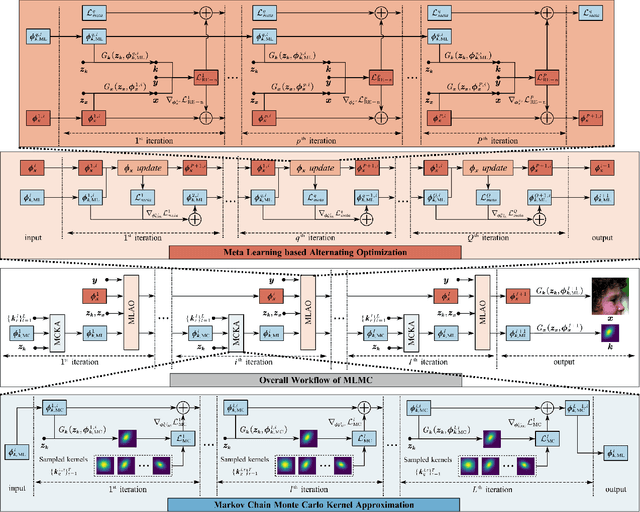
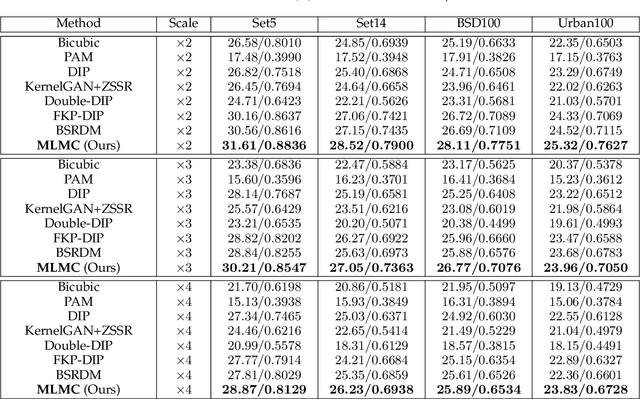
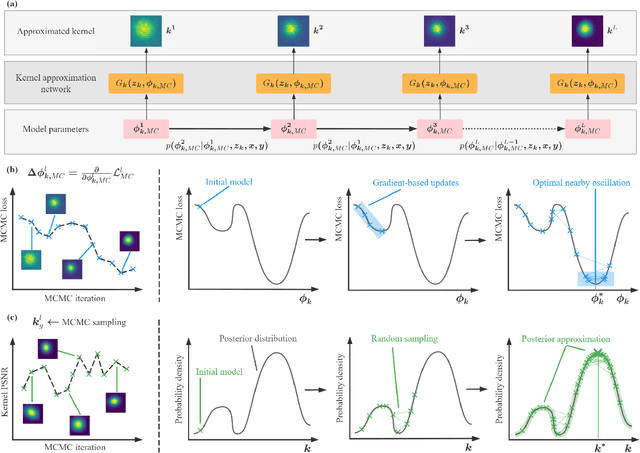
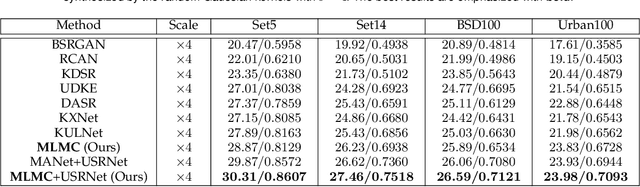
Learning-based approaches have witnessed great successes in blind single image super-resolution (SISR) tasks, however, handcrafted kernel priors and learning based kernel priors are typically required. In this paper, we propose a Meta-learning and Markov Chain Monte Carlo (MCMC) based SISR approach to learn kernel priors from organized randomness. In concrete, a lightweight network is adopted as kernel generator, and is optimized via learning from the MCMC simulation on random Gaussian distributions. This procedure provides an approximation for the rational blur kernel, and introduces a network-level Langevin dynamics into SISR optimization processes, which contributes to preventing bad local optimal solutions for kernel estimation. Meanwhile, a meta-learning-based alternating optimization procedure is proposed to optimize the kernel generator and image restorer, respectively. In contrast to the conventional alternating minimization strategy, a meta-learning-based framework is applied to learn an adaptive optimization strategy, which is less-greedy and results in better convergence performance. These two procedures are iteratively processed in a plug-and-play fashion, for the first time, realizing a learning-based but plug-and-play blind SISR solution in unsupervised inference. Extensive simulations demonstrate the superior performance and generalization ability of the proposed approach when comparing with state-of-the-arts on synthesis and real-world datasets. The code is available at https://github.com/XYLGroup/MLMC.
A Dynamic Kernel Prior Model for Unsupervised Blind Image Super-Resolution
Apr 26, 2024



Deep learning-based methods have achieved significant successes on solving the blind super-resolution (BSR) problem. However, most of them request supervised pre-training on labelled datasets. This paper proposes an unsupervised kernel estimation model, named dynamic kernel prior (DKP), to realize an unsupervised and pre-training-free learning-based algorithm for solving the BSR problem. DKP can adaptively learn dynamic kernel priors to realize real-time kernel estimation, and thereby enables superior HR image restoration performances. This is achieved by a Markov chain Monte Carlo sampling process on random kernel distributions. The learned kernel prior is then assigned to optimize a blur kernel estimation network, which entails a network-based Langevin dynamic optimization strategy. These two techniques ensure the accuracy of the kernel estimation. DKP can be easily used to replace the kernel estimation models in the existing methods, such as Double-DIP and FKP-DIP, or be added to the off-the-shelf image restoration model, such as diffusion model. In this paper, we incorporate our DKP model with DIP and diffusion model, referring to DIP-DKP and Diff-DKP, for validations. Extensive simulations on Gaussian and motion kernel scenarios demonstrate that the proposed DKP model can significantly improve the kernel estimation with comparable runtime and memory usage, leading to state-of-the-art BSR results. The code is available at https://github.com/XYLGroup/DKP.