 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSE-BSFV: Online Subspace Learning based Shadow Enhancement and Background Suppression for ViSAR under Complex Background
Jan 16, 2025



Video synthetic aperture radar (ViSAR) has attracted substantial attention in the moving target detection (MTD) field due to its ability to continuously monitor changes in the target area. In ViSAR, the moving targets' shadows will not offset and defocus, which is widely used as a feature for MTD. However, the shadows are difficult to distinguish from the low scattering region in the background, which will cause more missing and false alarms. Therefore, it is worth investigating how to enhance the distinction between the shadows and background. In this study, we proposed the Shadow Enhancement and Background Suppression for ViSAR (SE-BSFV) algorithm. The SE-BSFV algorithm is based on the low-rank representation (LRR) theory and adopts online subspace learning technique to enhance shadows and suppress background for ViSAR images. Firstly, we use a registration algorithm to register the ViSAR images and utilize Gaussian mixture distribution (GMD) to model the ViSAR data. Secondly, the knowledge learned from the previous frames is leveraged to estimate the GMD parameters of the current frame, and the Expectation-maximization (EM) algorithm is used to estimate the subspace parameters. Then, the foreground matrix of the current frame can be obtained. Finally, the alternating direction method of multipliers (ADMM) is used to eliminate strong scattering objects in the foreground matrix to obtain the final results. The experimental results indicate that the SE-BSFV algorithm significantly enhances the shadows' saliency and greatly improves the detection performance while ensuring efficiency compared with several other advanced pre-processing algorithms.
Marketing Budget Allocation with Offline Constrained Deep Reinforcement Learning
Sep 06, 2023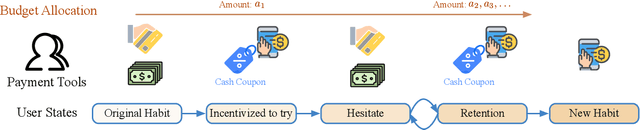
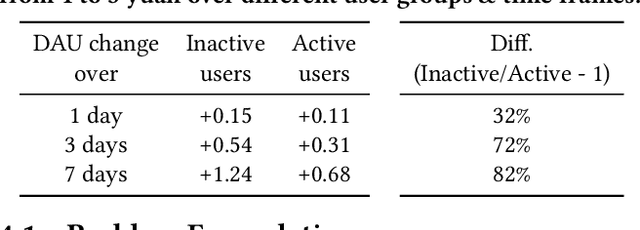
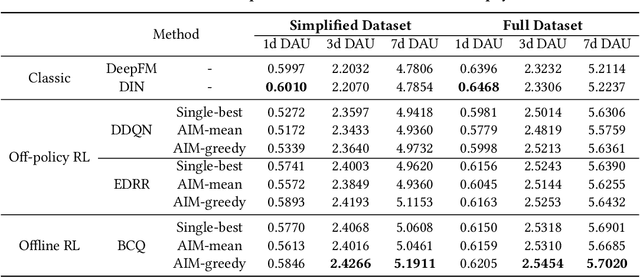
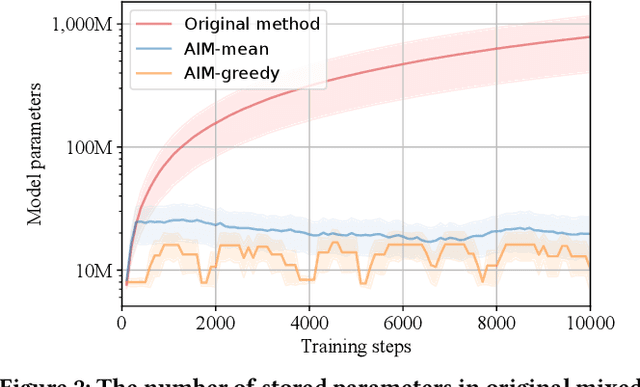
We study the budget allocation problem in online marketing campaigns that utilize previously collected offline data. We first discuss the long-term effect of optimizing marketing budget allocation decisions in the offline setting. To overcome the challenge, we propose a novel game-theoretic offline value-based reinforcement learning method using mixed policies. The proposed method reduces the need to store infinitely many policies in previous methods to only constantly many policies, which achieves nearly optimal policy efficiency, making it practical and favorable for industrial usage. We further show that this method is guaranteed to converge to the optimal policy, which cannot be achieved by previous value-based reinforcement learning methods for marketing budget allocation. Our experiments on a large-scale marketing campaign with tens-of-millions users and more than one billion budget verify the theoretical results and show that the proposed method outperforms various baseline methods. The proposed method has been successfully deployed to serve all the traffic of this marketing campaign.
Model-free Reinforcement Learning with Stochastic Reward Stabilization for Recommender Systems
Aug 25, 2023Model-free RL-based recommender systems have recently received increasing research attention due to their capability to handle partial feedback and long-term rewards. However, most existing research has ignored a critical feature in recommender systems: one user's feedback on the same item at different times is random. The stochastic rewards property essentially differs from that in classic RL scenarios with deterministic rewards, which makes RL-based recommender systems much more challenging. In this paper, we first demonstrate in a simulator environment where using direct stochastic feedback results in a significant drop in performance. Then to handle the stochastic feedback more efficiently, we design two stochastic reward stabilization frameworks that replace the direct stochastic feedback with that learned by a supervised model. Both frameworks are model-agnostic, i.e., they can effectively utilize various supervised models. We demonstrate the superiority of the proposed frameworks over different RL-based recommendation baselines with extensive experiments on a recommendation simulator as well as an industrial-level recommender system.
Discovering and Explaining the Non-Causality of Deep Learning in SAR ATR
Apr 12, 2023



In recent years, deep learning has been widely used in SAR ATR and achieved excellent performance on the MSTAR dataset. However, due to constrained imaging conditions, MSTAR has data biases such as background correlation, i.e., background clutter properties have a spurious correlation with target classes. Deep learning can overfit clutter to reduce training errors. Therefore, the degree of overfitting for clutter reflects the non-causality of deep learning in SAR ATR. Existing methods only qualitatively analyze this phenomenon. In this paper, we quantify the contributions of different regions to target recognition based on the Shapley value. The Shapley value of clutter measures the degree of overfitting. Moreover, we explain how data bias and model bias contribute to non-causality. Concisely, data bias leads to comparable signal-to-clutter ratios and clutter textures in training and test sets. And various model structures have different degrees of overfitting for these biases. The experimental results of various models under standard operating conditions on the MSTAR dataset support our conclusions. Our code is available at https://github.com/waterdisappear/Data-Bias-in-MSTAR.
Hierarchical Disentanglement-Alignment Network for Robust SAR Vehicle Recognition
Apr 07, 2023
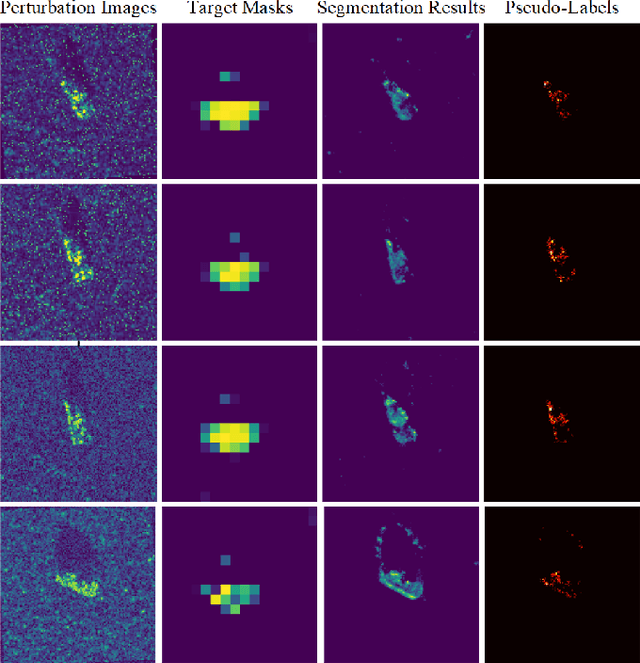


Due to Synthetic Aperture Radar (SAR) imaging characteristics, SAR vehicle recognition faces the problem of extracting discriminative and robust target features from a small dataset. Deep learning has shown impressive performance on the MSTAR dataset. However, data bias in a small dataset, such as background correlation, impairs the causality of these methods, i.e., discriminative features contain target and background differences. Moreover, different operating conditions of SAR lead to target signatures and background clutter variations in imaging results. However, many deep learning-based methods only verify robustness to target or background variations in the current experimental setting. In this paper, we propose a novel domain alignment framework named Hierarchical Disentanglement-Alignment Network (HDANet) to enhance features' causality and robustness. Concisely, HDANet consists of three parts: The first part uses data augmentation to generate signature variations for domain alignment. The second part disentangles the target features through a multitask-assisted mask to prevent non-causal clutter from interfering with subsequent alignment and recognition. Thirdly, a contrastive loss is employed for domain alignment to extract robust target features, and the SimSiam structure is applied to mitigate conflicts between contrastive loss and feature discrimination. Finally, the proposed method shows high robustness across MSTAR's multiple target, sensor, and environment variants. Noteworthy, we add a new scene variant to verify the robustness to target and background variations. Moreover, the saliency map and Shapley value qualitatively and quantitatively demonstrate causality. Our code is available in \url{https://github.com/waterdisappear/SAR-ATR-HDANet}.
A Policy Efficient Reduction Approach to Convex Constrained Deep Reinforcement Learning
Aug 29, 2021
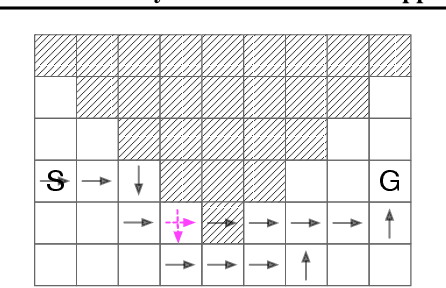
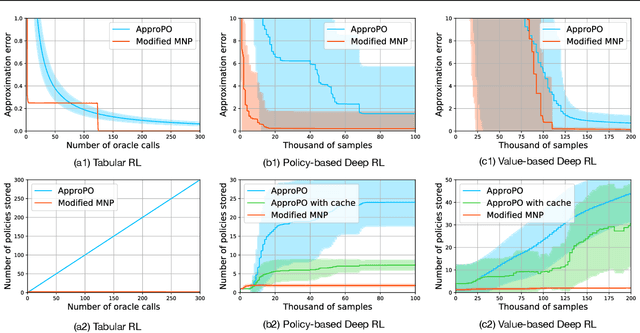

Although well-established in general reinforcement learning (RL), value-based methods are rarely explored in constrained RL (CRL) for their incapability of finding policies that can randomize among multiple actions. To apply value-based methods to CRL, a recent groundbreaking line of game-theoretic approaches uses the mixed policy that randomizes among a set of carefully generated policies to converge to the desired constraint-satisfying policy. However, these approaches require storing a large set of policies, which is not policy efficient, and may incur prohibitive memory costs in constrained deep RL. To address this problem, we propose an alternative approach. Our approach first reformulates the CRL to an equivalent distance optimization problem. With a specially designed linear optimization oracle, we derive a meta-algorithm that solves it using any off-the-shelf RL algorithm and any conditional gradient (CG) type algorithm as subroutines. We then propose a new variant of the CG-type algorithm, which generalizes the minimum norm point (MNP) method. The proposed method matches the convergence rate of the existing game-theoretic approaches and achieves the worst-case optimal policy efficiency. The experiments on a navigation task show that our method reduces the memory costs by an order of magnitude, and meanwhile achieves better performance, demonstrating both its effectiveness and efficiency.
Online Compact Convexified Factorization Machine
Feb 05, 2018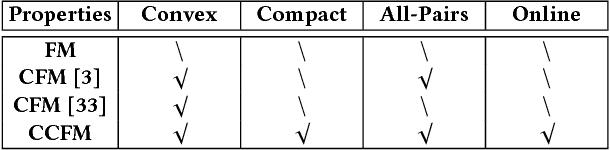
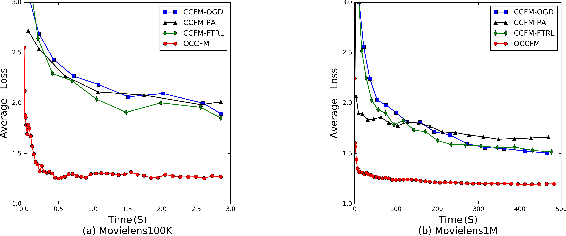
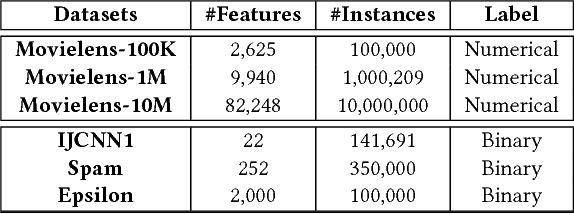
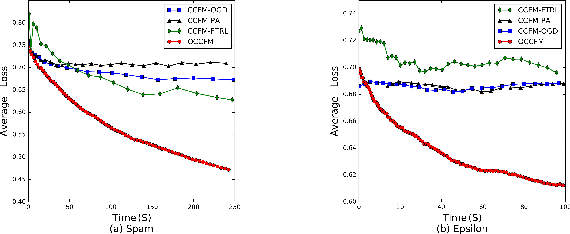
Factorization Machine (FM) is a supervised learning approach with a powerful capability of feature engineering. It yields state-of-the-art performance in various batch learning tasks where all the training data is made available prior to the training. However, in real-world applications where the data arrives sequentially in a streaming manner, the high cost of re-training with batch learning algorithms has posed formidable challenges in the online learning scenario. The initial challenge is that no prior formulations of FM could fulfill the requirements in Online Convex Optimization (OCO) -- the paramount framework for online learning algorithm design. To address the aforementioned challenge, we invent a new convexification scheme leading to a Compact Convexified FM (CCFM) that seamlessly meets the requirements in OCO. However for learning Compact Convexified FM (CCFM) in the online learning setting, most existing algorithms suffer from expensive projection operations. To address this subsequent challenge, we follow the general projection-free algorithmic framework of Online Conditional Gradient and propose an Online Compact Convex Factorization Machine (OCCFM) algorithm that eschews the projection operation with efficient linear optimization steps. In support of the proposed OCCFM in terms of its theoretical foundation, we prove that the developed algorithm achieves a sub-linear regret bound. To evaluate the empirical performance of OCCFM, we conduct extensive experiments on 6 real-world datasets for online recommendation and binary classification tasks. The experimental results show that OCCFM outperforms the state-of-art online learning algorithms.