 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution-Specific Learning for Joint Salient and Camouflaged Object Detection
Aug 08, 2025Salient object detection (SOD) and camouflaged object detection (COD) are two closely related but distinct computer vision tasks. Although both are class-agnostic segmentation tasks that map from RGB space to binary space, the former aims to identify the most salient objects in the image, while the latter focuses on detecting perfectly camouflaged objects that blend into the background in the image. These two tasks exhibit strong contradictory attributes. Previous works have mostly believed that joint learning of these two tasks would confuse the network, reducing its performance on both tasks. However, here we present an opposite perspective: with the correct approach to learning, the network can simultaneously possess the capability to find both salient and camouflaged objects, allowing both tasks to benefit from joint learning. We propose SCJoint, a joint learning scheme for SOD and COD tasks, assuming that the decoding processes of SOD and COD have different distribution characteristics. The key to our method is to learn the respective means and variances of the decoding processes for both tasks by inserting a minimal amount of task-specific learnable parameters within a fully shared network structure, thereby decoupling the contradictory attributes of the two tasks at a minimal cost. Furthermore, we propose a saliency-based sampling strategy (SBSS) to sample the training set of the SOD task to balance the training set sizes of the two tasks. In addition, SBSS improves the training set quality and shortens the training time. Based on the proposed SCJoint and SBSS, we train a powerful generalist network, named JoNet, which has the ability to simultaneously capture both ``salient" and ``camouflaged". Extensive experiments demonstrate the competitive performance and effectiveness of our proposed method. The code is available at https://github.com/linuxsino/JoNet.
FEALLM: Advancing Facial Emotion Analysis in Multimodal Large Language Models with Emotional Synergy and Reasoning
May 19, 2025Facial Emotion Analysis (FEA) plays a crucial role in visual affective computing, aiming to infer a person's emotional state based on facial data. Scientifically, facial expressions (FEs) result from the coordinated movement of facial muscles, which can be decomposed into specific action units (AUs) that provide detailed emotional insights. However, traditional methods often struggle with limited interpretability, constrained generalization and reasoning abilities. Recently, Multimodal Large Language Models (MLLMs) have shown exceptional performance in various visual tasks, while they still face significant challenges in FEA due to the lack of specialized datasets and their inability to capture the intricate relationships between FEs and AUs. To address these issues, we introduce a novel FEA Instruction Dataset that provides accurate and aligned FE and AU descriptions and establishes causal reasoning relationships between them, followed by constructing a new benchmark, FEABench. Moreover, we propose FEALLM, a novel MLLM architecture designed to capture more detailed facial information, enhancing its capability in FEA tasks. Our model demonstrates strong performance on FEABench and impressive generalization capability through zero-shot evaluation on various datasets, including RAF-DB, AffectNet, BP4D, and DISFA, showcasing its robustness and effectiveness in FEA tasks. The dataset and code will be available at https://github.com/953206211/FEALLM.
CodePhys: Robust Video-based Remote Physiological Measurement through Latent Codebook Querying
Feb 11, 2025Remote photoplethysmography (rPPG) aims to measure non-contact physiological signals from facial videos, which has shown great potential in many applications. Most existing methods directly extract video-based rPPG features by designing neural networks for heart rate estimation. Although they can achieve acceptable results, the recovery of rPPG signal faces intractable challenges when interference from real-world scenarios takes place on facial video. Specifically, facial videos are inevitably affected by non-physiological factors (e.g., camera device noise, defocus, and motion blur), leading to the distortion of extracted rPPG signals. Recent rPPG extraction methods are easily affected by interference and degradation, resulting in noisy rPPG signals. In this paper, we propose a novel method named CodePhys, which innovatively treats rPPG measurement as a code query task in a noise-free proxy space (i.e., codebook) constructed by ground-truth PPG signals. We consider noisy rPPG features as queries and generate high-fidelity rPPG features by matching them with noise-free PPG features from the codebook. Our approach also incorporates a spatial-aware encoder network with a spatial attention mechanism to highlight physiologically active areas and uses a distillation loss to reduce the influence of non-periodic visual interference. Experimental results on four benchmark datasets demonstrate that CodePhys outperforms state-of-the-art methods in both intra-dataset and cross-dataset settings.
DiffFAS: Face Anti-Spoofing via Generative Diffusion Models
Sep 13, 2024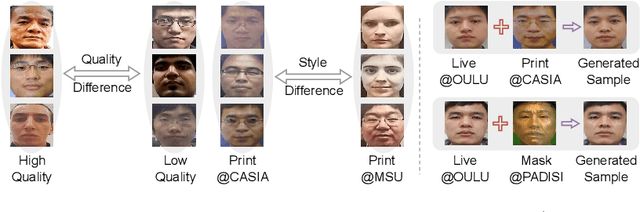
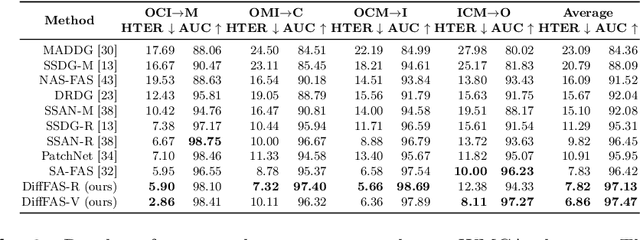
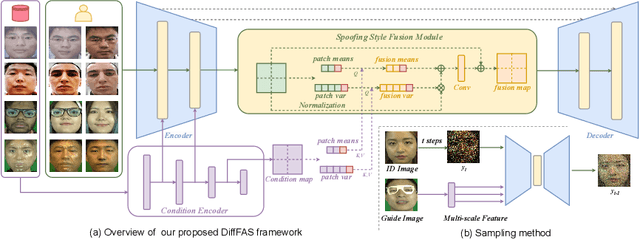

Face anti-spoofing (FAS) plays a vital role in preventing face recognition (FR) systems from presentation attacks. Nowadays, FAS systems face the challenge of domain shift, impacting the generalization performance of existing FAS methods. In this paper, we rethink about the inherence of domain shift and deconstruct it into two factors: image style and image quality. Quality influences the purity of the presentation of spoof information, while style affects the manner in which spoof information is presented. Based on our analysis, we propose DiffFAS framework, which quantifies quality as prior information input into the network to counter image quality shift, and performs diffusion-based high-fidelity cross-domain and cross-attack types generation to counter image style shift. DiffFAS transforms easily collectible live faces into high-fidelity attack faces with precise labels while maintaining consistency between live and spoof face identities, which can also alleviate the scarcity of labeled data with novel type attacks faced by nowadays FAS system. We demonstrate the effectiveness of our framework on challenging cross-domain and cross-attack FAS datasets, achieving the state-of-the-art performance. Available at https://github.com/murphytju/DiffFAS.
Towards Domain-Specific Cross-Corpus Speech Emotion Recognition Approach
Dec 11, 2023Cross-corpus speech emotion recognition (SER) poses a challenge due to feature distribution mismatch, potentially degrading the performance of established SER methods. In this paper, we tackle this challenge by proposing a novel transfer subspace learning method called acoustic knowledgeguided transfer linear regression (AKTLR). Unlike existing approaches, which often overlook domain-specific knowledge related to SER and simply treat cross-corpus SER as a generic transfer learning task, our AKTLR method is built upon a well-designed acoustic knowledge-guided dual sparsity constraint mechanism. This mechanism emphasizes the potential of minimalistic acoustic parameter feature sets to alleviate classifier overadaptation, which is empirically validated acoustic knowledge in SER, enabling superior generalization in cross-corpus SER tasks compared to using large feature sets. Through this mechanism, we extend a simple transfer linear regression model to AKTLR. This extension harnesses its full capability to seek emotiondiscriminative and corpus-invariant features from established acoustic parameter feature sets used for describing speech signals across two scales: contributive acoustic parameter groups and constituent elements within each contributive group. Our proposed method is evaluated through extensive cross-corpus SER experiments on three widely-used speech emotion corpora: EmoDB, eNTERFACE, and CASIA. The results confirm the effectiveness and superior performance of our method, outperforming recent state-of-the-art transfer subspace learning and deep transfer learning-based cross-corpus SER methods. Furthermore, our work provides experimental evidence supporting the feasibility and superiority of incorporating domain-specific knowledge into the transfer learning model to address cross-corpus SER tasks.
Learning to Rank Onset-Occurring-Offset Representations for Micro-Expression Recognition
Oct 07, 2023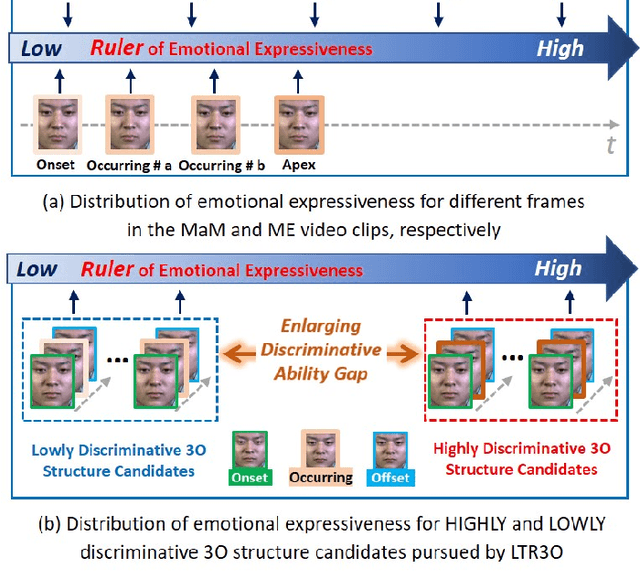
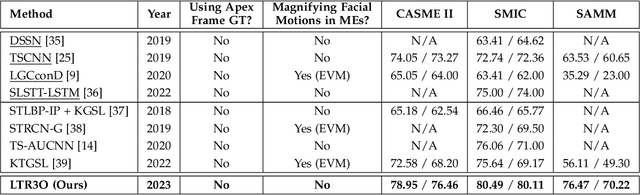
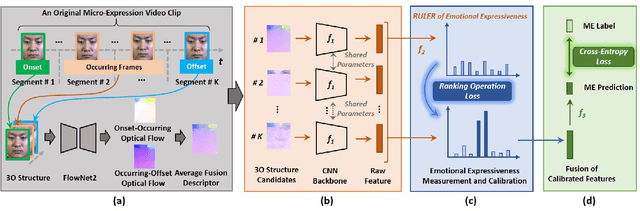
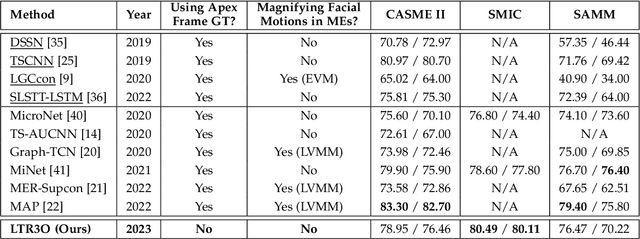
This paper focuses on the research of micro-expression recognition (MER) and proposes a flexible and reliable deep learning method called learning to rank onset-occurring-offset representations (LTR3O). The LTR3O method introduces a dynamic and reduced-size sequence structure known as 3O, which consists of onset, occurring, and offset frames, for representing micro-expressions (MEs). This structure facilitates the subsequent learning of ME-discriminative features. A noteworthy advantage of the 3O structure is its flexibility, as the occurring frame is randomly extracted from the original ME sequence without the need for accurate frame spotting methods. Based on the 3O structures, LTR3O generates multiple 3O representation candidates for each ME sample and incorporates well-designed modules to measure and calibrate their emotional expressiveness. This calibration process ensures that the distribution of these candidates aligns with that of macro-expressions (MaMs) over time. Consequently, the visibility of MEs can be implicitly enhanced, facilitating the reliable learning of more discriminative features for MER. Extensive experiments were conducted to evaluate the performance of LTR3O using three widely-used ME databases: CASME II, SMIC, and SAMM. The experimental results demonstrate the effectiveness and superior performance of LTR3O, particularly in terms of its flexibility and reliability, when compared to recent state-of-the-art MER methods.
Multi-scale Promoted Self-adjusting Correlation Learning for Facial Action Unit Detection
Aug 15, 2023Facial Action Unit (AU) detection is a crucial task in affective computing and social robotics as it helps to identify emotions expressed through facial expressions. Anatomically, there are innumerable correlations between AUs, which contain rich information and are vital for AU detection. Previous methods used fixed AU correlations based on expert experience or statistical rules on specific benchmarks, but it is challenging to comprehensively reflect complex correlations between AUs via hand-crafted settings. There are alternative methods that employ a fully connected graph to learn these dependencies exhaustively. However, these approaches can result in a computational explosion and high dependency with a large dataset. To address these challenges, this paper proposes a novel self-adjusting AU-correlation learning (SACL) method with less computation for AU detection. This method adaptively learns and updates AU correlation graphs by efficiently leveraging the characteristics of different levels of AU motion and emotion representation information extracted in different stages of the network. Moreover, this paper explores the role of multi-scale learning in correlation information extraction, and design a simple yet effective multi-scale feature learning (MSFL) method to promote better performance in AU detection. By integrating AU correlation information with multi-scale features, the proposed method obtains a more robust feature representation for the final AU detection. Extensive experiments show that the proposed method outperforms the state-of-the-art methods on widely used AU detection benchmark datasets, with only 28.7\% and 12.0\% of the parameters and FLOPs of the best method, respectively. The code for this method is available at \url{https://github.com/linuxsino/Self-adjusting-AU}.
PhysFormer++: Facial Video-based Physiological Measurement with SlowFast Temporal Difference Transformer
Feb 07, 2023Remote photoplethysmography (rPPG), which aims at measuring heart activities and physiological signals from facial video without any contact, has great potential in many applications (e.g., remote healthcare and affective computing). Recent deep learning approaches focus on mining subtle rPPG clues using convolutional neural networks with limited spatio-temporal receptive fields, which neglect the long-range spatio-temporal perception and interaction for rPPG modeling. In this paper, we propose two end-to-end video transformer based architectures, namely PhysFormer and PhysFormer++, to adaptively aggregate both local and global spatio-temporal features for rPPG representation enhancement. As key modules in PhysFormer, the temporal difference transformers first enhance the quasi-periodic rPPG features with temporal difference guided global attention, and then refine the local spatio-temporal representation against interference. To better exploit the temporal contextual and periodic rPPG clues, we also extend the PhysFormer to the two-pathway SlowFast based PhysFormer++ with temporal difference periodic and cross-attention transformers. Furthermore, we propose the label distribution learning and a curriculum learning inspired dynamic constraint in frequency domain, which provide elaborate supervisions for PhysFormer and PhysFormer++ and alleviate overfitting. Comprehensive experiments are performed on four benchmark datasets to show our superior performance on both intra- and cross-dataset testings. Unlike most transformer networks needed pretraining from large-scale datasets, the proposed PhysFormer family can be easily trained from scratch on rPPG datasets, which makes it promising as a novel transformer baseline for the rPPG community.
Learning Motion-Robust Remote Photoplethysmography through Arbitrary Resolution Videos
Dec 02, 2022Remote photoplethysmography (rPPG) enables non-contact heart rate (HR) estimation from facial videos which gives significant convenience compared with traditional contact-based measurements. In the real-world long-term health monitoring scenario, the distance of the participants and their head movements usually vary by time, resulting in the inaccurate rPPG measurement due to the varying face resolution and complex motion artifacts. Different from the previous rPPG models designed for a constant distance between camera and participants, in this paper, we propose two plug-and-play blocks (i.e., physiological signal feature extraction block (PFE) and temporal face alignment block (TFA)) to alleviate the degradation of changing distance and head motion. On one side, guided with representative-area information, PFE adaptively encodes the arbitrary resolution facial frames to the fixed-resolution facial structure features. On the other side, leveraging the estimated optical flow, TFA is able to counteract the rPPG signal confusion caused by the head movement thus benefit the motion-robust rPPG signal recovery. Besides, we also train the model with a cross-resolution constraint using a two-stream dual-resolution framework, which further helps PFE learn resolution-robust facial rPPG features. Extensive experiments on three benchmark datasets (UBFC-rPPG, COHFACE and PURE) demonstrate the superior performance of the proposed method. One highlight is that with PFE and TFA, the off-the-shelf spatio-temporal rPPG models can predict more robust rPPG signals under both varying face resolution and severe head movement scenarios. The codes are available at https://github.com/LJW-GIT/Arbitrary_Resolution_rPPG.
Benchmarking Joint Face Spoofing and Forgery Detection with Visual and Physiological Cues
Aug 10, 2022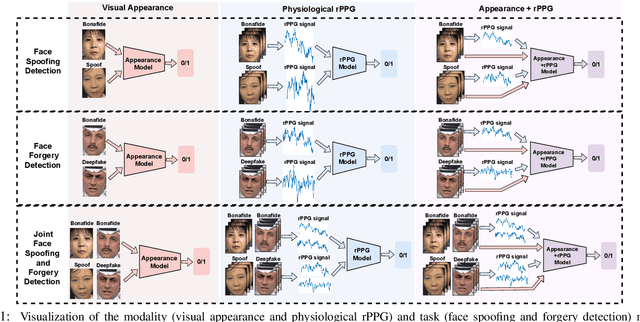

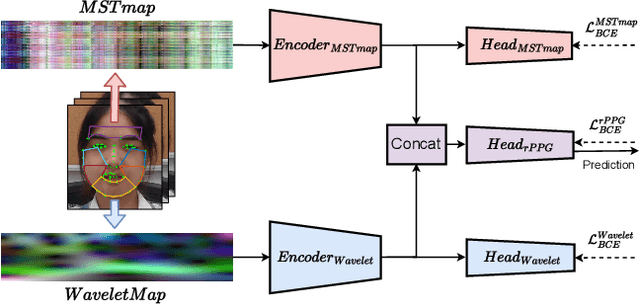

Face anti-spoofing (FAS) and face forgery detection play vital roles in securing face biometric systems from presentation attacks (PAs) and vicious digital manipulation (e.g., deepfakes). Despite promising performance upon large-scale data and powerful deep models, the generalization problem of existing approaches is still an open issue. Most of recent approaches focus on 1) unimodal visual appearance or physiological (i.e., remote photoplethysmography (rPPG)) cues; and 2) separated feature representation for FAS or face forgery detection. On one side, unimodal appearance and rPPG features are respectively vulnerable to high-fidelity face 3D mask and video replay attacks, inspiring us to design reliable multi-modal fusion mechanisms for generalized face attack detection. On the other side, there are rich common features across FAS and face forgery detection tasks (e.g., periodic rPPG rhythms and vanilla appearance for bonafides), providing solid evidence to design a joint FAS and face forgery detection system in a multi-task learning fashion. In this paper, we establish the first joint face spoofing and forgery detection benchmark using both visual appearance and physiological rPPG cues. To enhance the rPPG periodicity discrimination, we design a two-branch physiological network using both facial spatio-temporal rPPG signal map and its continuous wavelet transformed counterpart as inputs. To mitigate the modality bias and improve the fusion efficacy, we conduct a weighted batch and layer normalization for both appearance and rPPG features before multi-modal fusion. We find that the generalization capacities of both unimodal (appearance or rPPG) and multi-modal (appearance+rPPG) models can be obviously improved via joint training on these two tasks. We hope this new benchmark will facilitate the future research of both FAS and deepfake detection communities.