 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Label Hierachical Network for Compound Emotion Recognition
Jul 17, 2024The emotion recognition has attracted more attention in recent decades. Although significant progress has been made in the recognition technology of the seven basic emotions, existing methods are still hard to tackle compound emotion recognition that occurred commonly in practical application. This article introduces our achievements in the 7th Field Emotion Behavior Analysis (ABAW) competition. In the competition, we selected pre trained ResNet18 and Transformer, which have been widely validated, as the basic network framework. Considering the continuity of emotions over time, we propose a time pyramid structure network for frame level emotion prediction. Furthermore. At the same time, in order to address the lack of data in composite emotion recognition, we utilized fine-grained labels from the DFEW database to construct training data for emotion categories in competitions. Taking into account the characteristics of valence arousal of various complex emotions, we constructed a classification framework from coarse to fine in the label space.
PAVITS: Exploring Prosody-aware VITS for End-to-End Emotional Voice Conversion
Mar 03, 2024In this paper, we propose Prosody-aware VITS (PAVITS) for emotional voice conversion (EVC), aiming to achieve two major objectives of EVC: high content naturalness and high emotional naturalness, which are crucial for meeting the demands of human perception. To improve the content naturalness of converted audio, we have developed an end-to-end EVC architecture inspired by the high audio quality of VITS. By seamlessly integrating an acoustic converter and vocoder, we effectively address the common issue of mismatch between emotional prosody training and run-time conversion that is prevalent in existing EVC models. To further enhance the emotional naturalness, we introduce an emotion descriptor to model the subtle prosody variations of different speech emotions. Additionally, we propose a prosody predictor, which predicts prosody features from text based on the provided emotion label. Notably, we introduce a prosody alignment loss to establish a connection between latent prosody features from two distinct modalities, ensuring effective training. Experimental results show that the performance of PAVITS is superior to the state-of-the-art EVC methods. Speech Samples are available at https://jeremychee4.github.io/pavits4EVC/ .
Speech Swin-Transformer: Exploring a Hierarchical Transformer with Shifted Windows for Speech Emotion Recognition
Jan 19, 2024


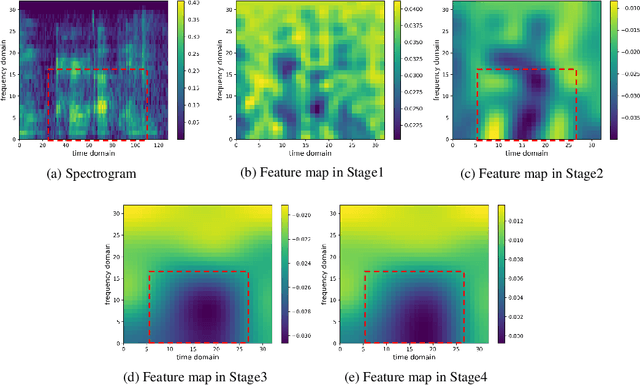
Swin-Transformer has demonstrated remarkable success in computer vision by leveraging its hierarchical feature representation based on Transformer. In speech signals, emotional information is distributed across different scales of speech features, e.\,g., word, phrase, and utterance. Drawing above inspiration, this paper presents a hierarchical speech Transformer with shifted windows to aggregate multi-scale emotion features for speech emotion recognition (SER), called Speech Swin-Transformer. Specifically, we first divide the speech spectrogram into segment-level patches in the time domain, composed of multiple frame patches. These segment-level patches are then encoded using a stack of Swin blocks, in which a local window Transformer is utilized to explore local inter-frame emotional information across frame patches of each segment patch. After that, we also design a shifted window Transformer to compensate for patch correlations near the boundaries of segment patches. Finally, we employ a patch merging operation to aggregate segment-level emotional features for hierarchical speech representation by expanding the receptive field of Transformer from frame-level to segment-level. Experimental results demonstrate that our proposed Speech Swin-Transformer outperforms the state-of-the-art methods.
Improving Speaker-independent Speech Emotion Recognition Using Dynamic Joint Distribution Adaptation
Jan 18, 2024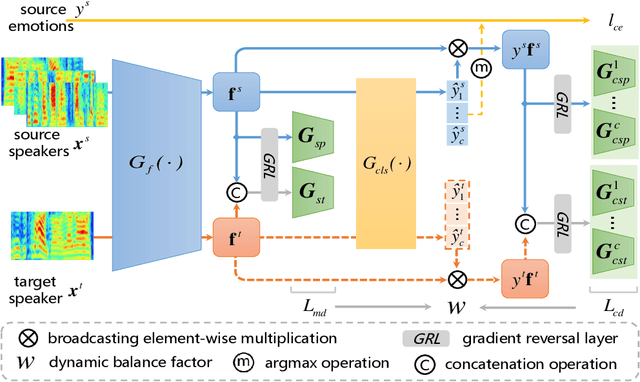


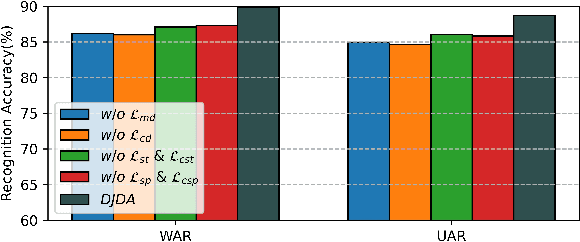
In speaker-independent speech emotion recognition, the training and testing samples are collected from diverse speakers, leading to a multi-domain shift challenge across the feature distributions of data from different speakers. Consequently, when the trained model is confronted with data from new speakers, its performance tends to degrade. To address the issue, we propose a Dynamic Joint Distribution Adaptation (DJDA) method under the framework of multi-source domain adaptation. DJDA firstly utilizes joint distribution adaptation (JDA), involving marginal distribution adaptation (MDA) and conditional distribution adaptation (CDA), to more precisely measure the multi-domain distribution shifts caused by different speakers. This helps eliminate speaker bias in emotion features, allowing for learning discriminative and speaker-invariant speech emotion features from coarse-level to fine-level. Furthermore, we quantify the adaptation contributions of MDA and CDA within JDA by using a dynamic balance factor based on $\mathcal{A}$-Distance, promoting to effectively handle the unknown distributions encountered in data from new speakers. Experimental results demonstrate the superior performance of our DJDA as compared to other state-of-the-art (SOTA) methods.
Towards Domain-Specific Cross-Corpus Speech Emotion Recognition Approach
Dec 11, 2023Cross-corpus speech emotion recognition (SER) poses a challenge due to feature distribution mismatch, potentially degrading the performance of established SER methods. In this paper, we tackle this challenge by proposing a novel transfer subspace learning method called acoustic knowledgeguided transfer linear regression (AKTLR). Unlike existing approaches, which often overlook domain-specific knowledge related to SER and simply treat cross-corpus SER as a generic transfer learning task, our AKTLR method is built upon a well-designed acoustic knowledge-guided dual sparsity constraint mechanism. This mechanism emphasizes the potential of minimalistic acoustic parameter feature sets to alleviate classifier overadaptation, which is empirically validated acoustic knowledge in SER, enabling superior generalization in cross-corpus SER tasks compared to using large feature sets. Through this mechanism, we extend a simple transfer linear regression model to AKTLR. This extension harnesses its full capability to seek emotiondiscriminative and corpus-invariant features from established acoustic parameter feature sets used for describing speech signals across two scales: contributive acoustic parameter groups and constituent elements within each contributive group. Our proposed method is evaluated through extensive cross-corpus SER experiments on three widely-used speech emotion corpora: EmoDB, eNTERFACE, and CASIA. The results confirm the effectiveness and superior performance of our method, outperforming recent state-of-the-art transfer subspace learning and deep transfer learning-based cross-corpus SER methods. Furthermore, our work provides experimental evidence supporting the feasibility and superiority of incorporating domain-specific knowledge into the transfer learning model to address cross-corpus SER tasks.
Layer-Adapted Implicit Distribution Alignment Networks for Cross-Corpus Speech Emotion Recognition
Oct 06, 2023In this paper, we propose a new unsupervised domain adaptation (DA) method called layer-adapted implicit distribution alignment networks (LIDAN) to address the challenge of cross-corpus speech emotion recognition (SER). LIDAN extends our previous ICASSP work, deep implicit distribution alignment networks (DIDAN), whose key contribution lies in the introduction of a novel regularization term called implicit distribution alignment (IDA). This term allows DIDAN trained on source (training) speech samples to remain applicable to predicting emotion labels for target (testing) speech samples, regardless of corpus variance in cross-corpus SER. To further enhance this method, we extend IDA to layer-adapted IDA (LIDA), resulting in LIDAN. This layer-adpated extention consists of three modified IDA terms that consider emotion labels at different levels of granularity. These terms are strategically arranged within different fully connected layers in LIDAN, aligning with the increasing emotion-discriminative abilities with respect to the layer depth. This arrangement enables LIDAN to more effectively learn emotion-discriminative and corpus-invariant features for SER across various corpora compared to DIDAN. It is also worthy to mention that unlike most existing methods that rely on estimating statistical moments to describe pre-assumed explicit distributions, both IDA and LIDA take a different approach. They utilize an idea of target sample reconstruction to directly bridge the feature distribution gap without making assumptions about their distribution type. As a result, DIDAN and LIDAN can be viewed as implicit cross-corpus SER methods. To evaluate LIDAN, we conducted extensive cross-corpus SER experiments on EmoDB, eNTERFACE, and CASIA corpora. The experimental results demonstrate that LIDAN surpasses recent state-of-the-art explicit unsupervised DA methods in tackling cross-corpus SER tasks.
Time-Frequency Transformer: A Novel Time Frequency Joint Learning Method for Speech Emotion Recognition
Aug 28, 2023In this paper, we propose a novel time-frequency joint learning method for speech emotion recognition, called Time-Frequency Transformer. Its advantage is that the Time-Frequency Transformer can excavate global emotion patterns in the time-frequency domain of speech signal while modeling the local emotional correlations in the time domain and frequency domain respectively. For the purpose, we first design a Time Transformer and Frequency Transformer to capture the local emotion patterns between frames and inside frequency bands respectively, so as to ensure the integrity of the emotion information modeling in both time and frequency domains. Then, a Time-Frequency Transformer is proposed to mine the time-frequency emotional correlations through the local time-domain and frequency-domain emotion features for learning more discriminative global speech emotion representation. The whole process is a time-frequency joint learning process implemented by a series of Transformer models. Experiments on IEMOCAP and CASIA databases indicate that our proposed method outdoes the state-of-the-art methods.
Deep Implicit Distribution Alignment Networks for Cross-Corpus Speech Emotion Recognition
Feb 17, 2023



In this paper, we propose a novel deep transfer learning method called deep implicit distribution alignment networks (DIDAN) to deal with cross-corpus speech emotion recognition (SER) problem, in which the labeled training (source) and unlabeled testing (target) speech signals come from different corpora. Specifically, DIDAN first adopts a simple deep regression network consisting of a set of convolutional and fully connected layers to directly regress the source speech spectrums into the emotional labels such that the proposed DIDAN can own the emotion discriminative ability. Then, such ability is transferred to be also applicable to the target speech samples regardless of corpus variance by resorting to a well-designed regularization term called implicit distribution alignment (IDA). Unlike widely-used maximum mean discrepancy (MMD) and its variants, the proposed IDA absorbs the idea of sample reconstruction to implicitly align the distribution gap, which enables DIDAN to learn both emotion discriminative and corpus invariant features from speech spectrums. To evaluate the proposed DIDAN, extensive cross-corpus SER experiments on widely-used speech emotion corpora are carried out. Experimental results show that the proposed DIDAN can outperform lots of recent state-of-the-art methods in coping with the cross-corpus SER tasks.