 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemoGen: Can Past Experience Improve Future Text-to-Image Generation?
Jun 02, 2026Modern text-to-image models have achieved strong visual synthesis, yet remain unreliable when prompts require implicit visual constraints, relational reasoning, or external knowledge. Existing retrieval-augmented and agentic generation methods mitigate this issue by acquiring external knowledge, references, or refined prompts for the current request, yet they typically treat each generation as an isolated episode and do not systematically preserve past successes or failures for future use. In this work, we ask whether a text-to-image system can continually improve from its own generation experience without updating the underlying generator. We propose MemoGen, a training-free framework that augments existing image generators with an agentic evolution layer. For each task, MemoGen explicitly infers visual requirements, retrieves external evidence and references when necessary, translates them into executable generation constraints, evaluates the generated result, and stores task understanding, reference choices, visual feedback, successful strategies, and failure lessons as reusable experience memory. Across evolution rounds, the agent retrieves relevant experience to improve similar future generations, selectively repairing previously failed cases while preserving successful ones, thereby enabling test-time self-evolution without parameter updates. Extensive experiments on knowledge-intensive and reasoning-oriented benchmarks demonstrate the effectiveness of this paradigm: after only two evolution rounds, MemoGen built upon the open-source Qwen-Image backbone surpasses strong proprietary systems such as Nano Banana Pro and GPT-Image-1 on WISE and Mind-Bench, showing that explicit experience memory can serve as a powerful continual learning signal for reliable text-to-image generation.
$Z^2$-Sampling: Zero-Cost Zigzag Trajectories for Semantic Alignment in Diffusion Models
Apr 26, 2026Diffusion models have achieved unprecedented success in text-aligned generation, largely driven by Classifier-Free Guidance (CFG). However, standard CFG operates strictly on instantaneous gradients, omitting the intrinsic curvature of the data manifold. Recent methods like Zigzag-sampling (Z-Sampling) explicitly traverse multi-step forward-backward trajectories to probe this curvature, significantly improving semantic alignment. Yet, these explicit traversals triple the Neural Function Evaluation (NFE) cost and introduce unconstrained truncation errors from off-manifold evaluations, causing cumulative drift from the true marginal distribution. In this paper, we theoretically demonstrate that the explicit zigzag sequence is topologically reducible. We propose Implicit Z-Sampling, rigorously proving that intermediate states can be algebraically annihilated via operator dualities, physically eliminating off-manifold approximation errors. To push sampling efficiency to its theoretical lower bound, we introduce $Z^2$-Sampling (Zero-cost Zigzag Sampling). Exploiting the Probability Flow ODE's temporal coherence, $Z^2$-Sampling couples implicit algebraic collapse with a dynamically cached Temporal Semantic Surrogate. This restores the standard 2-NFE baseline without sacrificing semantic exploration. We formally prove via Backward Error Analysis that this discrete collapse inherently synthesizes a directional derivative curvature penalty. Finally, extensive evaluations demonstrate that $Z^2$-Sampling structurally shatters the performance-efficiency Pareto frontier. We validate its universal applicability across diverse architectures (U-Nets, DiTs) and modalities (image/video), establishing seamless orthogonality with advanced alignment frameworks (AYS, Diffusion-DPO).
AULLM++: Structural Reasoning with Large Language Models for Micro-Expression Recognition
Mar 09, 2026Micro-expression Action Unit (AU) detection identifies localized AUs from subtle facial muscle activations, providing a foundation for decoding affective cues. Previous methods face three key limitations: (1) heavy reliance on low-density visual information, rendering discriminative evidence vulnerable to background noise; (2) coarse-grained feature processing that misaligns with the demand for fine-grained representations; and (3) neglect of inter-AU correlations, restricting the parsing of complex expression patterns. We propose AULLM++, a reasoning-oriented framework leveraging Large Language Models (LLMs), which injects visual features into textual prompts as actionable semantic premises to guide inference. It formulates AU prediction into three stages: evidence construction, structure modeling, and deduction-based prediction. Specifically, a Multi-Granularity Evidence-Enhanced Fusion Projector (MGE-EFP) fuses mid-level texture cues with high-level semantics, distilling them into a compact Content Token (CT). Furthermore, inspired by micro- and macro-expression AU correspondence, we encode AU relationships as a sparse structural prior and learn interaction strengths via a Relation-Aware AU Graph Neural Network (R-AUGNN), producing an Instruction Token (IT). We then fuse CT and IT into a structured textual prompt and introduce Counterfactual Consistency Regularization (CCR) to construct counterfactual samples, enhancing the model's generalization. Extensive experiments demonstrate AULLM++ achieves state-of-the-art performance on standard benchmarks and exhibits superior cross-domain generalization.
$Δ$VLA: Prior-Guided Vision-Language-Action Models via World Knowledge Variation
Mar 09, 2026Recent vision-language-action (VLA) models have significantly advanced robotic manipulation by unifying perception, reasoning, and control. To achieve such integration, recent studies adopt a predictive paradigm that models future visual states or world knowledge to guide action generation. However, these models emphasize forecasting outcomes rather than reasoning about the underlying process of change, which is essential for determining how to act. To address this, we propose $Δ$VLA, a prior-guided framework that models world-knowledge variations relative to an explicit current-world knowledge prior for action generation, rather than regressing absolute future world states. Specifically, 1) to construct the current world knowledge prior, we propose the Prior-Guided WorldKnowledge Extractor (PWKE). It extracts manipulable regions, spatial relations, and semantic cues from the visual input, guided by auxiliary heads and prior pseudo labels, thus reducing redundancy. 2) Building upon this, to represent how world knowledge evolves under actions, we introduce the Latent World Variation Quantization (LWVQ). It learns a discrete latent space via a VQ-VAE objective to encode world knowledge variations, shifting prediction from full modalities to compact latent. 3)Moreover, to mitigate interference during variation modeling, we design the Conditional Variation Attention (CV-Atten), whichpromotes disentangled learning and preserves the independence of knowledge representations. Extensive experiments on both simulated benchmarks and real-world robotic tasks demonstrate $Δ$VLA achieves state-of-the-art performance while improving efficiency. Code and real-world execution videos are available at https://github.com/JiuTian-VL/DeltaVLA.
AU-LLM: Micro-Expression Action Unit Detection via Enhanced LLM-Based Feature Fusion
Jul 29, 2025The detection of micro-expression Action Units (AUs) is a formidable challenge in affective computing, pivotal for decoding subtle, involuntary human emotions. While Large Language Models (LLMs) demonstrate profound reasoning abilities, their application to the fine-grained, low-intensity domain of micro-expression AU detection remains unexplored. This paper pioneers this direction by introducing \textbf{AU-LLM}, a novel framework that for the first time uses LLM to detect AUs in micro-expression datasets with subtle intensities and the scarcity of data. We specifically address the critical vision-language semantic gap, the \textbf{Enhanced Fusion Projector (EFP)}. The EFP employs a Multi-Layer Perceptron (MLP) to intelligently fuse mid-level (local texture) and high-level (global semantics) visual features from a specialized 3D-CNN backbone into a single, information-dense token. This compact representation effectively empowers the LLM to perform nuanced reasoning over subtle facial muscle movements.Through extensive evaluations on the benchmark CASME II and SAMM datasets, including stringent Leave-One-Subject-Out (LOSO) and cross-domain protocols, AU-LLM establishes a new state-of-the-art, validating the significant potential and robustness of LLM-based reasoning for micro-expression analysis. The codes are available at https://github.com/ZS-liu-JLU/AU-LLMs.
Period-LLM: Extending the Periodic Capability of Multimodal Large Language Model
May 30, 2025



Periodic or quasi-periodic phenomena reveal intrinsic characteristics in various natural processes, such as weather patterns, movement behaviors, traffic flows, and biological signals. Given that these phenomena span multiple modalities, the capabilities of Multimodal Large Language Models (MLLMs) offer promising potential to effectively capture and understand their complex nature. However, current MLLMs struggle with periodic tasks due to limitations in: 1) lack of temporal modelling and 2) conflict between short and long periods. This paper introduces Period-LLM, a multimodal large language model designed to enhance the performance of periodic tasks across various modalities, and constructs a benchmark of various difficulty for evaluating the cross-modal periodic capabilities of large models. Specially, We adopt an "Easy to Hard Generalization" paradigm, starting with relatively simple text-based tasks and progressing to more complex visual and multimodal tasks, ensuring that the model gradually builds robust periodic reasoning capabilities. Additionally, we propose a "Resisting Logical Oblivion" optimization strategy to maintain periodic reasoning abilities during semantic alignment. Extensive experiments demonstrate the superiority of the proposed Period-LLM over existing MLLMs in periodic tasks. The code is available at https://github.com/keke-nice/Period-LLM.
FEALLM: Advancing Facial Emotion Analysis in Multimodal Large Language Models with Emotional Synergy and Reasoning
May 19, 2025Facial Emotion Analysis (FEA) plays a crucial role in visual affective computing, aiming to infer a person's emotional state based on facial data. Scientifically, facial expressions (FEs) result from the coordinated movement of facial muscles, which can be decomposed into specific action units (AUs) that provide detailed emotional insights. However, traditional methods often struggle with limited interpretability, constrained generalization and reasoning abilities. Recently, Multimodal Large Language Models (MLLMs) have shown exceptional performance in various visual tasks, while they still face significant challenges in FEA due to the lack of specialized datasets and their inability to capture the intricate relationships between FEs and AUs. To address these issues, we introduce a novel FEA Instruction Dataset that provides accurate and aligned FE and AU descriptions and establishes causal reasoning relationships between them, followed by constructing a new benchmark, FEABench. Moreover, we propose FEALLM, a novel MLLM architecture designed to capture more detailed facial information, enhancing its capability in FEA tasks. Our model demonstrates strong performance on FEABench and impressive generalization capability through zero-shot evaluation on various datasets, including RAF-DB, AffectNet, BP4D, and DISFA, showcasing its robustness and effectiveness in FEA tasks. The dataset and code will be available at https://github.com/953206211/FEALLM.
AU-TTT: Vision Test-Time Training model for Facial Action Unit Detection
Mar 30, 2025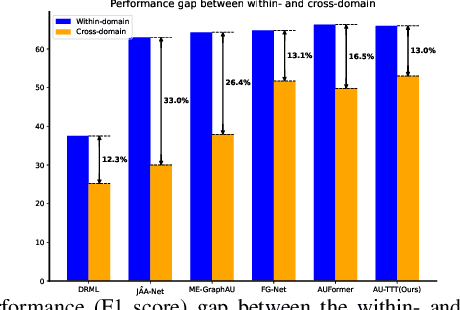
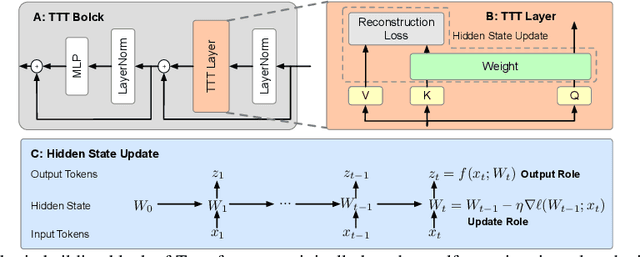
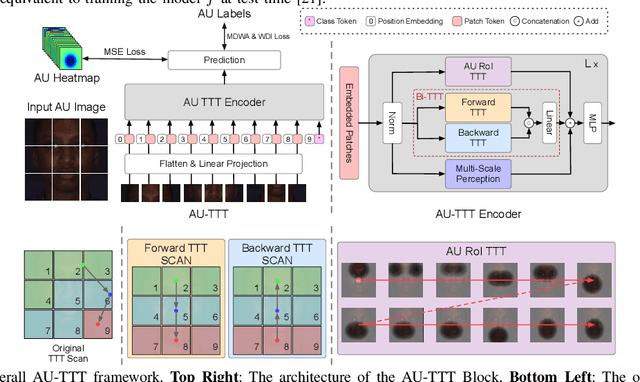
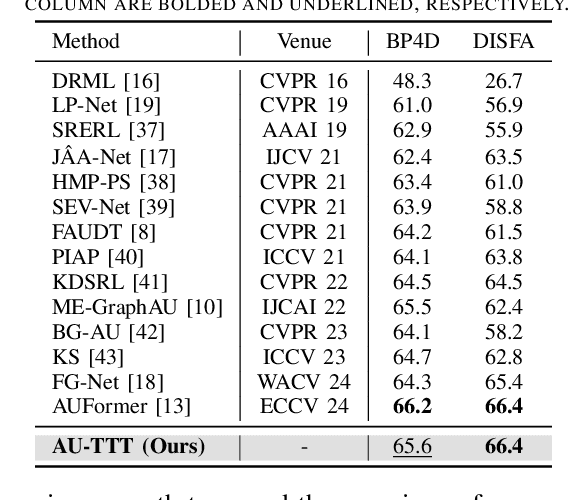
Facial Action Units (AUs) detection is a cornerstone of objective facial expression analysis and a critical focus in affective computing. Despite its importance, AU detection faces significant challenges, such as the high cost of AU annotation and the limited availability of datasets. These constraints often lead to overfitting in existing methods, resulting in substantial performance degradation when applied across diverse datasets. Addressing these issues is essential for improving the reliability and generalizability of AU detection methods. Moreover, many current approaches leverage Transformers for their effectiveness in long-context modeling, but they are hindered by the quadratic complexity of self-attention. Recently, Test-Time Training (TTT) layers have emerged as a promising solution for long-sequence modeling. Additionally, TTT applies self-supervised learning for iterative updates during both training and inference, offering a potential pathway to mitigate the generalization challenges inherent in AU detection tasks. In this paper, we propose a novel vision backbone tailored for AU detection, incorporating bidirectional TTT blocks, named AU-TTT. Our approach introduces TTT Linear to the AU detection task and optimizes image scanning mechanisms for enhanced performance. Additionally, we design an AU-specific Region of Interest (RoI) scanning mechanism to capture fine-grained facial features critical for AU detection. Experimental results demonstrate that our method achieves competitive performance in both within-domain and cross-domain scenarios.
EMO-LLaMA: Enhancing Facial Emotion Understanding with Instruction Tuning
Aug 21, 2024



Facial expression recognition (FER) is an important research topic in emotional artificial intelligence. In recent decades, researchers have made remarkable progress. However, current FER paradigms face challenges in generalization, lack semantic information aligned with natural language, and struggle to process both images and videos within a unified framework, making their application in multimodal emotion understanding and human-computer interaction difficult. Multimodal Large Language Models (MLLMs) have recently achieved success, offering advantages in addressing these issues and potentially overcoming the limitations of current FER paradigms. However, directly applying pre-trained MLLMs to FER still faces several challenges. Our zero-shot evaluations of existing open-source MLLMs on FER indicate a significant performance gap compared to GPT-4V and current supervised state-of-the-art (SOTA) methods. In this paper, we aim to enhance MLLMs' capabilities in understanding facial expressions. We first generate instruction data for five FER datasets with Gemini. We then propose a novel MLLM, named EMO-LLaMA, which incorporates facial priors from a pretrained facial analysis network to enhance human facial information. Specifically, we design a Face Info Mining module to extract both global and local facial information. Additionally, we utilize a handcrafted prompt to introduce age-gender-race attributes, considering the emotional differences across different human groups. Extensive experiments show that EMO-LLaMA achieves SOTA-comparable or competitive results across both static and dynamic FER datasets. The instruction dataset and code are available at https://github.com/xxtars/EMO-LLaMA.
GPT as Psychologist? Preliminary Evaluations for GPT-4V on Visual Affective Computing
Mar 09, 2024



Multimodal language models (MLMs) are designed to process and integrate information from multiple sources, such as text, speech, images, and videos. Despite its success in language understanding, it is critical to evaluate the performance of downstream tasks for better human-centric applications. This paper assesses the application of MLMs with 5 crucial abilities for affective computing, spanning from visual affective tasks and reasoning tasks. The results show that GPT4 has high accuracy in facial action unit recognition and micro-expression detection while its general facial expression recognition performance is not accurate. We also highlight the challenges of achieving fine-grained micro-expression recognition and the potential for further study and demonstrate the versatility and potential of GPT4 for handling advanced tasks in emotion recognition and related fields by integrating with task-related agents for more complex tasks, such as heart rate estimation through signal processing. In conclusion, this paper provides valuable insights into the potential applications and challenges of MLMs in human-centric computing. The interesting samples are available at \url{https://github.com/LuPaoPao/GPT4Affectivity}.