 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAVIS: Multi-Agent Video Retrieval via Structured Video Understanding
Jun 08, 2026The dominant paradigm in video retrieval relies on embedding-based full-corpus scanning, which suffers from inherent computational inefficiency and the semantic asymmetry between information-dense videos and sparse textual queries. To bridge this gap, we introduce \textbf{MAVIS}, a novel multi-agent framework that rethinks retrieval as cooperative reasoning rather than brute-force search. MAVIS first bridges the granularity mismatch by parsing raw videos into a \textbf{Structured Semantic Library}, enabling explicit attribute-level indexing. During retrieval, a planner decomposes complex user intents into atomic sub-tasks, dispatching specialized agents to independently nominate candidates. Crucially, MAVIS employs a \textbf{Logic-aware Debate} mechanism with a strict veto protocol, where agents collaboratively prune logical mismatches to identify a compact set of ``controversial'' candidates for fine-grained verification. This agentic workflow effectively bypasses the inefficiency of full-library traversal. Extensive experiments on MSR-VTT, MSVD, and ActivityNet demonstrate that MAVIS achieves competitive performance without task-specific fine-tuning, offering a scalable and interpretable alternative to traditional dual-encoder approaches.
Retrieving to Recover: Towards Incomplete Audio-Visual Question Answering via Semantic-consistent Purification
Apr 14, 2026Recent Audio-Visual Question Answering (AVQA) methods have advanced significantly. However, most AVQA methods lack effective mechanisms for handling missing modalities, suffering from severe performance degradation in real-world scenarios with data interruptions. Furthermore, prevailing methods for handling missing modalities predominantly rely on generative imputation to synthesize missing features. While partially effective, these methods tend to capture inter-modal commonalities but struggle to acquire unique, modality-specific knowledge within the missing data, leading to hallucinations and compromised reasoning accuracy. To tackle these challenges, we propose R$^{2}$ScP, a novel framework that shifts the paradigm of missing modality handling from traditional generative imputation to retrieval-based recovery. Specifically, we leverage cross-modal retrieval via unified semantic embeddings to acquire missing domain-specific knowledge. To maximize semantic restoration, we introduce a context-aware adaptive purification mechanism that eliminates latent semantic noise within the retrieved data. Additionally, we employ a two-stage training strategy to explicitly model the semantic relationships between knowledge from different sources. Extensive experiments demonstrate that R$^{2}$ScP significantly improves AVQA and enhances robustness in modal-incomplete scenarios.
SUGAR: Learning Skeleton Representation with Visual-Motion Knowledge for Action Recognition
Nov 13, 2025Large Language Models (LLMs) hold rich implicit knowledge and powerful transferability. In this paper, we explore the combination of LLMs with the human skeleton to perform action classification and description. However, when treating LLM as a recognizer, two questions arise: 1) How can LLMs understand skeleton? 2) How can LLMs distinguish among actions? To address these problems, we introduce a novel paradigm named learning Skeleton representation with visUal-motion knowledGe for Action Recognition (SUGAR). In our pipeline, we first utilize off-the-shelf large-scale video models as a knowledge base to generate visual, motion information related to actions. Then, we propose to supervise skeleton learning through this prior knowledge to yield discrete representations. Finally, we use the LLM with untouched pre-training weights to understand these representations and generate the desired action targets and descriptions. Notably, we present a Temporal Query Projection (TQP) module to continuously model the skeleton signals with long sequences. Experiments on several skeleton-based action classification benchmarks demonstrate the efficacy of our SUGAR. Moreover, experiments on zero-shot scenarios show that SUGAR is more versatile than linear-based methods.
When Eyes and Ears Disagree: Can MLLMs Discern Audio-Visual Confusion?
Nov 13, 2025Can Multimodal Large Language Models (MLLMs) discern confused objects that are visually present but audio-absent? To study this, we introduce a new benchmark, AV-ConfuseBench, which simulates an ``Audio-Visual Confusion'' scene by modifying the corresponding sound of an object in the video, e.g., mute the sounding object and ask MLLMs Is there a/an muted-object sound''. Experimental results reveal that MLLMs, such as Qwen2.5-Omni and Gemini 2.5, struggle to discriminate non-existent audio due to visually dominated reasoning. Motivated by this observation, we introduce RL-CoMM, a Reinforcement Learning-based Collaborative Multi-MLLM that is built upon the Qwen2.5-Omni foundation. RL-CoMM includes two stages: 1) To alleviate visually dominated ambiguities, we introduce an external model, a Large Audio Language Model (LALM), as the reference model to generate audio-only reasoning. Then, we design a Step-wise Reasoning Reward function that enables MLLMs to self-improve audio-visual reasoning with the audio-only reference. 2) To ensure an accurate answer prediction, we introduce Answer-centered Confidence Optimization to reduce the uncertainty of potential heterogeneous reasoning differences. Extensive experiments on audio-visual question answering and audio-visual hallucination show that RL-CoMM improves the accuracy by 10~30\% over the baseline model with limited training data. Follow: https://github.com/rikeilong/AVConfusion.
Task-Aware 3D Affordance Segmentation via 2D Guidance and Geometric Refinement
Nov 12, 2025Understanding 3D scene-level affordances from natural language instructions is essential for enabling embodied agents to interact meaningfully in complex environments. However, this task remains challenging due to the need for semantic reasoning and spatial grounding. Existing methods mainly focus on object-level affordances or merely lift 2D predictions to 3D, neglecting rich geometric structure information in point clouds and incurring high computational costs. To address these limitations, we introduce Task-Aware 3D Scene-level Affordance segmentation (TASA), a novel geometry-optimized framework that jointly leverages 2D semantic cues and 3D geometric reasoning in a coarse-to-fine manner. To improve the affordance detection efficiency, TASA features a task-aware 2D affordance detection module to identify manipulable points from language and visual inputs, guiding the selection of task-relevant views. To fully exploit 3D geometric information, a 3D affordance refinement module is proposed to integrate 2D semantic priors with local 3D geometry, resulting in accurate and spatially coherent 3D affordance masks. Experiments on SceneFun3D demonstrate that TASA significantly outperforms the baselines in both accuracy and efficiency in scene-level affordance segmentation.
EMO-LLaMA: Enhancing Facial Emotion Understanding with Instruction Tuning
Aug 21, 2024



Facial expression recognition (FER) is an important research topic in emotional artificial intelligence. In recent decades, researchers have made remarkable progress. However, current FER paradigms face challenges in generalization, lack semantic information aligned with natural language, and struggle to process both images and videos within a unified framework, making their application in multimodal emotion understanding and human-computer interaction difficult. Multimodal Large Language Models (MLLMs) have recently achieved success, offering advantages in addressing these issues and potentially overcoming the limitations of current FER paradigms. However, directly applying pre-trained MLLMs to FER still faces several challenges. Our zero-shot evaluations of existing open-source MLLMs on FER indicate a significant performance gap compared to GPT-4V and current supervised state-of-the-art (SOTA) methods. In this paper, we aim to enhance MLLMs' capabilities in understanding facial expressions. We first generate instruction data for five FER datasets with Gemini. We then propose a novel MLLM, named EMO-LLaMA, which incorporates facial priors from a pretrained facial analysis network to enhance human facial information. Specifically, we design a Face Info Mining module to extract both global and local facial information. Additionally, we utilize a handcrafted prompt to introduce age-gender-race attributes, considering the emotional differences across different human groups. Extensive experiments show that EMO-LLaMA achieves SOTA-comparable or competitive results across both static and dynamic FER datasets. The instruction dataset and code are available at https://github.com/xxtars/EMO-LLaMA.
Answering Diverse Questions via Text Attached with Key Audio-Visual Clues
Mar 11, 2024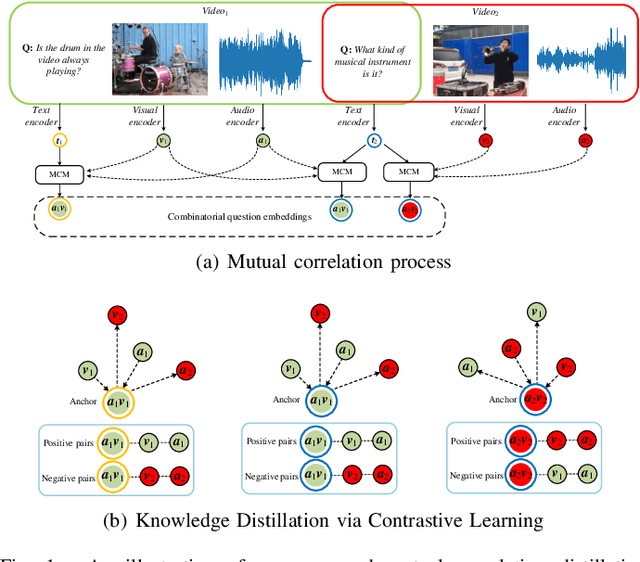



Audio-visual question answering (AVQA) requires reference to video content and auditory information, followed by correlating the question to predict the most precise answer. Although mining deeper layers of audio-visual information to interact with questions facilitates the multimodal fusion process, the redundancy of audio-visual parameters tends to reduce the generalization of the inference engine to multiple question-answer pairs in a single video. Indeed, the natural heterogeneous relationship between audiovisuals and text makes the perfect fusion challenging, to prevent high-level audio-visual semantics from weakening the network's adaptability to diverse question types, we propose a framework for performing mutual correlation distillation (MCD) to aid question inference. MCD is divided into three main steps: 1) firstly, the residual structure is utilized to enhance the audio-visual soft associations based on self-attention, then key local audio-visual features relevant to the question context are captured hierarchically by shared aggregators and coupled in the form of clues with specific question vectors. 2) Secondly, knowledge distillation is enforced to align audio-visual-text pairs in a shared latent space to narrow the cross-modal semantic gap. 3) And finally, the audio-visual dependencies are decoupled by discarding the decision-level integrations. We evaluate the proposed method on two publicly available datasets containing multiple question-and-answer pairs, i.e., Music-AVQA and AVQA. Experiments show that our method outperforms other state-of-the-art methods, and one interesting finding behind is that removing deep audio-visual features during inference can effectively mitigate overfitting. The source code is released at http://github.com/rikeilong/MCD-forAVQA.
CAT: Enhancing Multimodal Large Language Model to Answer Questions in Dynamic Audio-Visual Scenarios
Mar 07, 2024



This paper focuses on the challenge of answering questions in scenarios that are composed of rich and complex dynamic audio-visual components. Although existing Multimodal Large Language Models (MLLMs) can respond to audio-visual content, these responses are sometimes ambiguous and fail to describe specific audio-visual events. To overcome this limitation, we introduce the CAT, which enhances MLLM in three ways: 1) besides straightforwardly bridging audio and video, we design a clue aggregator that aggregates question-related clues in dynamic audio-visual scenarios to enrich the detailed knowledge required for large language models. 2) CAT is trained on a mixed multimodal dataset, allowing direct application in audio-visual scenarios. Notably, we collect an audio-visual joint instruction dataset named AVinstruct, to further enhance the capacity of CAT to model cross-semantic correlations. 3) we propose AI-assisted ambiguity-aware direct preference optimization, a strategy specialized in retraining the model to favor the non-ambiguity response and improve the ability to localize specific audio-visual objects. Extensive experimental results demonstrate that CAT outperforms existing methods on multimodal tasks, especially in Audio-Visual Question Answering (AVQA) tasks. The codes and the collected instructions are released at https://github.com/rikeilong/Bay-CAT.