 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIFFUMA: High-Fidelity Spatio-Temporal Video Prediction via Dual-Path Mamba and Diffusion Enhancement
Jul 09, 2025



Spatio-temporal video prediction plays a pivotal role in critical domains, ranging from weather forecasting to industrial automation. However, in high-precision industrial scenarios such as semiconductor manufacturing, the absence of specialized benchmark datasets severely hampers research on modeling and predicting complex processes. To address this challenge, we make a twofold contribution.First, we construct and release the Chip Dicing Lane Dataset (CHDL), the first public temporal image dataset dedicated to the semiconductor wafer dicing process. Captured via an industrial-grade vision system, CHDL provides a much-needed and challenging benchmark for high-fidelity process modeling, defect detection, and digital twin development.Second, we propose DIFFUMA, an innovative dual-path prediction architecture specifically designed for such fine-grained dynamics. The model captures global long-range temporal context through a parallel Mamba module, while simultaneously leveraging a diffusion module, guided by temporal features, to restore and enhance fine-grained spatial details, effectively combating feature degradation. Experiments demonstrate that on our CHDL benchmark, DIFFUMA significantly outperforms existing methods, reducing the Mean Squared Error (MSE) by 39% and improving the Structural Similarity (SSIM) from 0.926 to a near-perfect 0.988. This superior performance also generalizes to natural phenomena datasets. Our work not only delivers a new state-of-the-art (SOTA) model but, more importantly, provides the community with an invaluable data resource to drive future research in industrial AI.
FusionMamba: Dynamic Feature Enhancement for Multimodal Image Fusion with Mamba
Apr 15, 2024Multi-modal image fusion aims to combine information from different modes to create a single image with comprehensive information and detailed textures. However, fusion models based on convolutional neural networks encounter limitations in capturing global image features due to their focus on local convolution operations. Transformer-based models, while excelling in global feature modeling, confront computational challenges stemming from their quadratic complexity. Recently, the Selective Structured State Space Model has exhibited significant potential for long-range dependency modeling with linear complexity, offering a promising avenue to address the aforementioned dilemma. In this paper, we propose FusionMamba, a novel dynamic feature enhancement method for multimodal image fusion with Mamba. Specifically, we devise an improved efficient Mamba model for image fusion, integrating efficient visual state space model with dynamic convolution and channel attention. This refined model not only upholds the performance of Mamba and global modeling capability but also diminishes channel redundancy while enhancing local enhancement capability. Additionally, we devise a dynamic feature fusion module (DFFM) comprising two dynamic feature enhancement modules (DFEM) and a cross modality fusion mamba module (CMFM). The former serves for dynamic texture enhancement and dynamic difference perception, whereas the latter enhances correlation features between modes and suppresses redundant intermodal information. FusionMamba has yielded state-of-the-art (SOTA) performance across various multimodal medical image fusion tasks (CT-MRI, PET-MRI, SPECT-MRI), infrared and visible image fusion task (IR-VIS) and multimodal biomedical image fusion dataset (GFP-PC), which is proved that our model has generalization ability. The code for FusionMamba is available at https://github.com/millieXie/FusionMamba.
CAT: Enhancing Multimodal Large Language Model to Answer Questions in Dynamic Audio-Visual Scenarios
Mar 07, 2024



This paper focuses on the challenge of answering questions in scenarios that are composed of rich and complex dynamic audio-visual components. Although existing Multimodal Large Language Models (MLLMs) can respond to audio-visual content, these responses are sometimes ambiguous and fail to describe specific audio-visual events. To overcome this limitation, we introduce the CAT, which enhances MLLM in three ways: 1) besides straightforwardly bridging audio and video, we design a clue aggregator that aggregates question-related clues in dynamic audio-visual scenarios to enrich the detailed knowledge required for large language models. 2) CAT is trained on a mixed multimodal dataset, allowing direct application in audio-visual scenarios. Notably, we collect an audio-visual joint instruction dataset named AVinstruct, to further enhance the capacity of CAT to model cross-semantic correlations. 3) we propose AI-assisted ambiguity-aware direct preference optimization, a strategy specialized in retraining the model to favor the non-ambiguity response and improve the ability to localize specific audio-visual objects. Extensive experimental results demonstrate that CAT outperforms existing methods on multimodal tasks, especially in Audio-Visual Question Answering (AVQA) tasks. The codes and the collected instructions are released at https://github.com/rikeilong/Bay-CAT.
Massive Unsourced Random Access for Near-Field Communications
Jan 25, 2024

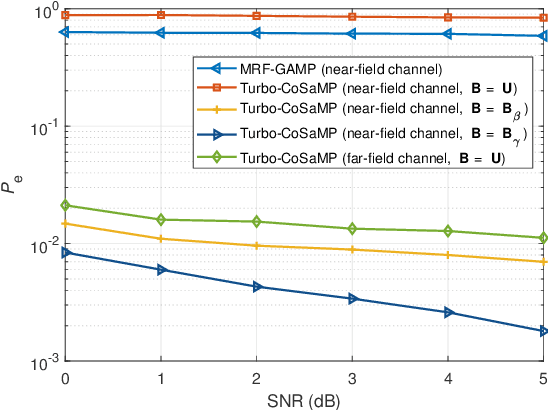

This paper investigates the unsourced random access (URA) problem with a massive multiple-input multiple-output receiver that serves wireless devices in the near-field of radiation. We employ an uncoupled transmission protocol without appending redundancies to the slot-wise encoded messages. To exploit the channel sparsity for block length reduction while facing the collapsed sparse structure in the angular domain of near-field channels, we propose a sparse channel sampling method that divides the angle-distance (polar) domain based on the maximum permissible coherence. Decoding starts with retrieving active codewords and channels from each slot. We address the issue by leveraging the structured channel sparsity in the spatial and polar domains and propose a novel turbo-based recovery algorithm. Furthermore, we investigate an off-grid compressed sensing method to refine discretely estimated channel parameters over the continuum that improves the detection performance. Afterward, without the assistance of redundancies, we recouple the separated messages according to the similarity of the users' channel information and propose a modified K-medoids method to handle the constraints and collisions involved in channel clustering. Simulations reveal that via exploiting the channel sparsity, the proposed URA scheme achieves high spectral efficiency and surpasses existing multi-slot-based schemes. Moreover, with more measurements provided by the overcomplete channel sampling, the near-field-suited scheme outperforms its counterpart of the far-field.
Scalable Multi-Task Gaussian Processes with Neural Embedding of Coregionalization
Sep 20, 2021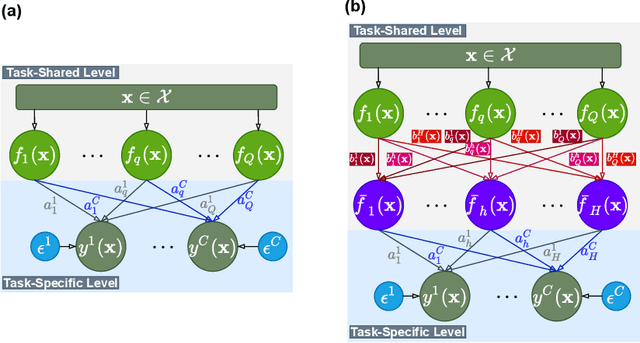
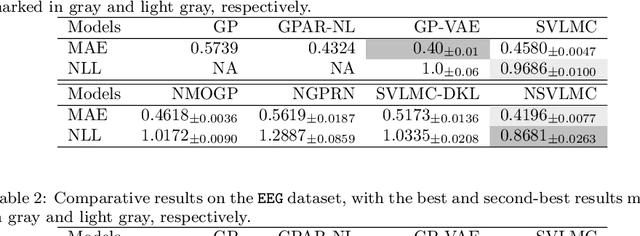
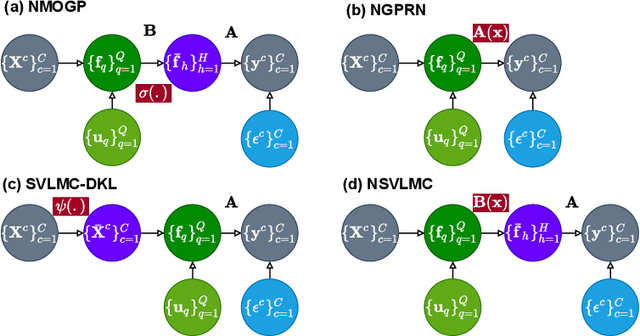
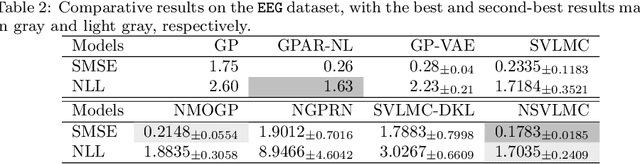
Multi-task regression attempts to exploit the task similarity in order to achieve knowledge transfer across related tasks for performance improvement. The application of Gaussian process (GP) in this scenario yields the non-parametric yet informative Bayesian multi-task regression paradigm. Multi-task GP (MTGP) provides not only the prediction mean but also the associated prediction variance to quantify uncertainty, thus gaining popularity in various scenarios. The linear model of coregionalization (LMC) is a well-known MTGP paradigm which exploits the dependency of tasks through linear combination of several independent and diverse GPs. The LMC however suffers from high model complexity and limited model capability when handling complicated multi-task cases. To this end, we develop the neural embedding of coregionalization that transforms the latent GPs into a high-dimensional latent space to induce rich yet diverse behaviors. Furthermore, we use advanced variational inference as well as sparse approximation to devise a tight and compact evidence lower bound (ELBO) for higher quality of scalable model inference. Extensive numerical experiments have been conducted to verify the higher prediction quality and better generalization of our model, named NSVLMC, on various real-world multi-task datasets and the cross-fluid modeling of unsteady fluidized bed.