 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFEMSN: Frequency-Enhanced Multiscale Network for fault diagnosis of rotating machinery under strong noise environments
May 07, 2025Rolling bearings are critical components of rotating machinery, and their proper functioning is essential for industrial production. Most existing condition monitoring methods focus on extracting discriminative features from time-domain signals to assess bearing health status. However, under complex operating conditions, periodic impulsive characteristics related to fault information are often obscured by noise interference. Consequently, existing approaches struggle to learn distinctive fault-related features in such scenarios. To address this issue, this paper proposes a novel CNN-based model named FEMSN. Specifically, a Fourier Adaptive Denoising Encoder Layer (FADEL) is introduced as an input denoising layer to enhance key features while filtering out irrelevant information. Subsequently, a Multiscale Time-Frequency Fusion (MSTFF) module is employed to extract fused time-frequency features, further improving the model robustness and nonlinear representation capability. Additionally, a distillation layer is incorporated to expand the receptive field. Based on these advancements, a novel deep lightweight CNN model, termed the Frequency-Enhanced Multiscale Network (FEMSN), is developed. The effectiveness of FEMSN and FADEL in machine health monitoring and stability assessment is validated through two case studies.
Learning Multi-Task Gaussian Process Over Heterogeneous Input Domains
Feb 25, 2022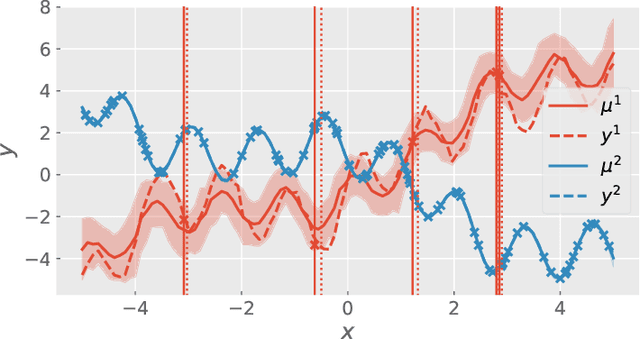
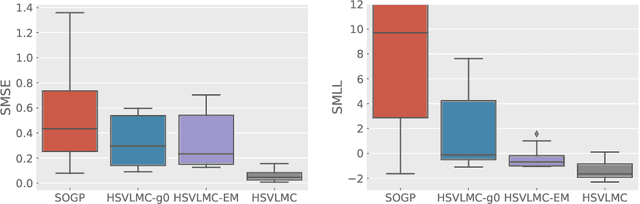
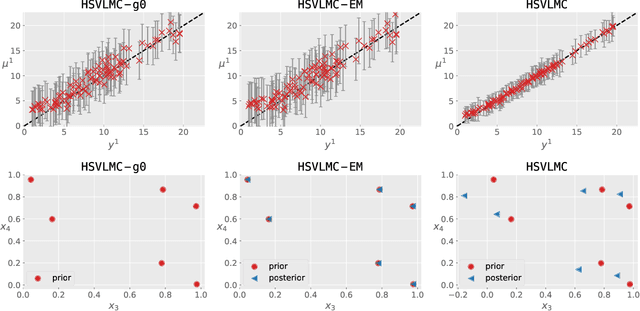
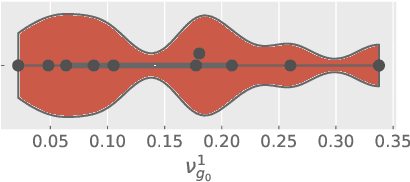
Multi-task Gaussian process (MTGP) is a well-known non-parametric Bayesian model for learning correlated tasks effectively by transferring knowledge across tasks. But current MTGP models are usually limited to the multi-task scenario defined in the same input domain, leaving no space for tackling the practical heterogeneous case, i.e., the features of input domains vary over tasks. To this end, this paper presents a novel heterogeneous stochastic variational linear model of coregionalization (HSVLMC) model for simultaneously learning the tasks with varied input domains. Particularly, we develop the stochastic variational framework with a Bayesian calibration method that (i) takes into account the effect of dimensionality reduction raised by domain mapping in order to achieve effective input alignment; and (ii) employs a residual modeling strategy to leverage the inductive bias brought by prior domain mappings for better model inference. Finally, the superiority of the proposed model against existing LMC models has been extensively verified on diverse heterogeneous multi-task cases.
Scalable Multi-Task Gaussian Processes with Neural Embedding of Coregionalization
Sep 20, 2021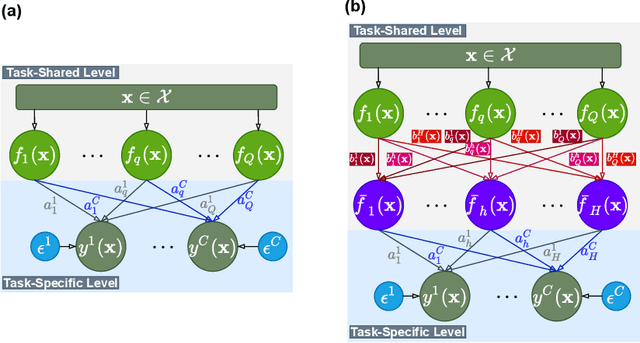
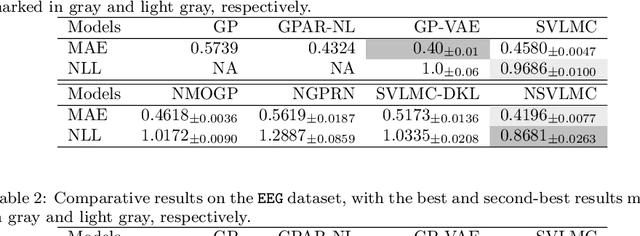
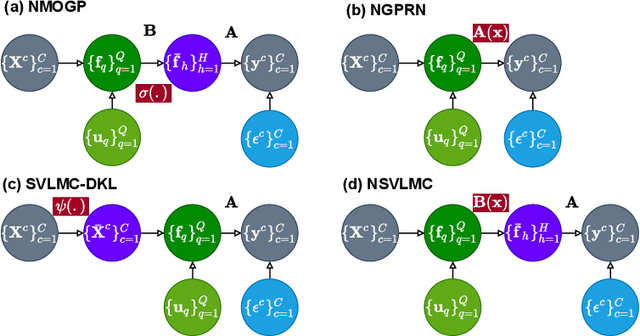
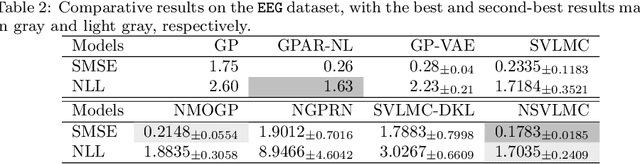
Multi-task regression attempts to exploit the task similarity in order to achieve knowledge transfer across related tasks for performance improvement. The application of Gaussian process (GP) in this scenario yields the non-parametric yet informative Bayesian multi-task regression paradigm. Multi-task GP (MTGP) provides not only the prediction mean but also the associated prediction variance to quantify uncertainty, thus gaining popularity in various scenarios. The linear model of coregionalization (LMC) is a well-known MTGP paradigm which exploits the dependency of tasks through linear combination of several independent and diverse GPs. The LMC however suffers from high model complexity and limited model capability when handling complicated multi-task cases. To this end, we develop the neural embedding of coregionalization that transforms the latent GPs into a high-dimensional latent space to induce rich yet diverse behaviors. Furthermore, we use advanced variational inference as well as sparse approximation to devise a tight and compact evidence lower bound (ELBO) for higher quality of scalable model inference. Extensive numerical experiments have been conducted to verify the higher prediction quality and better generalization of our model, named NSVLMC, on various real-world multi-task datasets and the cross-fluid modeling of unsteady fluidized bed.
Deep Probabilistic Time Series Forecasting using Augmented Recurrent Input for Dynamic Systems
Jun 03, 2021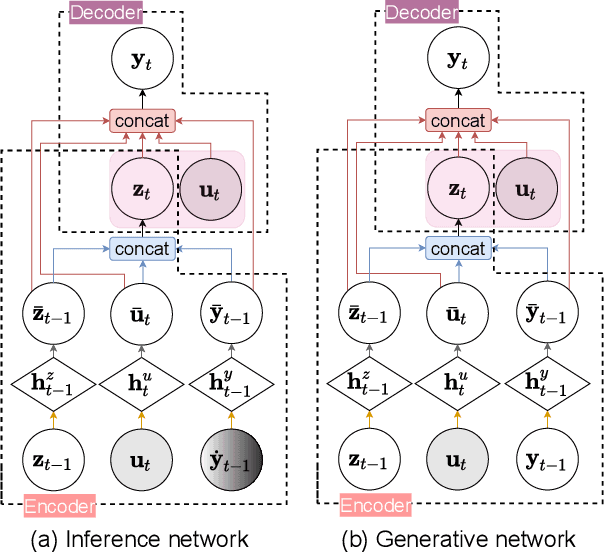

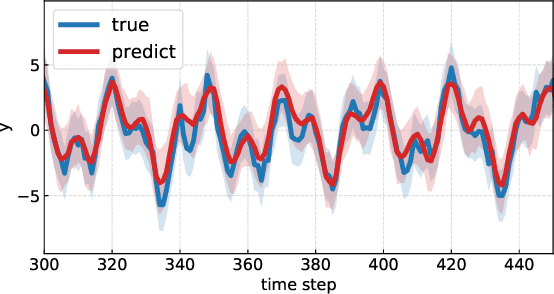
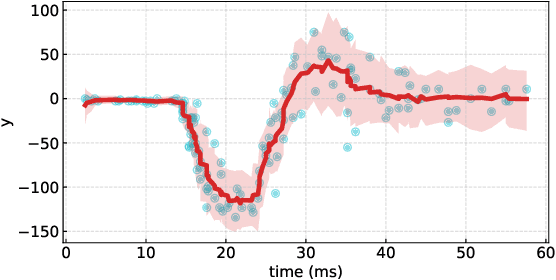
The demand of probabilistic time series forecasting has been recently raised in various dynamic system scenarios, for example, system identification and prognostic and health management of machines. To this end, we combine the advances in both deep generative models and state space model (SSM) to come up with a novel, data-driven deep probabilistic sequence model. Specially, we follow the popular encoder-decoder generative structure to build the recurrent neural networks (RNN) assisted variational sequence model on an augmented recurrent input space, which could induce rich stochastic sequence dependency. Besides, in order to alleviate the issue of inconsistency between training and predicting as well as improving the mining of dynamic patterns, we (i) propose using a hybrid output as input at next time step, which brings training and predicting into alignment; and (ii) further devise a generalized auto-regressive strategy that encodes all the historical dependencies at current time step. Thereafter, we first investigate the methodological characteristics of the proposed deep probabilistic sequence model on toy cases, and then comprehensively demonstrate the superiority of our model against existing deep probabilistic SSM models through extensive numerical experiments on eight system identification benchmarks from various dynamic systems. Finally, we apply our sequence model to a real-world centrifugal compressor sensor data forecasting problem, and again verify its outstanding performance by quantifying the time series predictive distribution.
Modulating Scalable Gaussian Processes for Expressive Statistical Learning
Aug 29, 2020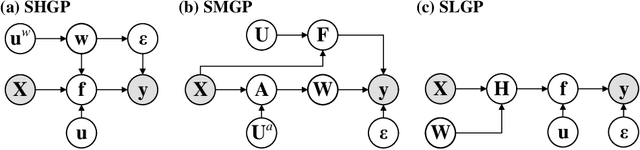

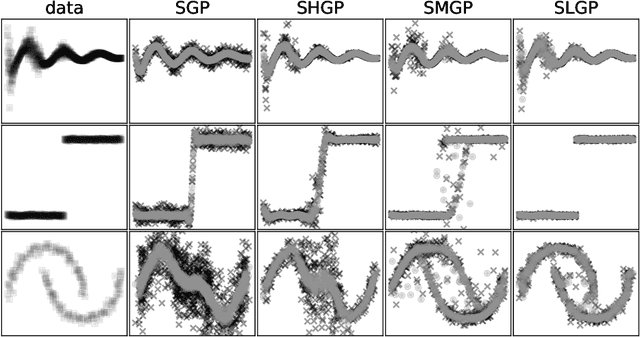
For a learning task, Gaussian process (GP) is interested in learning the statistical relationship between inputs and outputs, since it offers not only the prediction mean but also the associated variability. The vanilla GP however struggles to learn complicated distribution with the property of, e.g., heteroscedastic noise, multi-modality and non-stationarity, from massive data due to the Gaussian marginal and the cubic complexity. To this end, this article studies new scalable GP paradigms including the non-stationary heteroscedastic GP, the mixture of GPs and the latent GP, which introduce additional latent variables to modulate the outputs or inputs in order to learn richer, non-Gaussian statistical representation. We further resort to different variational inference strategies to arrive at analytical or tighter evidence lower bounds (ELBOs) of the marginal likelihood for efficient and effective model training. Extensive numerical experiments against state-of-the-art GP and neural network (NN) counterparts on various tasks verify the superiority of these scalable modulated GPs, especially the scalable latent GP, for learning diverse data distributions.
Deep Latent-Variable Kernel Learning
May 18, 2020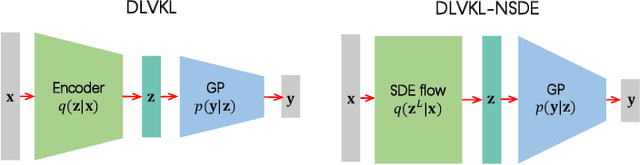
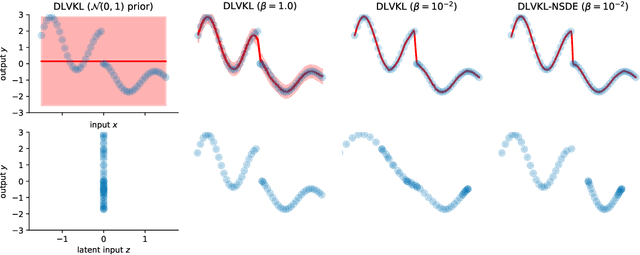
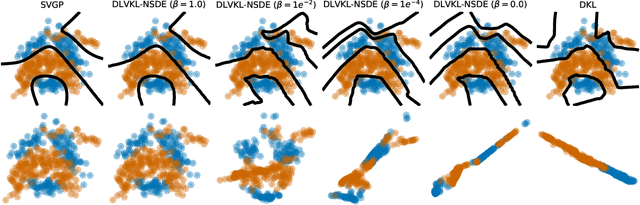
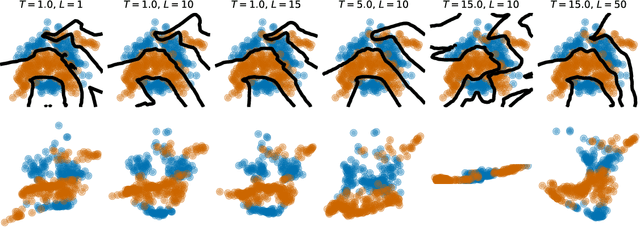
Deep kernel learning (DKL) leverages the connection between Gaussian process (GP) and neural networks (NN) to build an end-to-end, hybrid model. It combines the capability of NN to learn rich representations under massive data and the non-parametric property of GP to achieve automatic calibration. However, the deterministic encoder may weaken the model calibration of the following GP part, especially on small datasets, due to the free latent representation. We therefore present a complete deep latent-variable kernel learning (DLVKL) model wherein the latent variables perform stochastic encoding for regularized representation. Theoretical analysis however indicates that the DLVKL with i.i.d. prior for latent variables suffers from posterior collapse and degenerates to a constant predictor. Hence, we further enhance the DLVKL from two aspects: (i) the complicated variational posterior through neural stochastic differential equation (NSDE) to reduce the divergence gap, and (ii) the hybrid prior taking knowledge from both the SDE prior and the posterior to arrive at a flexible trade-off. Intensive experiments imply that the DLVKL-NSDE performs similarly to the well calibrated GP on small datasets, and outperforms existing deep GPs on large datasets.