 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnswering Diverse Questions via Text Attached with Key Audio-Visual Clues
Paper and Code
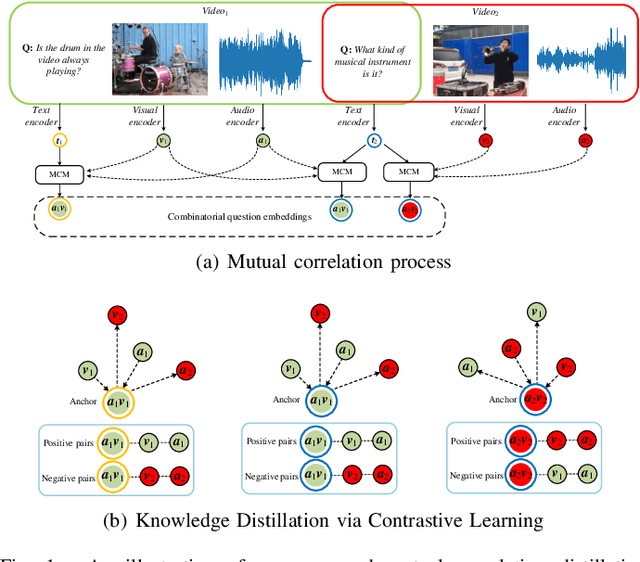



Audio-visual question answering (AVQA) requires reference to video content and auditory information, followed by correlating the question to predict the most precise answer. Although mining deeper layers of audio-visual information to interact with questions facilitates the multimodal fusion process, the redundancy of audio-visual parameters tends to reduce the generalization of the inference engine to multiple question-answer pairs in a single video. Indeed, the natural heterogeneous relationship between audiovisuals and text makes the perfect fusion challenging, to prevent high-level audio-visual semantics from weakening the network's adaptability to diverse question types, we propose a framework for performing mutual correlation distillation (MCD) to aid question inference. MCD is divided into three main steps: 1) firstly, the residual structure is utilized to enhance the audio-visual soft associations based on self-attention, then key local audio-visual features relevant to the question context are captured hierarchically by shared aggregators and coupled in the form of clues with specific question vectors. 2) Secondly, knowledge distillation is enforced to align audio-visual-text pairs in a shared latent space to narrow the cross-modal semantic gap. 3) And finally, the audio-visual dependencies are decoupled by discarding the decision-level integrations. We evaluate the proposed method on two publicly available datasets containing multiple question-and-answer pairs, i.e., Music-AVQA and AVQA. Experiments show that our method outperforms other state-of-the-art methods, and one interesting finding behind is that removing deep audio-visual features during inference can effectively mitigate overfitting. The source code is released at http://github.com/rikeilong/MCD-forAVQA.