 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAU-TTT: Vision Test-Time Training model for Facial Action Unit Detection
Paper and Code
Mar 30, 2025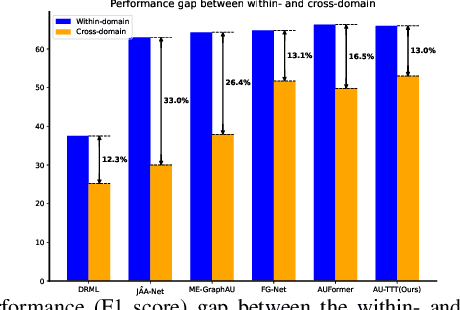
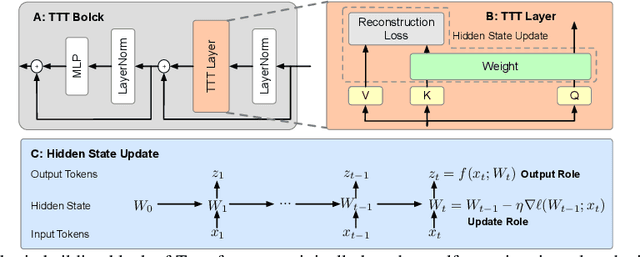
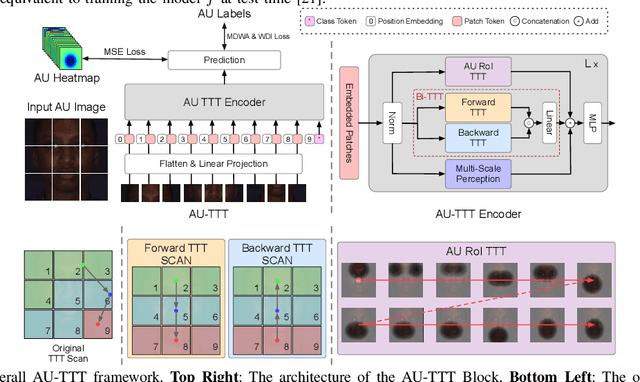
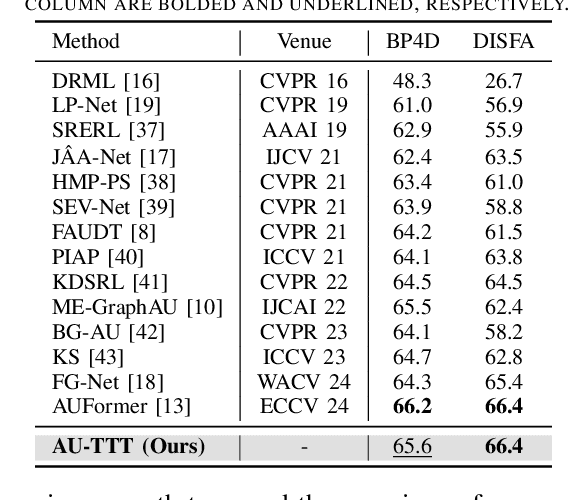
Facial Action Units (AUs) detection is a cornerstone of objective facial expression analysis and a critical focus in affective computing. Despite its importance, AU detection faces significant challenges, such as the high cost of AU annotation and the limited availability of datasets. These constraints often lead to overfitting in existing methods, resulting in substantial performance degradation when applied across diverse datasets. Addressing these issues is essential for improving the reliability and generalizability of AU detection methods. Moreover, many current approaches leverage Transformers for their effectiveness in long-context modeling, but they are hindered by the quadratic complexity of self-attention. Recently, Test-Time Training (TTT) layers have emerged as a promising solution for long-sequence modeling. Additionally, TTT applies self-supervised learning for iterative updates during both training and inference, offering a potential pathway to mitigate the generalization challenges inherent in AU detection tasks. In this paper, we propose a novel vision backbone tailored for AU detection, incorporating bidirectional TTT blocks, named AU-TTT. Our approach introduces TTT Linear to the AU detection task and optimizes image scanning mechanisms for enhanced performance. Additionally, we design an AU-specific Region of Interest (RoI) scanning mechanism to capture fine-grained facial features critical for AU detection. Experimental results demonstrate that our method achieves competitive performance in both within-domain and cross-domain scenarios.