 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Token-Trained Models into Byte-Level Models
Feb 01, 2026Byte Language Models (BLMs) have emerged as a promising direction for scaling language models beyond tokenization. However, existing BLMs typically require training from scratch on trillions of bytes, making them prohibitively expensive. In this paper, we propose an efficient distillation recipe that converts existing token-trained LLMs into BLMs while retaining comparable capabilities. Our recipe follows a two-stage curriculum: (1) Progressive Knowledge Distillation, which aligns byte-level representations with the embeddings of the token-trained teacher model; and (2) Byte-Level Supervised Fine-Tuning, which enables end-to-end generation entirely in the byte space. We validate our approach across multiple model families, including Llama, Qwen, and OLMo, and demonstrate that the distilled BLMs retain most of the teacher models' performance using only approximately 125B bytes.
Fifty Years of SAR Automatic Target Recognition: The Road Forward
Sep 26, 2025This paper provides the first comprehensive review of fifty years of synthetic aperture radar automatic target recognition (SAR ATR) development, tracing its evolution from inception to the present day. Central to our analysis is the inheritance and refinement of traditional methods, such as statistical modeling, scattering center analysis, and feature engineering, within modern deep learning frameworks. The survey clearly distinguishes long-standing challenges that have been substantially mitigated by deep learning from newly emerging obstacles. We synthesize recent advances in physics-guided deep learning and propose future directions toward more generalizable and physically-consistent SAR ATR. Additionally, we provide a systematically organized compilation of all publicly available SAR datasets, complete with direct links to support reproducibility and benchmarking. This work not only documents the technical evolution of the field but also offers practical resources and forward-looking insights for researchers and practitioners. A systematic summary of existing literature, code, and datasets are open-sourced at \href{https://github.com/JoyeZLearning/SAR-ATR-From-Beginning-to-Present}{https://github.com/JoyeZLearning/SAR-ATR-From-Beginning-to-Present}.
DeMo: Decoupled Momentum Optimization
Nov 29, 2024Training large neural networks typically requires sharing gradients between accelerators through specialized high-speed interconnects. Drawing from the signal processing principles of frequency decomposition and energy compaction, we demonstrate that synchronizing full optimizer states and model parameters during training is unnecessary. By decoupling momentum updates and allowing controlled divergence in optimizer states across accelerators, we achieve improved convergence compared to state-of-the-art optimizers. We introduce {\textbf{De}}coupled {\textbf{Mo}}mentum (DeMo), a fused optimizer and data parallel algorithm that reduces inter-accelerator communication requirements by several orders of magnitude. This enables training of large neural networks even with limited network bandwidth and heterogeneous hardware. Our method is topology-agnostic and architecture-independent and supports scalable clock-synchronous distributed training with negligible compute and memory overhead. Empirical results show that models trained with DeMo match or exceed the performance of equivalent models trained with AdamW, while eliminating the need for high-speed interconnects when pre-training large scale foundation models. An open source reference PyTorch implementation is published on GitHub at https://github.com/bloc97/DeMo
MaDiNet: Mamba Diffusion Network for SAR Target Detection
Nov 12, 2024



The fundamental challenge in SAR target detection lies in developing discriminative, efficient, and robust representations of target characteristics within intricate non-cooperative environments. However, accurate target detection is impeded by factors including the sparse distribution and discrete features of the targets, as well as complex background interference. In this study, we propose a \textbf{Ma}mba \textbf{Di}ffusion \textbf{Net}work (MaDiNet) for SAR target detection. Specifically, MaDiNet conceptualizes SAR target detection as the task of generating the position (center coordinates) and size (width and height) of the bounding boxes in the image space. Furthermore, we design a MambaSAR module to capture intricate spatial structural information of targets and enhance the capability of the model to differentiate between targets and complex backgrounds. The experimental results on extensive SAR target detection datasets achieve SOTA, proving the effectiveness of the proposed network. Code is available at \href{https://github.com/JoyeZLearning/MaDiNet}{https://github.com/JoyeZLearning/MaDiNet}.
Enhancing Transferability of Targeted Adversarial Examples: A Self-Universal Perspective
Jul 22, 2024Transfer-based targeted adversarial attacks against black-box deep neural networks (DNNs) have been proven to be significantly more challenging than untargeted ones. The impressive transferability of current SOTA, the generative methods, comes at the cost of requiring massive amounts of additional data and time-consuming training for each targeted label. This results in limited efficiency and flexibility, significantly hindering their deployment in practical applications. In this paper, we offer a self-universal perspective that unveils the great yet underexplored potential of input transformations in pursuing this goal. Specifically, transformations universalize gradient-based attacks with intrinsic but overlooked semantics inherent within individual images, exhibiting similar scalability and comparable results to time-consuming learning over massive additional data from diverse classes. We also contribute a surprising empirical insight that one of the most fundamental transformations, simple image scaling, is highly effective, scalable, sufficient, and necessary in enhancing targeted transferability. We further augment simple scaling with orthogonal transformations and block-wise applicability, resulting in the Simple, faSt, Self-universal yet Strong Scale Transformation (S$^4$ST) for self-universal TTA. On the ImageNet-Compatible benchmark dataset, our method achieves a 19.8% improvement in the average targeted transfer success rate against various challenging victim models over existing SOTA transformation methods while only consuming 36% time for attacking. It also outperforms resource-intensive attacks by a large margin in various challenging settings.
Towards Assessing the Synthetic-to-Measured Adversarial Vulnerability of SAR ATR
Jan 30, 2024Recently, there has been increasing concern about the vulnerability of deep neural network (DNN)-based synthetic aperture radar (SAR) automatic target recognition (ATR) to adversarial attacks, where a DNN could be easily deceived by clean input with imperceptible but aggressive perturbations. This paper studies the synthetic-to-measured (S2M) transfer setting, where an attacker generates adversarial perturbation based solely on synthetic data and transfers it against victim models trained with measured data. Compared with the current measured-to-measured (M2M) transfer setting, our approach does not need direct access to the victim model or the measured SAR data. We also propose the transferability estimation attack (TEA) to uncover the adversarial risks in this more challenging and practical scenario. The TEA makes full use of the limited similarity between the synthetic and measured data pairs for blind estimation and optimization of S2M transferability, leading to feasible surrogate model enhancement without mastering the victim model and data. Comprehensive evaluations based on the publicly available synthetic and measured paired labeled experiment (SAMPLE) dataset demonstrate that the TEA outperforms state-of-the-art methods and can significantly enhance various attack algorithms in computer vision and remote sensing applications. Codes and data are available at https://github.com/scenarri/S2M-TEA.
ARBiBench: Benchmarking Adversarial Robustness of Binarized Neural Networks
Dec 21, 2023



Network binarization exhibits great potential for deployment on resource-constrained devices due to its low computational cost. Despite the critical importance, the security of binarized neural networks (BNNs) is rarely investigated. In this paper, we present ARBiBench, a comprehensive benchmark to evaluate the robustness of BNNs against adversarial perturbations on CIFAR-10 and ImageNet. We first evaluate the robustness of seven influential BNNs on various white-box and black-box attacks. The results reveal that 1) The adversarial robustness of BNNs exhibits a completely opposite performance on the two datasets under white-box attacks. 2) BNNs consistently exhibit better adversarial robustness under black-box attacks. 3) Different BNNs exhibit certain similarities in their robustness performance. Then, we conduct experiments to analyze the adversarial robustness of BNNs based on these insights. Our research contributes to inspiring future research on enhancing the robustness of BNNs and advancing their application in real-world scenarios.
YaRN: Efficient Context Window Extension of Large Language Models
Aug 31, 2023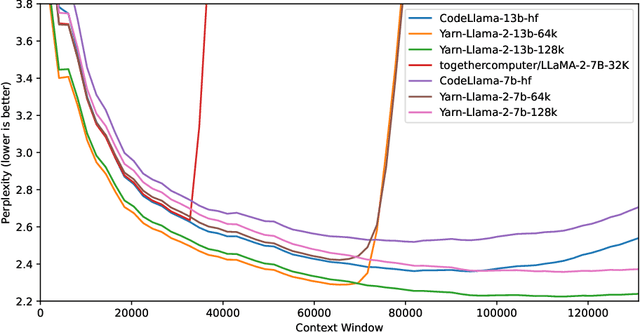


Rotary Position Embeddings (RoPE) have been shown to effectively encode positional information in transformer-based language models. However, these models fail to generalize past the sequence length they were trained on. We present YaRN (Yet another RoPE extensioN method), a compute-efficient method to extend the context window of such models, requiring 10x less tokens and 2.5x less training steps than previous methods. Using YaRN, we show that LLaMA models can effectively utilize and extrapolate to context lengths much longer than their original pre-training would allow, while also surpassing previous the state-of-the-art at context window extension. In addition, we demonstrate that YaRN exhibits the capability to extrapolate beyond the limited context of a fine-tuning dataset. We publish the checkpoints of Llama 2 7B/13B fine-tuned using YaRN with 64k and 128k context windows at https://github.com/jquesnelle/yarn
Learning Invariant Representation via Contrastive Feature Alignment for Clutter Robust SAR Target Recognition
Apr 04, 2023
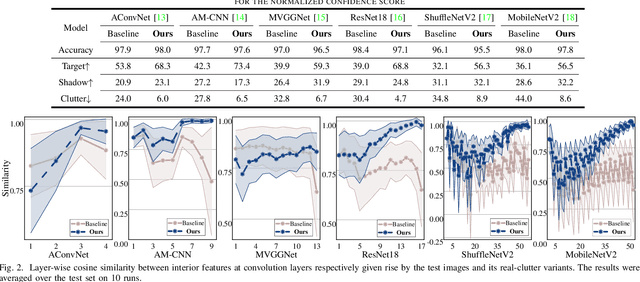


The deep neural networks (DNNs) have freed the synthetic aperture radar automatic target recognition (SAR ATR) from expertise-based feature designing and demonstrated superiority over conventional solutions. There has been shown the unique deficiency of ground vehicle benchmarks in shapes of strong background correlation results in DNNs overfitting the clutter and being non-robust to unfamiliar surroundings. However, the gap between fixed background model training and varying background application remains underexplored. Inspired by contrastive learning, this letter proposes a solution called Contrastive Feature Alignment (CFA) aiming to learn invariant representation for robust recognition. The proposed method contributes a mixed clutter variants generation strategy and a new inference branch equipped with channel-weighted mean square error (CWMSE) loss for invariant representation learning. In specific, the generation strategy is delicately designed to better attract clutter-sensitive deviation in feature space. The CWMSE loss is further devised to better contrast this deviation and align the deep features activated by the original images and corresponding clutter variants. The proposed CFA combines both classification and CWMSE losses to train the model jointly, which allows for the progressive learning of invariant target representation. Extensive evaluations on the MSTAR dataset and six DNN models prove the effectiveness of our proposal. The results demonstrated that the CFA-trained models are capable of recognizing targets among unfamiliar surroundings that are not included in the dataset, and are robust to varying signal-to-clutter ratios.
Scattering Model Guided Adversarial Examples for SAR Target Recognition: Attack and Defense
Sep 11, 2022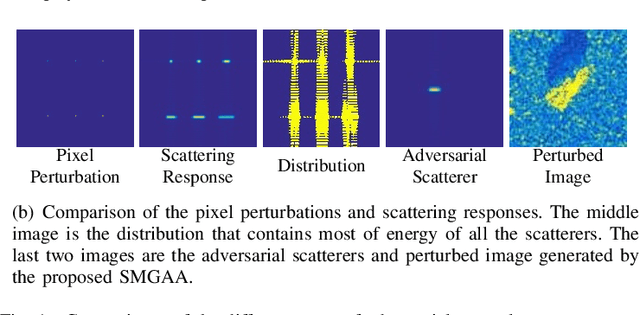
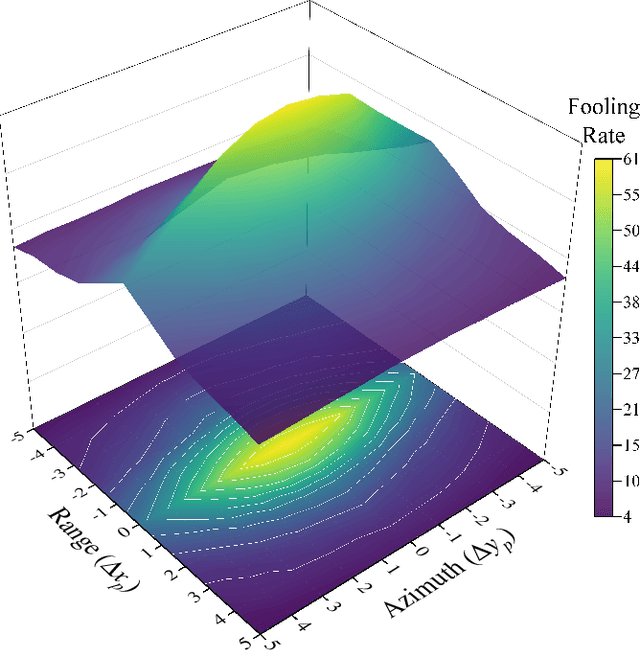
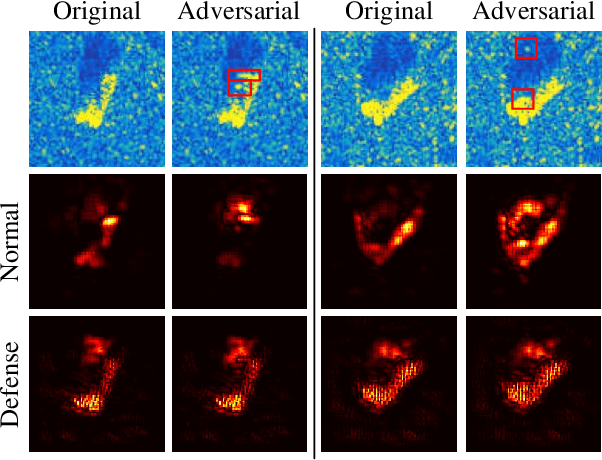
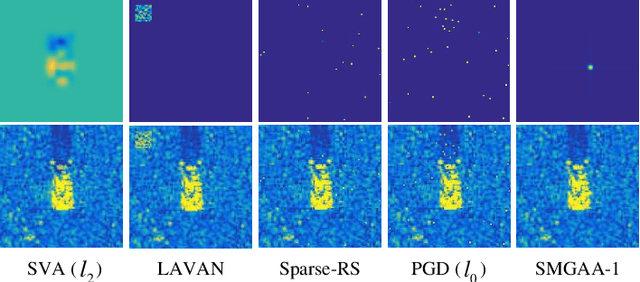
Deep Neural Networks (DNNs) based Synthetic Aperture Radar (SAR) Automatic Target Recognition (ATR) systems have shown to be highly vulnerable to adversarial perturbations that are deliberately designed yet almost imperceptible but can bias DNN inference when added to targeted objects. This leads to serious safety concerns when applying DNNs to high-stake SAR ATR applications. Therefore, enhancing the adversarial robustness of DNNs is essential for implementing DNNs to modern real-world SAR ATR systems. Toward building more robust DNN-based SAR ATR models, this article explores the domain knowledge of SAR imaging process and proposes a novel Scattering Model Guided Adversarial Attack (SMGAA) algorithm which can generate adversarial perturbations in the form of electromagnetic scattering response (called adversarial scatterers). The proposed SMGAA consists of two parts: 1) a parametric scattering model and corresponding imaging method and 2) a customized gradient-based optimization algorithm. First, we introduce the effective Attributed Scattering Center Model (ASCM) and a general imaging method to describe the scattering behavior of typical geometric structures in the SAR imaging process. By further devising several strategies to take the domain knowledge of SAR target images into account and relax the greedy search procedure, the proposed method does not need to be prudentially finetuned, but can efficiently to find the effective ASCM parameters to fool the SAR classifiers and facilitate the robust model training. Comprehensive evaluations on the MSTAR dataset show that the adversarial scatterers generated by SMGAA are more robust to perturbations and transformations in the SAR processing chain than the currently studied attacks, and are effective to construct a defensive model against the malicious scatterers.