 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurvaDion: Curvature-Adaptive Distributed Orthonormalization
Dec 13, 2025As language models scale to trillions of parameters, distributed training across many GPUs becomes essential, yet gradient synchronization over high-bandwidth, low-latency networks remains a critical bottleneck. While recent methods like Dion reduce per-step communication through low-rank updates, they synchronize at every step regardless of the optimization landscape. We observe that synchronization requirements vary dramatically throughout training: workers naturally compute similar gradients in flat regions, making frequent synchronization redundant, while high-curvature regions require coordination to prevent divergence. We introduce CurvaDion, which uses Relative Maximum Momentum Change (RMMC) to detect high-curvature regions requiring synchronization. RMMC leverages momentum dynamics which are already computed during optimization as a computationally tractable proxy for directional curvature, adding only $\mathcal{O}(d)$ operations per layer. We establish theoretical connections between RMMC and loss curvature and demonstrate that CurvaDion achieves 99\% communication reduction while matching baseline convergence across models from 160M to 1.3B parameters.
Hermes 4 Technical Report
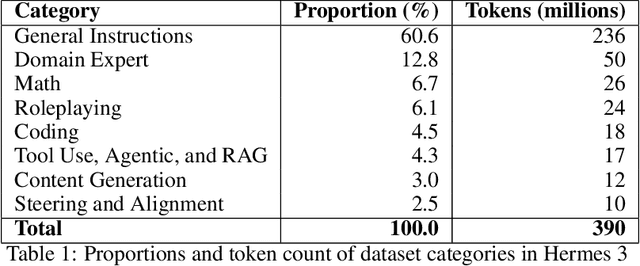
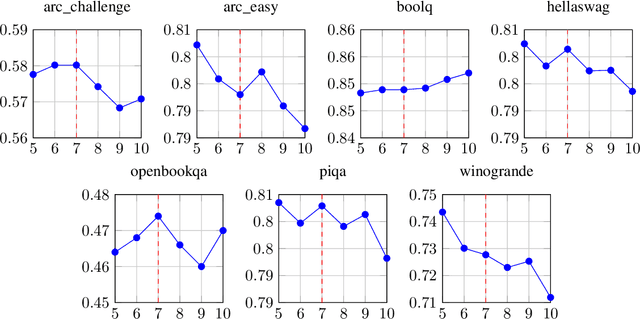
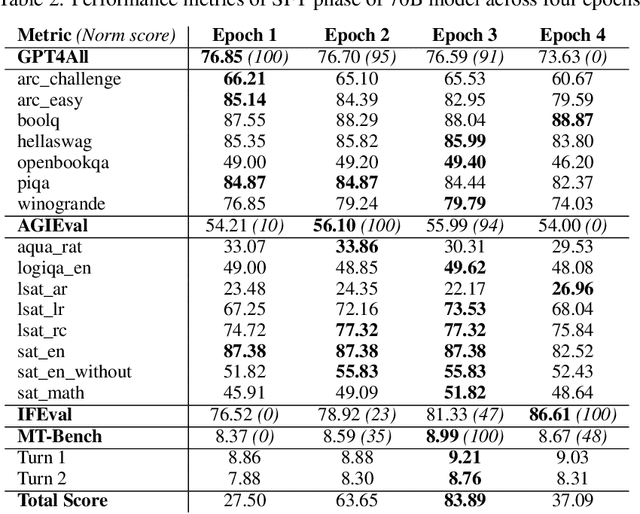
Aug 25, 2025We present Hermes 4, a family of hybrid reasoning models that combine structured, multi-turn reasoning with broad instruction-following ability. We describe the challenges encountered during data curation, synthesis, training, and evaluation, and outline the solutions employed to address these challenges at scale. We comprehensively evaluate across mathematical reasoning, coding, knowledge, comprehension, and alignment benchmarks, and we report both quantitative performance and qualitative behavioral analysis. To support open research, all model weights are published publicly at https://huggingface.co/collections/NousResearch/hermes-4-collection-68a731bfd452e20816725728
DeMo: Decoupled Momentum Optimization
Nov 29, 2024Training large neural networks typically requires sharing gradients between accelerators through specialized high-speed interconnects. Drawing from the signal processing principles of frequency decomposition and energy compaction, we demonstrate that synchronizing full optimizer states and model parameters during training is unnecessary. By decoupling momentum updates and allowing controlled divergence in optimizer states across accelerators, we achieve improved convergence compared to state-of-the-art optimizers. We introduce {\textbf{De}}coupled {\textbf{Mo}}mentum (DeMo), a fused optimizer and data parallel algorithm that reduces inter-accelerator communication requirements by several orders of magnitude. This enables training of large neural networks even with limited network bandwidth and heterogeneous hardware. Our method is topology-agnostic and architecture-independent and supports scalable clock-synchronous distributed training with negligible compute and memory overhead. Empirical results show that models trained with DeMo match or exceed the performance of equivalent models trained with AdamW, while eliminating the need for high-speed interconnects when pre-training large scale foundation models. An open source reference PyTorch implementation is published on GitHub at https://github.com/bloc97/DeMo
Hermes 3 Technical Report
Aug 15, 2024
Instruct (or "chat") tuned models have become the primary way in which most people interact with large language models. As opposed to "base" or "foundation" models, instruct-tuned models are optimized to respond to imperative statements. We present Hermes 3, a neutrally-aligned generalist instruct and tool use model with strong reasoning and creative abilities. Its largest version, Hermes 3 405B, achieves state of the art performance among open weight models on several public benchmarks.
YaRN: Efficient Context Window Extension of Large Language Models
Aug 31, 2023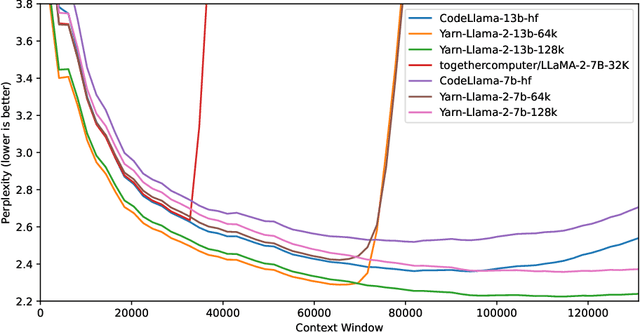


Rotary Position Embeddings (RoPE) have been shown to effectively encode positional information in transformer-based language models. However, these models fail to generalize past the sequence length they were trained on. We present YaRN (Yet another RoPE extensioN method), a compute-efficient method to extend the context window of such models, requiring 10x less tokens and 2.5x less training steps than previous methods. Using YaRN, we show that LLaMA models can effectively utilize and extrapolate to context lengths much longer than their original pre-training would allow, while also surpassing previous the state-of-the-art at context window extension. In addition, we demonstrate that YaRN exhibits the capability to extrapolate beyond the limited context of a fine-tuning dataset. We publish the checkpoints of Llama 2 7B/13B fine-tuned using YaRN with 64k and 128k context windows at https://github.com/jquesnelle/yarn