 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeMo: Decoupled Momentum Optimization
Nov 29, 2024Training large neural networks typically requires sharing gradients between accelerators through specialized high-speed interconnects. Drawing from the signal processing principles of frequency decomposition and energy compaction, we demonstrate that synchronizing full optimizer states and model parameters during training is unnecessary. By decoupling momentum updates and allowing controlled divergence in optimizer states across accelerators, we achieve improved convergence compared to state-of-the-art optimizers. We introduce {\textbf{De}}coupled {\textbf{Mo}}mentum (DeMo), a fused optimizer and data parallel algorithm that reduces inter-accelerator communication requirements by several orders of magnitude. This enables training of large neural networks even with limited network bandwidth and heterogeneous hardware. Our method is topology-agnostic and architecture-independent and supports scalable clock-synchronous distributed training with negligible compute and memory overhead. Empirical results show that models trained with DeMo match or exceed the performance of equivalent models trained with AdamW, while eliminating the need for high-speed interconnects when pre-training large scale foundation models. An open source reference PyTorch implementation is published on GitHub at https://github.com/bloc97/DeMo
Understanding the Diffusion Objective as a Weighted Integral of ELBOs
Mar 01, 2023Diffusion models in the literature are optimized with various objectives that are special cases of a weighted loss, where the weighting function specifies the weight per noise level. Uniform weighting corresponds to maximizing the ELBO, a principled approximation of maximum likelihood. In current practice diffusion models are optimized with non-uniform weighting due to better results in terms of sample quality. In this work we expose a direct relationship between the weighted loss (with any weighting) and the ELBO objective. We show that the weighted loss can be written as a weighted integral of ELBOs, with one ELBO per noise level. If the weighting function is monotonic, then the weighted loss is a likelihood-based objective: it maximizes the ELBO under simple data augmentation, namely Gaussian noise perturbation. Our main contribution is a deeper theoretical understanding of the diffusion objective, but we also performed some experiments comparing monotonic with non-monotonic weightings, finding that monotonic weighting performs competitively with the best published results.
On Distillation of Guided Diffusion Models
Oct 06, 2022
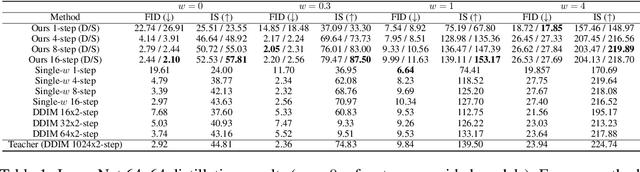
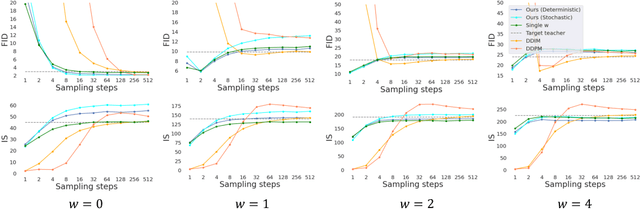
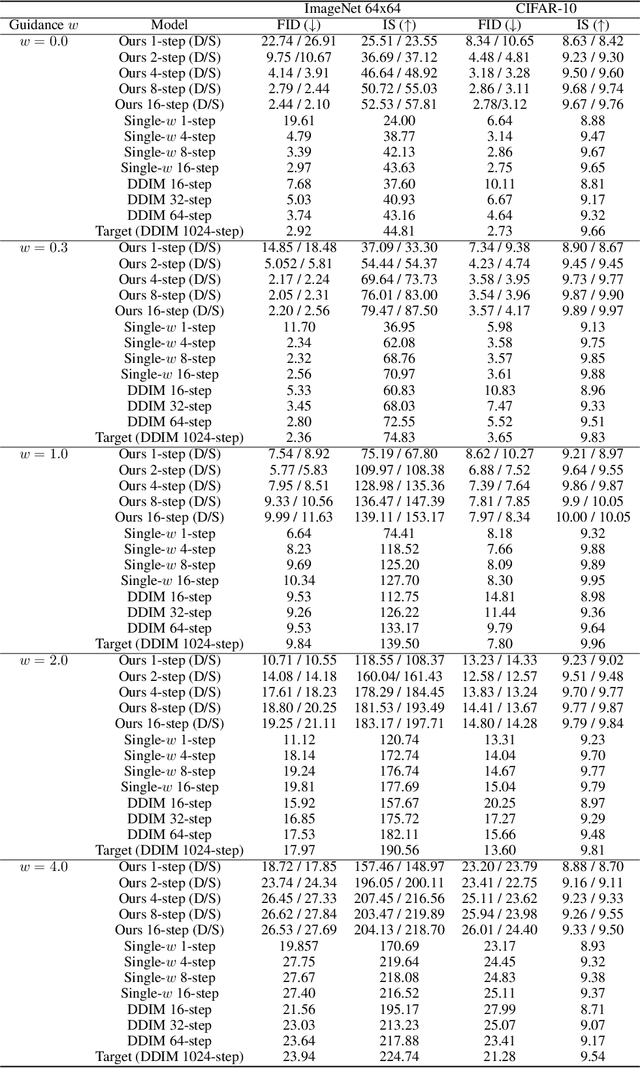
Classifier-free guided diffusion models have recently been shown to be highly effective at high-resolution image generation, and they have been widely used in large-scale diffusion frameworks including DALL-E 2, GLIDE and Imagen. However, a downside of classifier-free guided diffusion models is that they are computationally expensive at inference time since they require evaluating two diffusion models, a class-conditional model and an unconditional model, hundreds of times. To deal with this limitation, we propose an approach to distilling classifier-free guided diffusion models into models that are fast to sample from: Given a pre-trained classifier-free guided model, we first learn a single model to match the output of the combined conditional and unconditional models, and then progressively distill that model to a diffusion model that requires much fewer sampling steps. On ImageNet 64x64 and CIFAR-10, our approach is able to generate images visually comparable to that of the original model using as few as 4 sampling steps, achieving FID/IS scores comparable to that of the original model while being up to 256 times faster to sample from.
Imagen Video: High Definition Video Generation with Diffusion Models
Oct 05, 2022
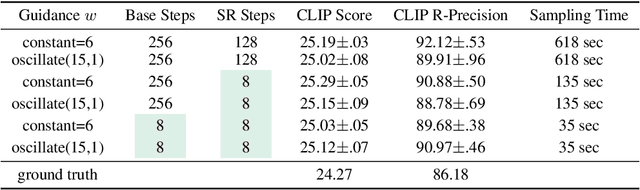
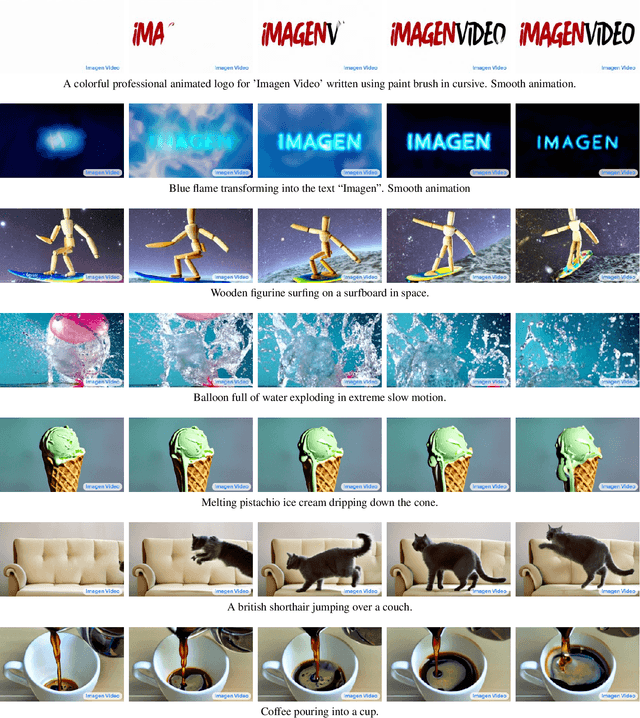

We present Imagen Video, a text-conditional video generation system based on a cascade of video diffusion models. Given a text prompt, Imagen Video generates high definition videos using a base video generation model and a sequence of interleaved spatial and temporal video super-resolution models. We describe how we scale up the system as a high definition text-to-video model including design decisions such as the choice of fully-convolutional temporal and spatial super-resolution models at certain resolutions, and the choice of the v-parameterization of diffusion models. In addition, we confirm and transfer findings from previous work on diffusion-based image generation to the video generation setting. Finally, we apply progressive distillation to our video models with classifier-free guidance for fast, high quality sampling. We find Imagen Video not only capable of generating videos of high fidelity, but also having a high degree of controllability and world knowledge, including the ability to generate diverse videos and text animations in various artistic styles and with 3D object understanding. See https://imagen.research.google/video/ for samples.
Variational Diffusion Models
Jul 12, 2021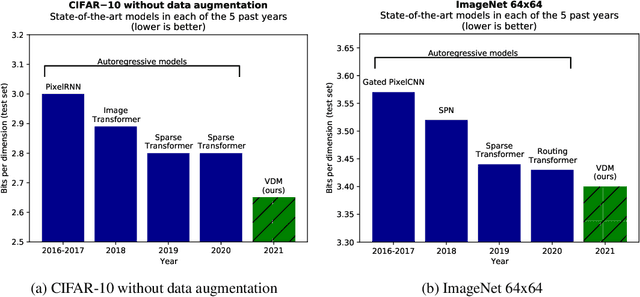
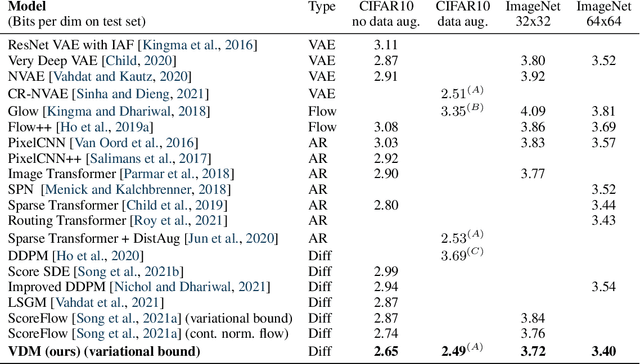

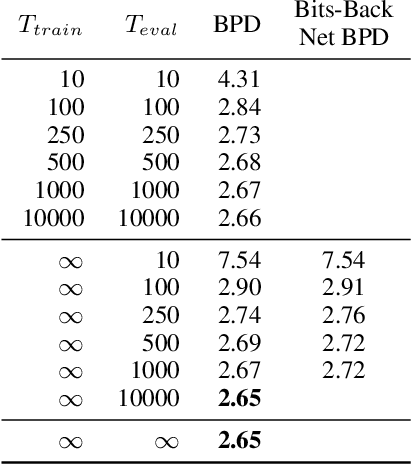
Diffusion-based generative models have demonstrated a capacity for perceptually impressive synthesis, but can they also be great likelihood-based models? We answer this in the affirmative, and introduce a family of diffusion-based generative models that obtain state-of-the-art likelihoods on standard image density estimation benchmarks. Unlike other diffusion-based models, our method allows for efficient optimization of the noise schedule jointly with the rest of the model. We show that the variational lower bound (VLB) simplifies to a remarkably short expression in terms of the signal-to-noise ratio of the diffused data, thereby improving our theoretical understanding of this model class. Using this insight, we prove an equivalence between several models proposed in the literature. In addition, we show that the continuous-time VLB is invariant to the noise schedule, except for the signal-to-noise ratio at its endpoints. This enables us to learn a noise schedule that minimizes the variance of the resulting VLB estimator, leading to faster optimization. Combining these advances with architectural improvements, we obtain state-of-the-art likelihoods on image density estimation benchmarks, outperforming autoregressive models that have dominated these benchmarks for many years, with often significantly faster optimization. In addition, we show how to turn the model into a bits-back compression scheme, and demonstrate lossless compression rates close to the theoretical optimum.
How to Train Your Energy-Based Models
Jan 09, 2021
Energy-Based Models (EBMs), also known as non-normalized probabilistic models, specify probability density or mass functions up to an unknown normalizing constant. Unlike most other probabilistic models, EBMs do not place a restriction on the tractability of the normalizing constant, thus are more flexible to parameterize and can model a more expressive family of probability distributions. However, the unknown normalizing constant of EBMs makes training particularly difficult. Our goal is to provide a friendly introduction to modern approaches for EBM training. We start by explaining maximum likelihood training with Markov chain Monte Carlo (MCMC), and proceed to elaborate on MCMC-free approaches, including Score Matching (SM) and Noise Constrastive Estimation (NCE). We highlight theoretical connections among these three approaches, and end with a brief survey on alternative training methods, which are still under active research. Our tutorial is targeted at an audience with basic understanding of generative models who want to apply EBMs or start a research project in this direction.
Learning Energy-Based Models by Diffusion Recovery Likelihood
Dec 15, 2020
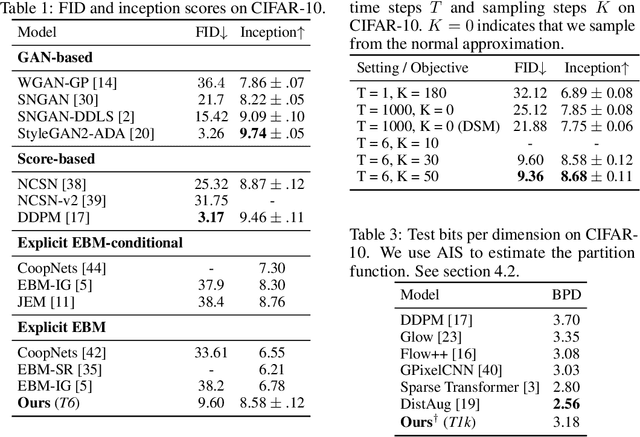
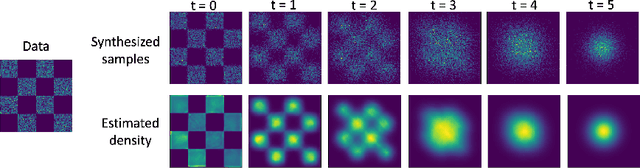

While energy-based models (EBMs) exhibit a number of desirable properties, training and sampling on high-dimensional datasets remains challenging. Inspired by recent progress on diffusion probabilistic models, we present a diffusion recovery likelihood method to tractably learn and sample from a sequence of EBMs trained on increasingly noisy versions of a dataset. Each EBM is trained by maximizing the recovery likelihood: the conditional probability of the data at a certain noise level given their noisy versions at a higher noise level. The recovery likelihood objective is more tractable than the marginal likelihood objective, since it only requires MCMC sampling from a relatively concentrated conditional distribution. Moreover, we show that this estimation method is theoretically consistent: it learns the correct conditional and marginal distributions at each noise level, given sufficient data. After training, synthesized images can be generated efficiently by a sampling process that initializes from a spherical Gaussian distribution and progressively samples the conditional distributions at decreasingly lower noise levels. Our method generates high fidelity samples on various image datasets. On unconditional CIFAR-10 our method achieves FID 9.60 and inception score 8.58, superior to the majority of GANs. Moreover, we demonstrate that unlike previous work on EBMs, our long-run MCMC samples from the conditional distributions do not diverge and still represent realistic images, allowing us to accurately estimate the normalized density of data even for high-dimensional datasets.
Score-Based Generative Modeling through Stochastic Differential Equations
Nov 26, 2020
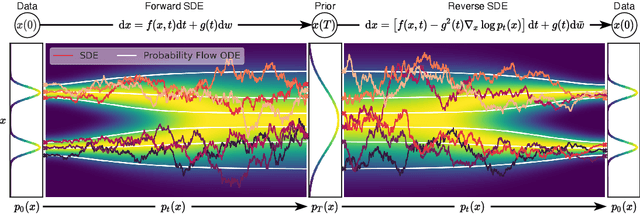

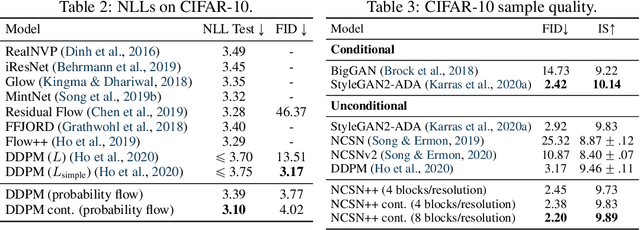
Creating noise from data is easy; creating data from noise is generative modeling. We present a stochastic differential equation (SDE) that smoothly transforms a complex data distribution to a known prior distribution by slowly injecting noise, and a corresponding reverse-time SDE that transforms the prior distribution back into the data distribution by slowly removing the noise. Crucially, the reverse-time SDE depends only on the time-dependent gradient field (a.k.a., score) of the perturbed data distribution. By leveraging advances in score-based generative modeling, we can accurately estimate these scores with neural networks, and use numerical SDE solvers to generate samples. We show that this framework encapsulates previous approaches in diffusion probabilistic modeling and score-based generative modeling, and allows for new sampling procedures. In particular, we introduce a predictor-corrector framework to correct errors in the evolution of the discretized reverse-time SDE. We also derive an equivalent neural ODE that samples from the same distribution as the SDE, which enables exact likelihood computation, and improved sampling efficiency. In addition, our framework enables conditional generation with an unconditional model, as we demonstrate with experiments on class-conditional generation, image inpainting, and colorization. Combined with multiple architectural improvements, we achieve record-breaking performance for unconditional image generation on CIFAR-10 with an Inception score of 9.89 and FID of 2.20, a competitive likelihood of 3.10 bits/dim, and demonstrate high fidelity generation of $1024 \times 1024$ images for the first time from a score-based generative model.
Wave-Tacotron: Spectrogram-free end-to-end text-to-speech synthesis
Nov 06, 2020
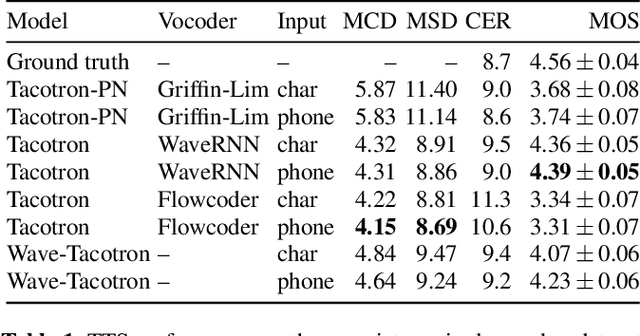
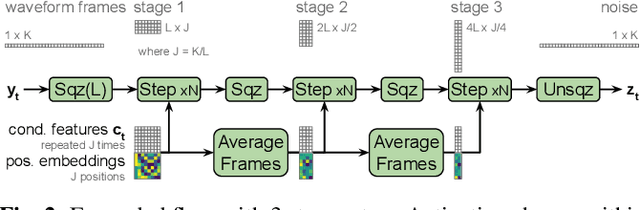
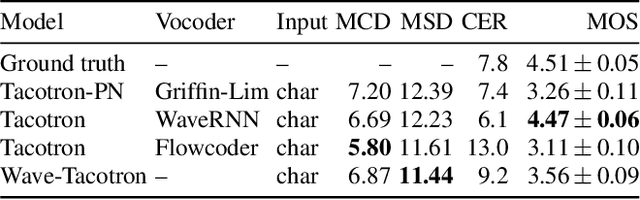
We describe a sequence-to-sequence neural network which can directly generate speech waveforms from text inputs. The architecture extends the Tacotron model by incorporating a normalizing flow into the autoregressive decoder loop. Output waveforms are modeled as a sequence of non-overlapping fixed-length frames, each one containing hundreds of samples. The interdependencies of waveform samples within each frame are modeled using the normalizing flow, enabling parallel training and synthesis. Longer-term dependencies are handled autoregressively by conditioning each flow on preceding frames. This model can be optimized directly with maximum likelihood, without using intermediate, hand-designed features nor additional loss terms. Contemporary state-of-the-art text-to-speech (TTS) systems use a cascade of separately learned models: one (such as Tacotron) which generates intermediate features (such as spectrograms) from text, followed by a vocoder (such as WaveRNN) which generates waveform samples from the intermediate features. The proposed system, in contrast, does not use a fixed intermediate representation, and learns all parameters end-to-end. Experiments show that the proposed model generates speech with quality approaching a state-of-the-art neural TTS system, with significantly improved generation speed.
On Linear Identifiability of Learned Representations
Jul 08, 2020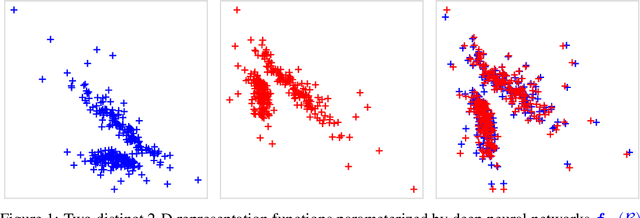
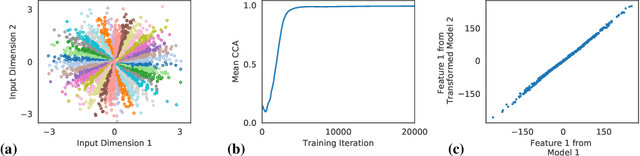
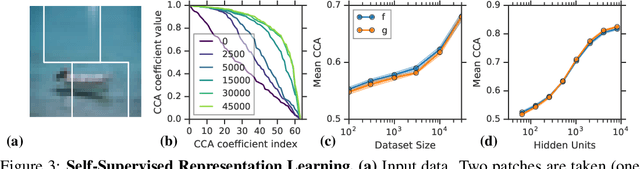
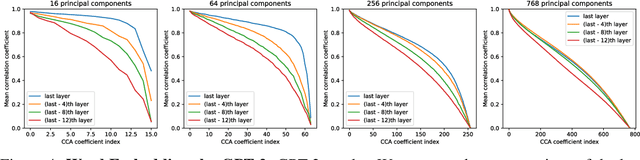
Identifiability is a desirable property of a statistical model: it implies that the true model parameters may be estimated to any desired precision, given sufficient computational resources and data. We study identifiability in the context of representation learning: discovering nonlinear data representations that are optimal with respect to some downstream task. When parameterized as deep neural networks, such representation functions typically lack identifiability in parameter space, because they are overparameterized by design. In this paper, building on recent advances in nonlinear ICA, we aim to rehabilitate identifiability by showing that a large family of discriminative models are in fact identifiable in function space, up to a linear indeterminacy. Many models for representation learning in a wide variety of domains have been identifiable in this sense, including text, images and audio, state-of-the-art at time of publication. We derive sufficient conditions for linear identifiability and provide empirical support for the result on both simulated and real-world data.