 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWave-Tacotron: Spectrogram-free end-to-end text-to-speech synthesis
Paper and Code

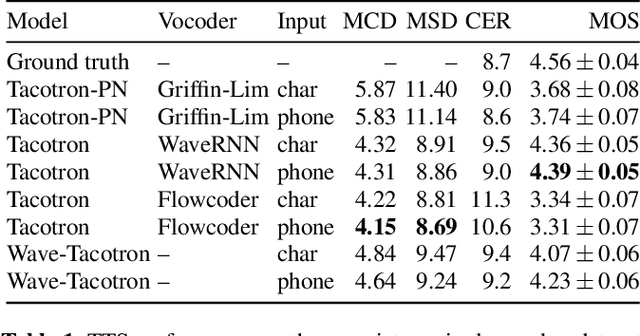
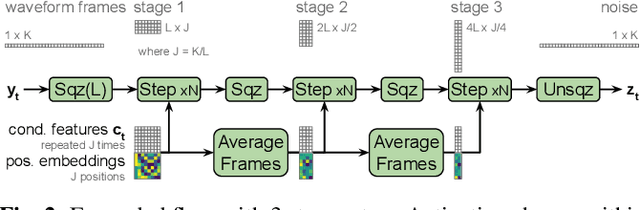
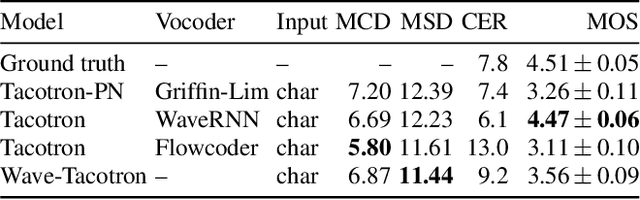
We describe a sequence-to-sequence neural network which can directly generate speech waveforms from text inputs. The architecture extends the Tacotron model by incorporating a normalizing flow into the autoregressive decoder loop. Output waveforms are modeled as a sequence of non-overlapping fixed-length frames, each one containing hundreds of samples. The interdependencies of waveform samples within each frame are modeled using the normalizing flow, enabling parallel training and synthesis. Longer-term dependencies are handled autoregressively by conditioning each flow on preceding frames. This model can be optimized directly with maximum likelihood, without using intermediate, hand-designed features nor additional loss terms. Contemporary state-of-the-art text-to-speech (TTS) systems use a cascade of separately learned models: one (such as Tacotron) which generates intermediate features (such as spectrograms) from text, followed by a vocoder (such as WaveRNN) which generates waveform samples from the intermediate features. The proposed system, in contrast, does not use a fixed intermediate representation, and learns all parameters end-to-end. Experiments show that the proposed model generates speech with quality approaching a state-of-the-art neural TTS system, with significantly improved generation speed.