 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimpler Diffusion (SiD2): 1.5 FID on ImageNet512 with pixel-space diffusion
Oct 25, 2024



Latent diffusion models have become the popular choice for scaling up diffusion models for high resolution image synthesis. Compared to pixel-space models that are trained end-to-end, latent models are perceived to be more efficient and to produce higher image quality at high resolution. Here we challenge these notions, and show that pixel-space models can in fact be very competitive to latent approaches both in quality and efficiency, achieving 1.5 FID on ImageNet512 and new SOTA results on ImageNet128 and ImageNet256. We present a simple recipe for scaling end-to-end pixel-space diffusion models to high resolutions. 1: Use the sigmoid loss (Kingma & Gao, 2023) with our prescribed hyper-parameters. 2: Use our simplified memory-efficient architecture with fewer skip-connections. 3: Scale the model to favor processing the image at high resolution with fewer parameters, rather than using more parameters but at a lower resolution. When combining these three steps with recently proposed tricks like guidance intervals, we obtain a family of pixel-space diffusion models we call Simple Diffusion v2 (SiD2).
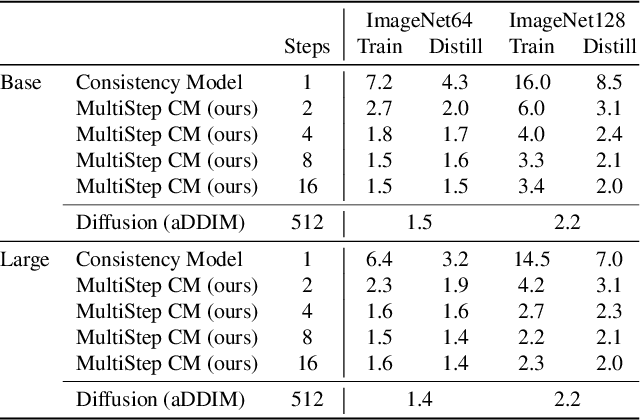
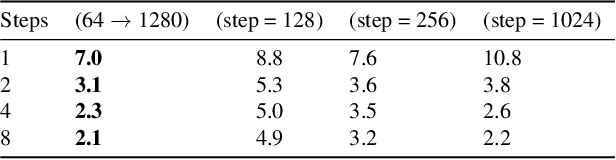
Multistep Distillation of Diffusion Models via Moment Matching
Jun 06, 2024We present a new method for making diffusion models faster to sample. The method distills many-step diffusion models into few-step models by matching conditional expectations of the clean data given noisy data along the sampling trajectory. Our approach extends recently proposed one-step methods to the multi-step case, and provides a new perspective by interpreting these approaches in terms of moment matching. By using up to 8 sampling steps, we obtain distilled models that outperform not only their one-step versions but also their original many-step teacher models, obtaining new state-of-the-art results on the Imagenet dataset. We also show promising results on a large text-to-image model where we achieve fast generation of high resolution images directly in image space, without needing autoencoders or upsamplers.
EM Distillation for One-step Diffusion Models
May 27, 2024



While diffusion models can learn complex distributions, sampling requires a computationally expensive iterative process. Existing distillation methods enable efficient sampling, but have notable limitations, such as performance degradation with very few sampling steps, reliance on training data access, or mode-seeking optimization that may fail to capture the full distribution. We propose EM Distillation (EMD), a maximum likelihood-based approach that distills a diffusion model to a one-step generator model with minimal loss of perceptual quality. Our approach is derived through the lens of Expectation-Maximization (EM), where the generator parameters are updated using samples from the joint distribution of the diffusion teacher prior and inferred generator latents. We develop a reparametrized sampling scheme and a noise cancellation technique that together stabilizes the distillation process. We further reveal an interesting connection of our method with existing methods that minimize mode-seeking KL. EMD outperforms existing one-step generative methods in terms of FID scores on ImageNet-64 and ImageNet-128, and compares favorably with prior work on distilling text-to-image diffusion models.
Multistep Consistency Models
Mar 11, 2024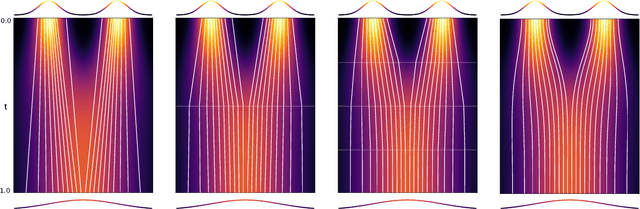

Diffusion models are relatively easy to train but require many steps to generate samples. Consistency models are far more difficult to train, but generate samples in a single step. In this paper we propose Multistep Consistency Models: A unification between Consistency Models (Song et al., 2023) and TRACT (Berthelot et al., 2023) that can interpolate between a consistency model and a diffusion model: a trade-off between sampling speed and sampling quality. Specifically, a 1-step consistency model is a conventional consistency model whereas we show that a $\infty$-step consistency model is a diffusion model. Multistep Consistency Models work really well in practice. By increasing the sample budget from a single step to 2-8 steps, we can train models more easily that generate higher quality samples, while retaining much of the sampling speed benefits. Notable results are 1.4 FID on Imagenet 64 in 8 step and 2.1 FID on Imagenet128 in 8 steps with consistency distillation. We also show that our method scales to a text-to-image diffusion model, generating samples that are very close to the quality of the original model.
Rolling Diffusion Models
Feb 12, 2024



Diffusion models have recently been increasingly applied to temporal data such as video, fluid mechanics simulations, or climate data. These methods generally treat subsequent frames equally regarding the amount of noise in the diffusion process. This paper explores Rolling Diffusion: a new approach that uses a sliding window denoising process. It ensures that the diffusion process progressively corrupts through time by assigning more noise to frames that appear later in a sequence, reflecting greater uncertainty about the future as the generation process unfolds. Empirically, we show that when the temporal dynamics are complex, Rolling Diffusion is superior to standard diffusion. In particular, this result is demonstrated in a video prediction task using the Kinetics-600 video dataset and in a chaotic fluid dynamics forecasting experiment.
simple diffusion: End-to-end diffusion for high resolution images
Jan 26, 2023



Currently, applying diffusion models in pixel space of high resolution images is difficult. Instead, existing approaches focus on diffusion in lower dimensional spaces (latent diffusion), or have multiple super-resolution levels of generation referred to as cascades. The downside is that these approaches add additional complexity to the diffusion framework. This paper aims to improve denoising diffusion for high resolution images while keeping the model as simple as possible. The paper is centered around the research question: How can one train a standard denoising diffusion models on high resolution images, and still obtain performance comparable to these alternate approaches? The four main findings are: 1) the noise schedule should be adjusted for high resolution images, 2) It is sufficient to scale only a particular part of the architecture, 3) dropout should be added at specific locations in the architecture, and 4) downsampling is an effective strategy to avoid high resolution feature maps. Combining these simple yet effective techniques, we achieve state-of-the-art on image generation among diffusion models without sampling modifiers on ImageNet.
On Distillation of Guided Diffusion Models
Oct 06, 2022
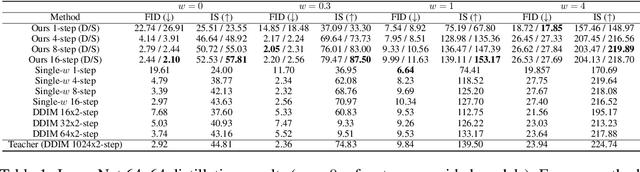
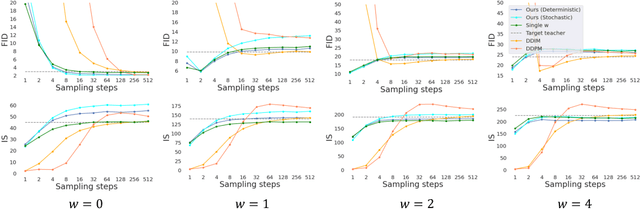
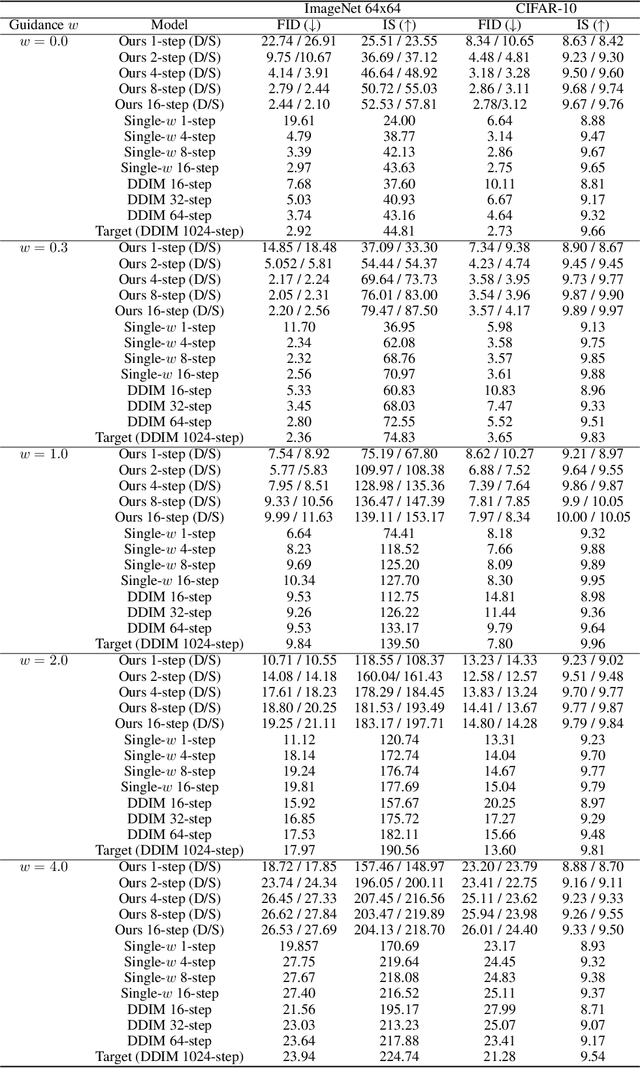
Classifier-free guided diffusion models have recently been shown to be highly effective at high-resolution image generation, and they have been widely used in large-scale diffusion frameworks including DALL-E 2, GLIDE and Imagen. However, a downside of classifier-free guided diffusion models is that they are computationally expensive at inference time since they require evaluating two diffusion models, a class-conditional model and an unconditional model, hundreds of times. To deal with this limitation, we propose an approach to distilling classifier-free guided diffusion models into models that are fast to sample from: Given a pre-trained classifier-free guided model, we first learn a single model to match the output of the combined conditional and unconditional models, and then progressively distill that model to a diffusion model that requires much fewer sampling steps. On ImageNet 64x64 and CIFAR-10, our approach is able to generate images visually comparable to that of the original model using as few as 4 sampling steps, achieving FID/IS scores comparable to that of the original model while being up to 256 times faster to sample from.
Imagen Video: High Definition Video Generation with Diffusion Models
Oct 05, 2022
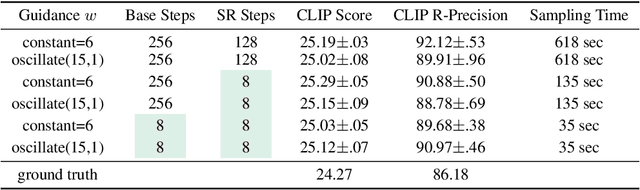
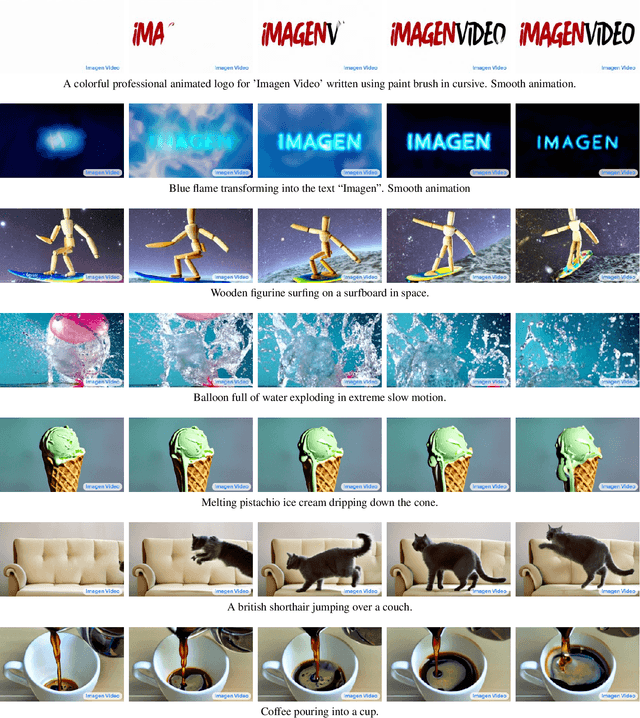

We present Imagen Video, a text-conditional video generation system based on a cascade of video diffusion models. Given a text prompt, Imagen Video generates high definition videos using a base video generation model and a sequence of interleaved spatial and temporal video super-resolution models. We describe how we scale up the system as a high definition text-to-video model including design decisions such as the choice of fully-convolutional temporal and spatial super-resolution models at certain resolutions, and the choice of the v-parameterization of diffusion models. In addition, we confirm and transfer findings from previous work on diffusion-based image generation to the video generation setting. Finally, we apply progressive distillation to our video models with classifier-free guidance for fast, high quality sampling. We find Imagen Video not only capable of generating videos of high fidelity, but also having a high degree of controllability and world knowledge, including the ability to generate diverse videos and text animations in various artistic styles and with 3D object understanding. See https://imagen.research.google/video/ for samples.
Blurring Diffusion Models
Sep 12, 2022



Recently, Rissanen et al., (2022) have presented a new type of diffusion process for generative modeling based on heat dissipation, or blurring, as an alternative to isotropic Gaussian diffusion. Here, we show that blurring can equivalently be defined through a Gaussian diffusion process with non-isotropic noise. In making this connection, we bridge the gap between inverse heat dissipation and denoising diffusion, and we shed light on the inductive bias that results from this modeling choice. Finally, we propose a generalized class of diffusion models that offers the best of both standard Gaussian denoising diffusion and inverse heat dissipation, which we call Blurring Diffusion Models.
Classifier-Free Diffusion Guidance
Jul 26, 2022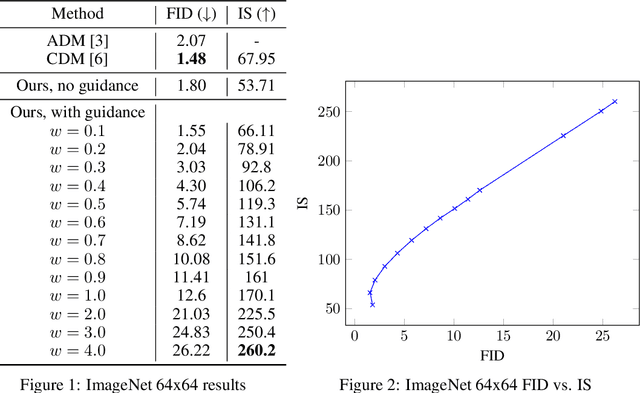


Classifier guidance is a recently introduced method to trade off mode coverage and sample fidelity in conditional diffusion models post training, in the same spirit as low temperature sampling or truncation in other types of generative models. Classifier guidance combines the score estimate of a diffusion model with the gradient of an image classifier and thereby requires training an image classifier separate from the diffusion model. It also raises the question of whether guidance can be performed without a classifier. We show that guidance can be indeed performed by a pure generative model without such a classifier: in what we call classifier-free guidance, we jointly train a conditional and an unconditional diffusion model, and we combine the resulting conditional and unconditional score estimates to attain a trade-off between sample quality and diversity similar to that obtained using classifier guidance.