 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
EM Distillation for One-step Diffusion Models
May 27, 2024



While diffusion models can learn complex distributions, sampling requires a computationally expensive iterative process. Existing distillation methods enable efficient sampling, but have notable limitations, such as performance degradation with very few sampling steps, reliance on training data access, or mode-seeking optimization that may fail to capture the full distribution. We propose EM Distillation (EMD), a maximum likelihood-based approach that distills a diffusion model to a one-step generator model with minimal loss of perceptual quality. Our approach is derived through the lens of Expectation-Maximization (EM), where the generator parameters are updated using samples from the joint distribution of the diffusion teacher prior and inferred generator latents. We develop a reparametrized sampling scheme and a noise cancellation technique that together stabilizes the distillation process. We further reveal an interesting connection of our method with existing methods that minimize mode-seeking KL. EMD outperforms existing one-step generative methods in terms of FID scores on ImageNet-64 and ImageNet-128, and compares favorably with prior work on distilling text-to-image diffusion models.
DreamInpainter: Text-Guided Subject-Driven Image Inpainting with Diffusion Models
Dec 05, 2023
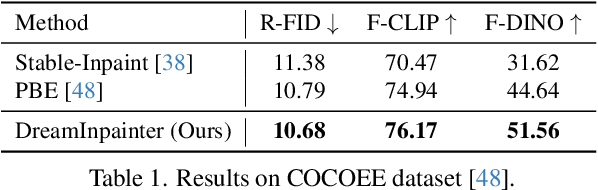

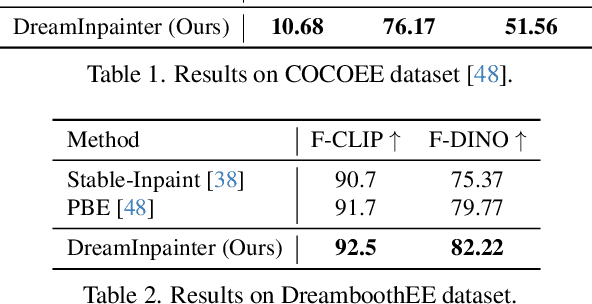
This study introduces Text-Guided Subject-Driven Image Inpainting, a novel task that combines text and exemplar images for image inpainting. While both text and exemplar images have been used independently in previous efforts, their combined utilization remains unexplored. Simultaneously accommodating both conditions poses a significant challenge due to the inherent balance required between editability and subject fidelity. To tackle this challenge, we propose a two-step approach DreamInpainter. First, we compute dense subject features to ensure accurate subject replication. Then, we employ a discriminative token selection module to eliminate redundant subject details, preserving the subject's identity while allowing changes according to other conditions such as mask shape and text prompts. Additionally, we introduce a decoupling regularization technique to enhance text control in the presence of exemplar images. Our extensive experiments demonstrate the superior performance of our method in terms of visual quality, identity preservation, and text control, showcasing its effectiveness in the context of text-guided subject-driven image inpainting.
HiFi Tuner: High-Fidelity Subject-Driven Fine-Tuning for Diffusion Models
Nov 30, 2023



This paper explores advancements in high-fidelity personalized image generation through the utilization of pre-trained text-to-image diffusion models. While previous approaches have made significant strides in generating versatile scenes based on text descriptions and a few input images, challenges persist in maintaining the subject fidelity within the generated images. In this work, we introduce an innovative algorithm named HiFi Tuner to enhance the appearance preservation of objects during personalized image generation. Our proposed method employs a parameter-efficient fine-tuning framework, comprising a denoising process and a pivotal inversion process. Key enhancements include the utilization of mask guidance, a novel parameter regularization technique, and the incorporation of step-wise subject representations to elevate the sample fidelity. Additionally, we propose a reference-guided generation approach that leverages the pivotal inversion of a reference image to mitigate unwanted subject variations and artifacts. We further extend our method to a novel image editing task: substituting the subject in an image through textual manipulations. Experimental evaluations conducted on the DreamBooth dataset using the Stable Diffusion model showcase promising results. Fine-tuning solely on textual embeddings improves CLIP-T score by 3.6 points and improves DINO score by 9.6 points over Textual Inversion. When fine-tuning all parameters, HiFi Tuner improves CLIP-T score by 1.2 points and improves DINO score by 1.2 points over DreamBooth, establishing a new state of the art.
UFOGen: You Forward Once Large Scale Text-to-Image Generation via Diffusion GANs
Nov 29, 2023
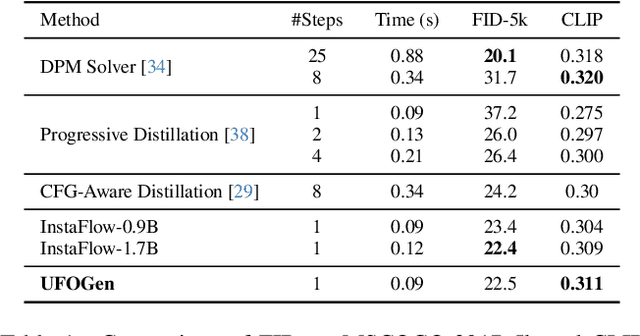

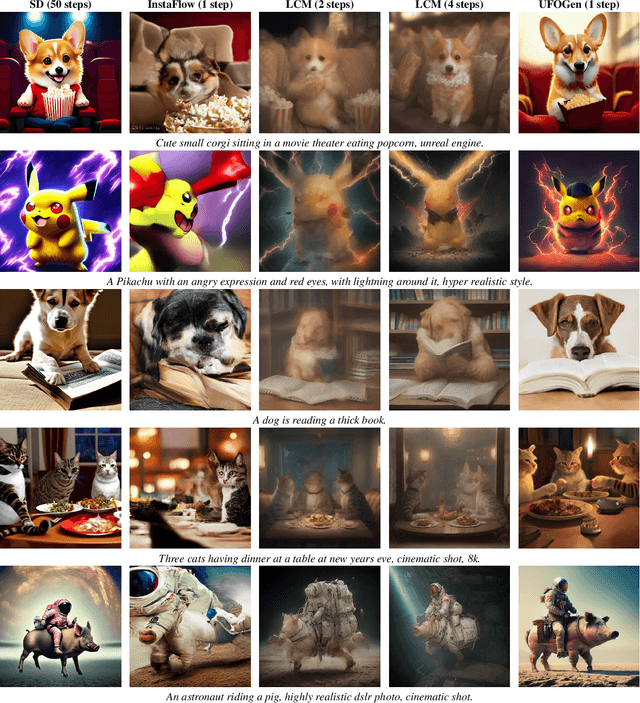
Text-to-image diffusion models have demonstrated remarkable capabilities in transforming textual prompts into coherent images, yet the computational cost of their inference remains a persistent challenge. To address this issue, we present UFOGen, a novel generative model designed for ultra-fast, one-step text-to-image synthesis. In contrast to conventional approaches that focus on improving samplers or employing distillation techniques for diffusion models, UFOGen adopts a hybrid methodology, integrating diffusion models with a GAN objective. Leveraging a newly introduced diffusion-GAN objective and initialization with pre-trained diffusion models, UFOGen excels in efficiently generating high-quality images conditioned on textual descriptions in a single step. Beyond traditional text-to-image generation, UFOGen showcases versatility in applications. Notably, UFOGen stands among the pioneering models enabling one-step text-to-image generation and diverse downstream tasks, presenting a significant advancement in the landscape of efficient generative models.
MobileDiffusion: Subsecond Text-to-Image Generation on Mobile Devices
Nov 28, 2023



The deployment of large-scale text-to-image diffusion models on mobile devices is impeded by their substantial model size and slow inference speed. In this paper, we propose \textbf{MobileDiffusion}, a highly efficient text-to-image diffusion model obtained through extensive optimizations in both architecture and sampling techniques. We conduct a comprehensive examination of model architecture design to reduce redundancy, enhance computational efficiency, and minimize model's parameter count, while preserving image generation quality. Additionally, we employ distillation and diffusion-GAN finetuning techniques on MobileDiffusion to achieve 8-step and 1-step inference respectively. Empirical studies, conducted both quantitatively and qualitatively, demonstrate the effectiveness of our proposed techniques. MobileDiffusion achieves a remarkable \textbf{sub-second} inference speed for generating a $512\times512$ image on mobile devices, establishing a new state of the art.
Adaptive Multi-stage Density Ratio Estimation for Learning Latent Space Energy-based Model
Sep 19, 2022
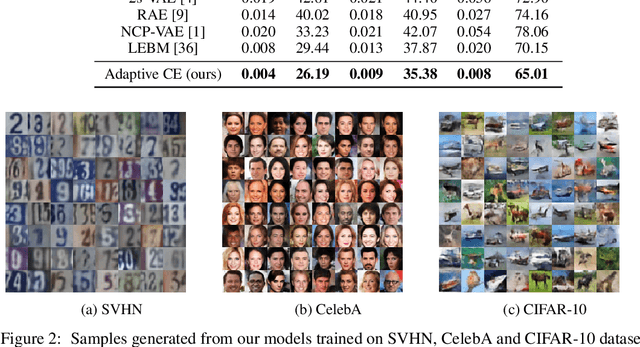


This paper studies the fundamental problem of learning energy-based model (EBM) in the latent space of the generator model. Learning such prior model typically requires running costly Markov Chain Monte Carlo (MCMC). Instead, we propose to use noise contrastive estimation (NCE) to discriminatively learn the EBM through density ratio estimation between the latent prior density and latent posterior density. However, the NCE typically fails to accurately estimate such density ratio given large gap between two densities. To effectively tackle this issue and learn more expressive prior models, we develop the adaptive multi-stage density ratio estimation which breaks the estimation into multiple stages and learn different stages of density ratio sequentially and adaptively. The latent prior model can be gradually learned using ratio estimated in previous stage so that the final latent space EBM prior can be naturally formed by product of ratios in different stages. The proposed method enables informative and much sharper prior than existing baselines, and can be trained efficiently. Our experiments demonstrate strong performances in image generation and reconstruction as well as anomaly detection.
Tackling the Generative Learning Trilemma with Denoising Diffusion GANs
Dec 15, 2021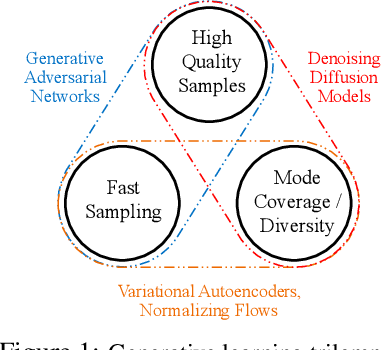



A wide variety of deep generative models has been developed in the past decade. Yet, these models often struggle with simultaneously addressing three key requirements including: high sample quality, mode coverage, and fast sampling. We call the challenge imposed by these requirements the generative learning trilemma, as the existing models often trade some of them for others. Particularly, denoising diffusion models have shown impressive sample quality and diversity, but their expensive sampling does not yet allow them to be applied in many real-world applications. In this paper, we argue that slow sampling in these models is fundamentally attributed to the Gaussian assumption in the denoising step which is justified only for small step sizes. To enable denoising with large steps, and hence, to reduce the total number of denoising steps, we propose to model the denoising distribution using a complex multimodal distribution. We introduce denoising diffusion generative adversarial networks (denoising diffusion GANs) that model each denoising step using a multimodal conditional GAN. Through extensive evaluations, we show that denoising diffusion GANs obtain sample quality and diversity competitive with original diffusion models while being 2000$\times$ faster on the CIFAR-10 dataset. Compared to traditional GANs, our model exhibits better mode coverage and sample diversity. To the best of our knowledge, denoising diffusion GAN is the first model that reduces sampling cost in diffusion models to an extent that allows them to be applied to real-world applications inexpensively. Project page and code: https://nvlabs.github.io/denoising-diffusion-gan
Do We Really Need to Learn Representations from In-domain Data for Outlier Detection?
May 19, 2021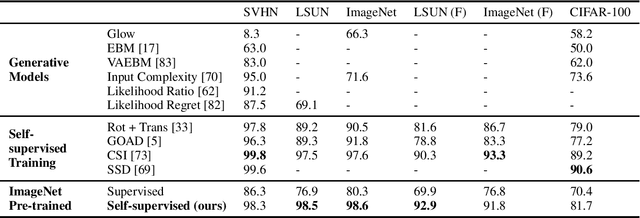
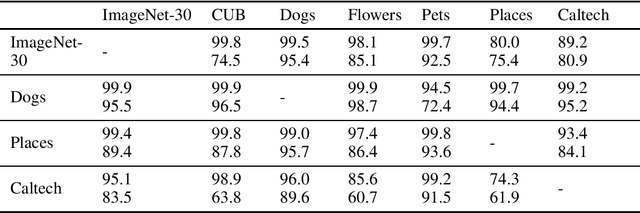
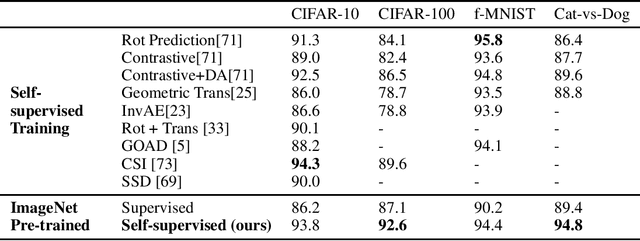

Unsupervised outlier detection, which predicts if a test sample is an outlier or not using only the information from unlabelled inlier data, is an important but challenging task. Recently, methods based on the two-stage framework achieve state-of-the-art performance on this task. The framework leverages self-supervised representation learning algorithms to train a feature extractor on inlier data, and applies a simple outlier detector in the feature space. In this paper, we explore the possibility of avoiding the high cost of training a distinct representation for each outlier detection task, and instead using a single pre-trained network as the universal feature extractor regardless of the source of in-domain data. In particular, we replace the task-specific feature extractor by one network pre-trained on ImageNet with a self-supervised loss. In experiments, we demonstrate competitive or better performance on a variety of outlier detection benchmarks compared with previous two-stage methods, suggesting that learning representations from in-domain data may be unnecessary for outlier detection.
EBMs Trained with Maximum Likelihood are Generator Models Trained with a Self-adverserial Loss
Feb 23, 2021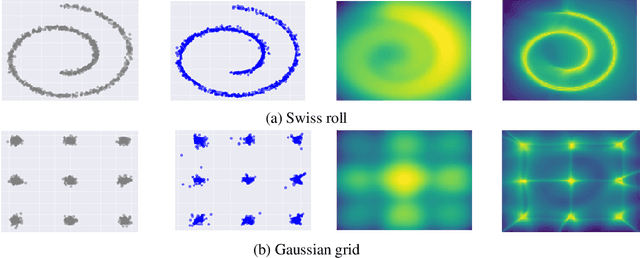



Maximum likelihood estimation is widely used in training Energy-based models (EBMs). Training requires samples from an unnormalized distribution, which is usually intractable, and in practice, these are obtained by MCMC algorithms such as Langevin dynamics. However, since MCMC in high-dimensional space converges extremely slowly, the current understanding of maximum likelihood training, which assumes approximate samples from the model can be drawn, is problematic. In this paper, we try to understand this training procedure by replacing Langevin dynamics with deterministic solutions of the associated gradient descent ODE. Doing so allows us to study the density induced by the dynamics (if the dynamics are invertible), and connect with GANs by treating the dynamics as generator models, the initial values as latent variables and the loss as optimizing a critic defined by the very same energy that determines the generator through its gradient. Hence the term - self-adversarial loss. We show that reintroducing the noise in the dynamics does not lead to a qualitative change in the behavior, and merely reduces the quality of the generator. We thus show that EBM training is effectively a self-adversarial procedure rather than maximum likelihood estimation.