 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multimodal Latent Generative Models with Energy-Based Prior
Sep 30, 2024Multimodal generative models have recently gained significant attention for their ability to learn representations across various modalities, enhancing joint and cross-generation coherence. However, most existing works use standard Gaussian or Laplacian distributions as priors, which may struggle to capture the diverse information inherent in multiple data types due to their unimodal and less informative nature. Energy-based models (EBMs), known for their expressiveness and flexibility across various tasks, have yet to be thoroughly explored in the context of multimodal generative models. In this paper, we propose a novel framework that integrates the multimodal latent generative model with the EBM. Both models can be trained jointly through a variational scheme. This approach results in a more expressive and informative prior, better-capturing of information across multiple modalities. Our experiments validate the proposed model, demonstrating its superior generation coherence.
Layerwise Change of Knowledge in Neural Networks
Sep 13, 2024



This paper aims to explain how a deep neural network (DNN) gradually extracts new knowledge and forgets noisy features through layers in forward propagation. Up to now, although the definition of knowledge encoded by the DNN has not reached a consensus, Previous studies have derived a series of mathematical evidence to take interactions as symbolic primitive inference patterns encoded by a DNN. We extend the definition of interactions and, for the first time, extract interactions encoded by intermediate layers. We quantify and track the newly emerged interactions and the forgotten interactions in each layer during the forward propagation, which shed new light on the learning behavior of DNNs. The layer-wise change of interactions also reveals the change of the generalization capacity and instability of feature representations of a DNN.
Learning Multimodal Latent Space with EBM Prior and MCMC Inference
Aug 20, 2024Multimodal generative models are crucial for various applications. We propose an approach that combines an expressive energy-based model (EBM) prior with Markov Chain Monte Carlo (MCMC) inference in the latent space for multimodal generation. The EBM prior acts as an informative guide, while MCMC inference, specifically through short-run Langevin dynamics, brings the posterior distribution closer to its true form. This method not only provides an expressive prior to better capture the complexity of multimodality but also improves the learning of shared latent variables for more coherent generation across modalities. Our proposed method is supported by empirical experiments, underscoring the effectiveness of our EBM prior with MCMC inference in enhancing cross-modal and joint generative tasks in multimodal contexts.
Learning Latent Space Hierarchical EBM Diffusion Models
May 22, 2024



This work studies the learning problem of the energy-based prior model and the multi-layer generator model. The multi-layer generator model, which contains multiple layers of latent variables organized in a top-down hierarchical structure, typically assumes the Gaussian prior model. Such a prior model can be limited in modelling expressivity, which results in a gap between the generator posterior and the prior model, known as the prior hole problem. Recent works have explored learning the energy-based (EBM) prior model as a second-stage, complementary model to bridge the gap. However, the EBM defined on a multi-layer latent space can be highly multi-modal, which makes sampling from such marginal EBM prior challenging in practice, resulting in ineffectively learned EBM. To tackle the challenge, we propose to leverage the diffusion probabilistic scheme to mitigate the burden of EBM sampling and thus facilitate EBM learning. Our extensive experiments demonstrate a superior performance of our diffusion-learned EBM prior on various challenging tasks.
Can FSK Be Optimised for Integrated Sensing and Communications?
May 02, 2024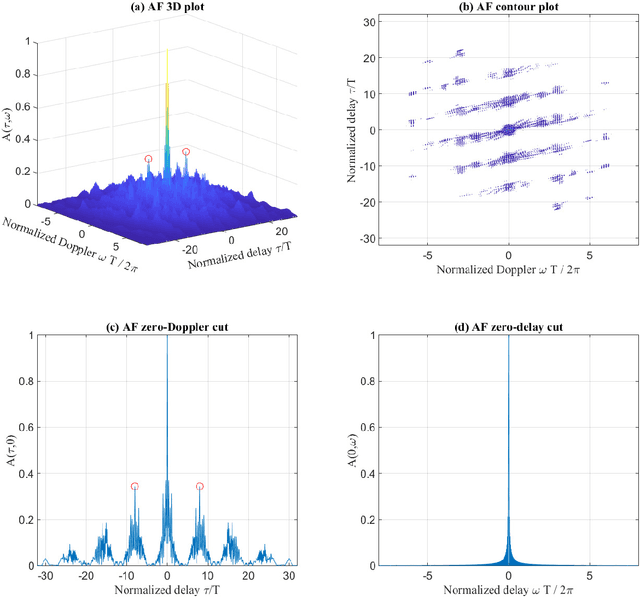
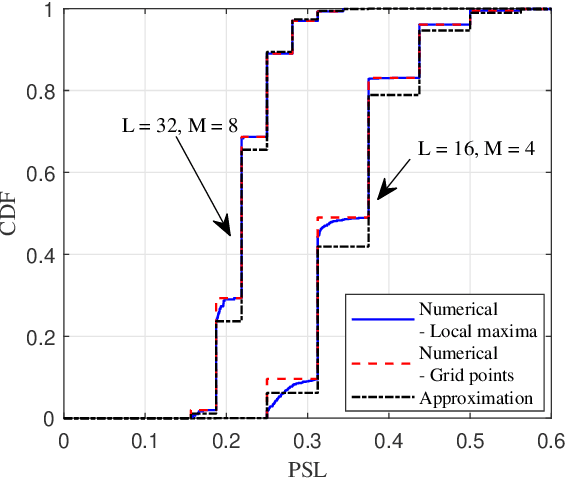
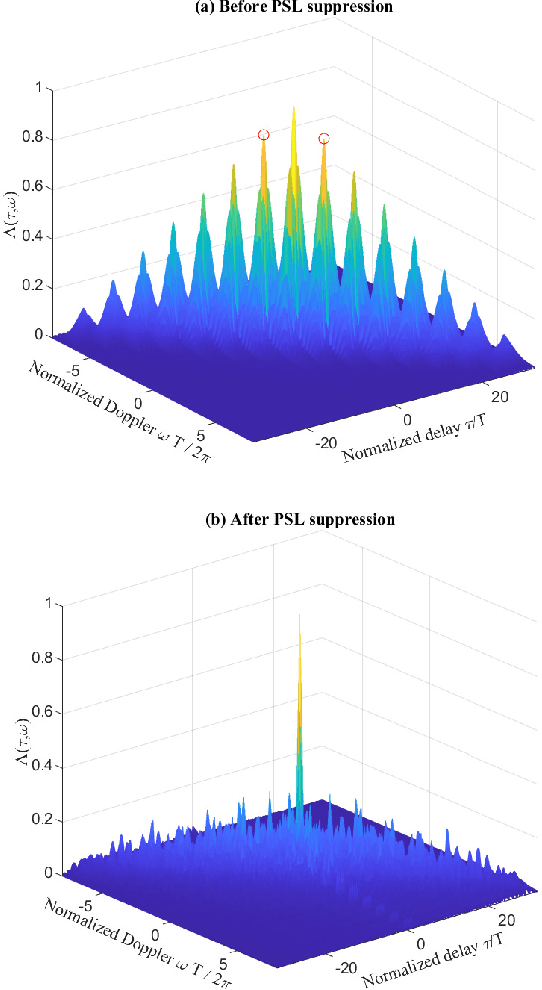
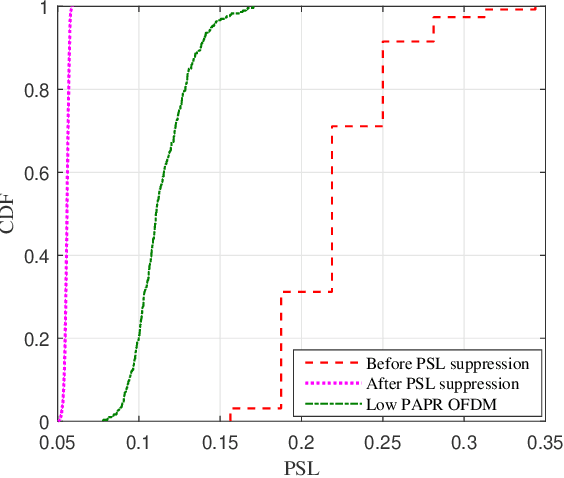
Motivated by the ideal peak-to-average-power ratio and radar sensing capability of traditional frequency-coded radar waveforms, this paper considers the frequency shift keying (FSK) based waveform for joint communications and radar (JCR). An analysis of the probability distributions of its ambiguity function (AF) sidelobe levels (SLs) and peak sidelobe level (PSL) is conducted to study the radar sensing capability of random FSK. Numerical results show that the independent frequency modulation introduces uncontrollable AF PSLs. In order to address this problem, the initial phases of waveform sub-pulses are designed by solving a min-max optimisation problem. Numerical results indicate that the optimisation-based phase design can effectively reduce the AF PSL to a level close to well-designed radar waveforms while having no impact on the data rate and the receiver complexity. For large numbers of waveform sub-pulses and modulation orders, the impact on the error probability is also insignificant.
Improving Adversarial Energy-Based Model via Diffusion Process
Mar 04, 2024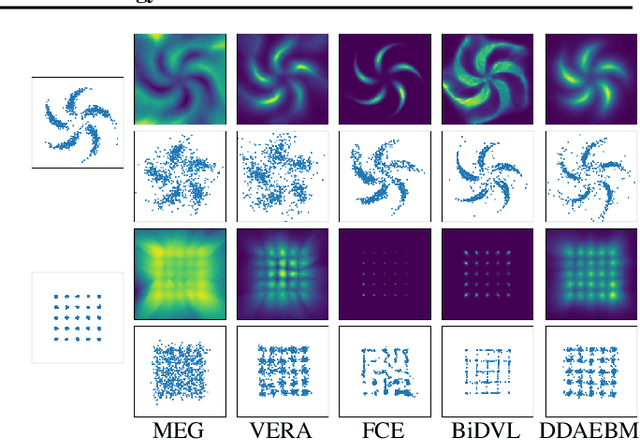

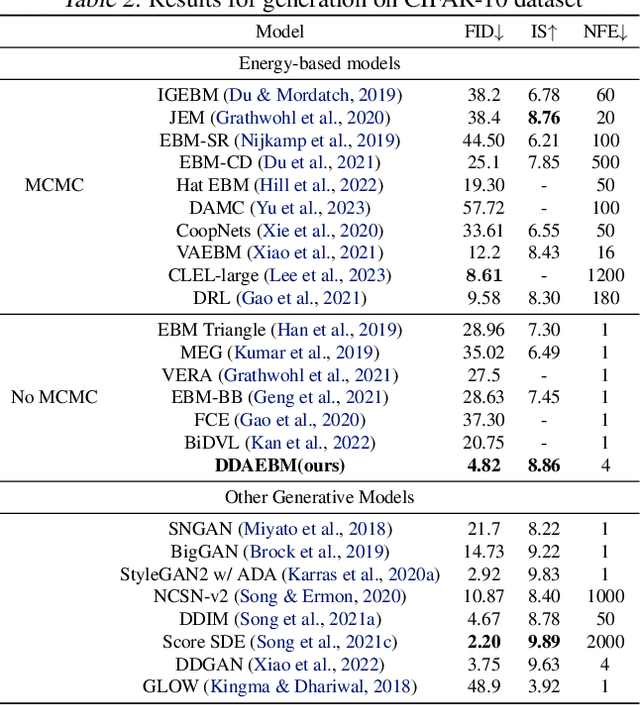

Generative models have shown strong generation ability while efficient likelihood estimation is less explored. Energy-based models~(EBMs) define a flexible energy function to parameterize unnormalized densities efficiently but are notorious for being difficult to train. Adversarial EBMs introduce a generator to form a minimax training game to avoid expensive MCMC sampling used in traditional EBMs, but a noticeable gap between adversarial EBMs and other strong generative models still exists. Inspired by diffusion-based models, we embedded EBMs into each denoising step to split a long-generated process into several smaller steps. Besides, we employ a symmetric Jeffrey divergence and introduce a variational posterior distribution for the generator's training to address the main challenges that exist in adversarial EBMs. Our experiments show significant improvement in generation compared to existing adversarial EBMs, while also providing a useful energy function for efficient density estimation.
Learning Energy-based Model via Dual-MCMC Teaching
Dec 05, 2023



This paper studies the fundamental learning problem of the energy-based model (EBM). Learning the EBM can be achieved using the maximum likelihood estimation (MLE), which typically involves the Markov Chain Monte Carlo (MCMC) sampling, such as the Langevin dynamics. However, the noise-initialized Langevin dynamics can be challenging in practice and hard to mix. This motivates the exploration of joint training with the generator model where the generator model serves as a complementary model to bypass MCMC sampling. However, such a method can be less accurate than the MCMC and result in biased EBM learning. While the generator can also serve as an initializer model for better MCMC sampling, its learning can be biased since it only matches the EBM and has no access to empirical training examples. Such biased generator learning may limit the potential of learning the EBM. To address this issue, we present a joint learning framework that interweaves the maximum likelihood learning algorithm for both the EBM and the complementary generator model. In particular, the generator model is learned by MLE to match both the EBM and the empirical data distribution, making it a more informative initializer for MCMC sampling of EBM. Learning generator with observed examples typically requires inference of the generator posterior. To ensure accurate and efficient inference, we adopt the MCMC posterior sampling and introduce a complementary inference model to initialize such latent MCMC sampling. We show that three separate models can be seamlessly integrated into our joint framework through two (dual-) MCMC teaching, enabling effective and efficient EBM learning.
Learning Hierarchical Features with Joint Latent Space Energy-Based Prior
Oct 14, 2023This paper studies the fundamental problem of multi-layer generator models in learning hierarchical representations. The multi-layer generator model that consists of multiple layers of latent variables organized in a top-down architecture tends to learn multiple levels of data abstraction. However, such multi-layer latent variables are typically parameterized to be Gaussian, which can be less informative in capturing complex abstractions, resulting in limited success in hierarchical representation learning. On the other hand, the energy-based (EBM) prior is known to be expressive in capturing the data regularities, but it often lacks the hierarchical structure to capture different levels of hierarchical representations. In this paper, we propose a joint latent space EBM prior model with multi-layer latent variables for effective hierarchical representation learning. We develop a variational joint learning scheme that seamlessly integrates an inference model for efficient inference. Our experiments demonstrate that the proposed joint EBM prior is effective and expressive in capturing hierarchical representations and modelling data distribution.
Learning Joint Latent Space EBM Prior Model for Multi-layer Generator
Jun 10, 2023This paper studies the fundamental problem of learning multi-layer generator models. The multi-layer generator model builds multiple layers of latent variables as a prior model on top of the generator, which benefits learning complex data distribution and hierarchical representations. However, such a prior model usually focuses on modeling inter-layer relations between latent variables by assuming non-informative (conditional) Gaussian distributions, which can be limited in model expressivity. To tackle this issue and learn more expressive prior models, we propose an energy-based model (EBM) on the joint latent space over all layers of latent variables with the multi-layer generator as its backbone. Such joint latent space EBM prior model captures the intra-layer contextual relations at each layer through layer-wise energy terms, and latent variables across different layers are jointly corrected. We develop a joint training scheme via maximum likelihood estimation (MLE), which involves Markov Chain Monte Carlo (MCMC) sampling for both prior and posterior distributions of the latent variables from different layers. To ensure efficient inference and learning, we further propose a variational training scheme where an inference model is used to amortize the costly posterior MCMC sampling. Our experiments demonstrate that the learned model can be expressive in generating high-quality images and capturing hierarchical features for better outlier detection.
Molecule Design by Latent Space Energy-Based Modeling and Gradual Distribution Shifting
Jun 09, 2023Generation of molecules with desired chemical and biological properties such as high drug-likeness, high binding affinity to target proteins, is critical for drug discovery. In this paper, we propose a probabilistic generative model to capture the joint distribution of molecules and their properties. Our model assumes an energy-based model (EBM) in the latent space. Conditional on the latent vector, the molecule and its properties are modeled by a molecule generation model and a property regression model respectively. To search for molecules with desired properties, we propose a sampling with gradual distribution shifting (SGDS) algorithm, so that after learning the model initially on the training data of existing molecules and their properties, the proposed algorithm gradually shifts the model distribution towards the region supported by molecules with desired values of properties. Our experiments show that our method achieves very strong performances on various molecule design tasks.