 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multimodal Latent Generative Models with Energy-Based Prior
Sep 30, 2024Multimodal generative models have recently gained significant attention for their ability to learn representations across various modalities, enhancing joint and cross-generation coherence. However, most existing works use standard Gaussian or Laplacian distributions as priors, which may struggle to capture the diverse information inherent in multiple data types due to their unimodal and less informative nature. Energy-based models (EBMs), known for their expressiveness and flexibility across various tasks, have yet to be thoroughly explored in the context of multimodal generative models. In this paper, we propose a novel framework that integrates the multimodal latent generative model with the EBM. Both models can be trained jointly through a variational scheme. This approach results in a more expressive and informative prior, better-capturing of information across multiple modalities. Our experiments validate the proposed model, demonstrating its superior generation coherence.
Learning Sparse Latent Representations for Generator Model
Sep 20, 2022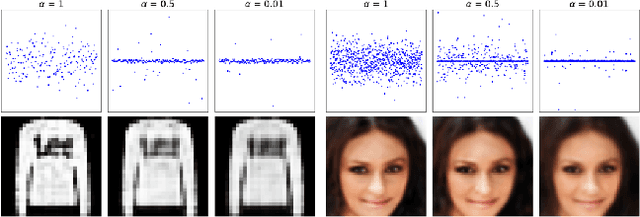
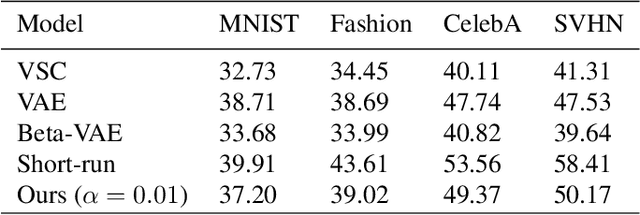
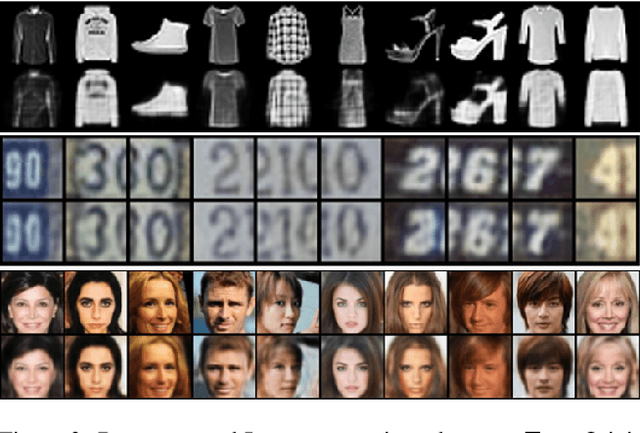

Sparsity is a desirable attribute. It can lead to more efficient and more effective representations compared to the dense model. Meanwhile, learning sparse latent representations has been a challenging problem in the field of computer vision and machine learning due to its complexity. In this paper, we present a new unsupervised learning method to enforce sparsity on the latent space for the generator model with a gradually sparsified spike and slab distribution as our prior. Our model consists of only one top-down generator network that maps the latent variable to the observed data. Latent variables can be inferred following generator posterior direction using non-persistent gradient based method. Spike and Slab regularization in the inference step can push non-informative latent dimensions towards zero to induce sparsity. Extensive experiments show the model can preserve majority of the information from original images with sparse representations while demonstrating improved results compared to other existing methods. We observe that our model can learn disentangled semantics and increase explainability of the latent codes while boosting the robustness in the task of classification and denoising.