 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edges2n-bignum-bench: A practical benchmark for evaluating low-level code reasoning of LLMs
Mar 15, 2026Neurosymbolic approaches leveraging Large Language Models (LLMs) with formal methods have recently achieved strong results on mathematics-oriented theorem-proving benchmarks. However, success on competition-style mathematics does not by itself demonstrate the ability to construct proofs about real-world implementations. We address this gap with a benchmark derived from an industrial cryptographic library whose assembly routines are already verified in HOL Light. s2n-bignum is a library used at AWS for providing fast assembly routines for cryptography, and its correctness is established by formal verification. The task of formally verifying this library has been a significant achievement for the Automated Reasoning Group. It involved two tasks: (1) precisely specifying the correct behavior of a program as a mathematical proposition, and (2) proving that the proposition is correct. In the case of s2n-bignum, both tasks were carried out by human experts. In \textit{s2n-bignum-bench}, we provide the formal specification and ask the LLM to generate a proof script that is accepted by HOL Light within a fixed proof-check timeout. To our knowledge, \textit{s2n-bignum-bench} is the first public benchmark focused on machine-checkable proof synthesis for industrial low-level cryptographic assembly routines in HOL Light. This benchmark provides a challenging and practically relevant testbed for evaluating LLM-based theorem proving beyond competition mathematics. The code to set up and use the benchmark is available here: \href{https://github.com/kings-crown/s2n-bignum-bench}{s2n-bignum-bench}.
Neural Theorem Proving: Generating and Structuring Proofs for Formal Verification
Apr 23, 2025

Formally verifying properties of software code has been a highly desirable task, especially with the emergence of LLM-generated code. In the same vein, they provide an interesting avenue for the exploration of formal verification and mechanistic interpretability. Since the introduction of code-specific models, despite their successes in generating code in Lean4 and Isabelle, the task of generalized theorem proving still remains far from being fully solved and will be a benchmark for reasoning capability in LLMs. In this work, we introduce a framework that generates whole proofs in a formal language to be used within systems that utilize the power of built-in tactics and off-the-shelf automated theorem provers. Our framework includes 3 components: generating natural language statements of the code to be verified, an LLM that generates formal proofs for the given statement, and a module employing heuristics for building the final proof. To train the LLM, we employ a 2-stage fine-tuning process, where we first use SFT-based training to enable the model to generate syntactically correct Isabelle code and then RL-based training that encourages the model to generate proofs verified by a theorem prover. We validate our framework using the miniF2F-test benchmark and the Isabelle proof assistant and design a use case to verify the correctness of the AWS S3 bucket access policy code. We also curate a dataset based on the FVEL\textsubscript{\textnormal{ER}} dataset for future training tasks.
Learning Multimodal Latent Space with EBM Prior and MCMC Inference
Aug 20, 2024Multimodal generative models are crucial for various applications. We propose an approach that combines an expressive energy-based model (EBM) prior with Markov Chain Monte Carlo (MCMC) inference in the latent space for multimodal generation. The EBM prior acts as an informative guide, while MCMC inference, specifically through short-run Langevin dynamics, brings the posterior distribution closer to its true form. This method not only provides an expressive prior to better capture the complexity of multimodality but also improves the learning of shared latent variables for more coherent generation across modalities. Our proposed method is supported by empirical experiments, underscoring the effectiveness of our EBM prior with MCMC inference in enhancing cross-modal and joint generative tasks in multimodal contexts.
Ensuring Responsible Sourcing of Large Language Model Training Data Through Knowledge Graph Comparison
Jul 02, 2024In light of recent plagiarism allegations Brough by publishers, newspapers, and other creators of copyrighted corpora against large language model (LLM) developers, we propose a novel system, a variant of a plagiarism detection system, that assesses whether a knowledge source has been used in the training or fine-tuning of a large language model. Unlike current methods, we utilize an approach that uses Resource Description Framework (RDF) triples to create knowledge graphs from both a source document and a LLM continuation of that document. These graphs are then analyzed with respect to content using cosine similarity and with respect to structure using a normalized version of graph edit distance that shows the degree of isomorphism. Unlike traditional systems that focus on content matching and keyword identification between a source and target corpus, our approach enables a broader evaluation of similarity and thus a more accurate comparison of the similarity between a source document and LLM continuation by focusing on relationships between ideas and their organization with regards to others. Additionally, our approach does not require access to LLM metrics like perplexity that may be unavailable in closed large language modeling "black-box" systems, as well as the training corpus. A prototype of our system will be found on a hyperlinked GitHub repository.
Reducing Large Language Model Bias with Emphasis on 'Restricted Industries': Automated Dataset Augmentation and Prejudice Quantification
Mar 20, 2024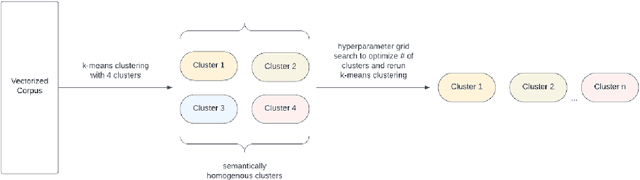
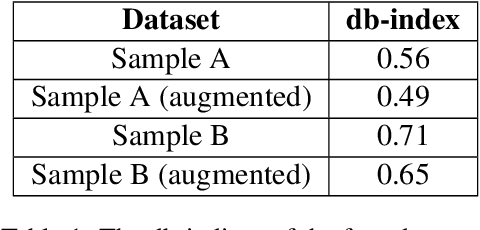
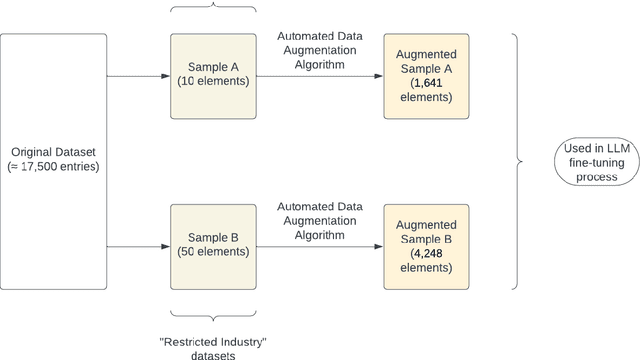
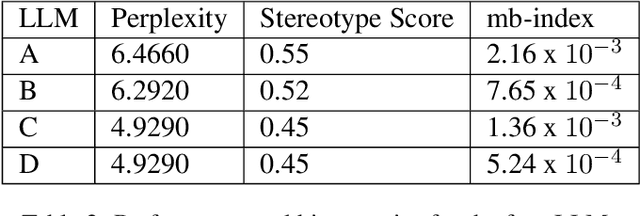
Despite the growing capabilities of large language models, there exists concerns about the biases they develop. In this paper, we propose a novel, automated mechanism for debiasing through specified dataset augmentation in the lens of bias producers and in the context of 'restricted industries' with limited data. We additionally create two new additional metrics, the mb-index and db-index, to quantify bias, considering the idea that bias occurs due to both intrinsic model architecture and dataset.
Tell me the truth: A system to measure the trustworthiness of Large Language Models
Mar 11, 2024Large Language Models (LLM) have taken the front seat in most of the news since November 2022, when ChatGPT was introduced. After more than one year, one of the major reasons companies are resistant to adopting them is the limited confidence they have in the trustworthiness of those systems. In a study by (Baymard, 2023), ChatGPT-4 showed an 80.1% false-positive error rate in identifying usability issues on websites. A Jan. '24 study by JAMA Pediatrics found that ChatGPT has an accuracy rate of 17% percent when diagnosing pediatric medical cases (Barile et al., 2024). But then, what is "trust"? Trust is a relative, subject condition that can change based on culture, domain, individuals. And then, given a domain, how can the trustworthiness of a system be measured? In this paper, I present a systematic approach to measure trustworthiness based on a predefined ground truth, represented as a knowledge graph of the domain. The approach is a process with humans in the loop to validate the representation of the domain and to fine-tune the system. Measuring the trustworthiness would be essential for all the entities operating in critical environments, such as healthcare, defense, finance, but it would be very relevant for all the users of LLMs.
From Ambiguity to Explicitness: NLP-Assisted 5G Specification Abstraction for Formal Analysis
Aug 07, 2023



Formal method-based analysis of the 5G Wireless Communication Protocol is crucial for identifying logical vulnerabilities and facilitating an all-encompassing security assessment, especially in the design phase. Natural Language Processing (NLP) assisted techniques and most of the tools are not widely adopted by the industry and research community. Traditional formal verification through a mathematics approach heavily relied on manual logical abstraction prone to being time-consuming, and error-prone. The reason that the NLP-assisted method did not apply in industrial research may be due to the ambiguity in the natural language of the protocol designs nature is controversial to the explicitness of formal verification. To address the challenge of adopting the formal methods in protocol designs, targeting (3GPP) protocols that are written in natural language, in this study, we propose a hybrid approach to streamline the analysis of protocols. We introduce a two-step pipeline that first uses NLP tools to construct data and then uses constructed data to extract identifiers and formal properties by using the NLP model. The identifiers and formal properties are further used for formal analysis. We implemented three models that take different dependencies between identifiers and formal properties as criteria. Our results of the optimal model reach valid accuracy of 39% for identifier extraction and 42% for formal properties predictions. Our work is proof of concept for an efficient procedure in performing formal analysis for largescale complicate specification and protocol analysis, especially for 5G and nextG communications.
Information Extraction in Domain and Generic Documents: Findings from Heuristic-based and Data-driven Approaches
Jun 30, 2023Information extraction (IE) plays very important role in natural language processing (NLP) and is fundamental to many NLP applications that used to extract structured information from unstructured text data. Heuristic-based searching and data-driven learning are two main stream implementation approaches. However, no much attention has been paid to document genre and length influence on IE tasks. To fill the gap, in this study, we investigated the accuracy and generalization abilities of heuristic-based searching and data-driven to perform two IE tasks: named entity recognition (NER) and semantic role labeling (SRL) on domain-specific and generic documents with different length. We posited two hypotheses: first, short documents may yield better accuracy results compared to long documents; second, generic documents may exhibit superior extraction outcomes relative to domain-dependent documents due to training document genre limitations. Our findings reveals that no single method demonstrated overwhelming performance in both tasks. For named entity extraction, data-driven approaches outperformed symbolic methods in terms of accuracy, particularly in short texts. In the case of semantic roles extraction, we observed that heuristic-based searching method and data-driven based model with syntax representation surpassed the performance of pure data-driven approach which only consider semantic information. Additionally, we discovered that different semantic roles exhibited varying accuracy levels with the same method. This study offers valuable insights for downstream text mining tasks, such as NER and SRL, when addressing various document features and genres.
Natural Language in Requirements Engineering for Structure Inference -- An Integrative Review
Feb 10, 2022



The automatic extraction of structure from text can be difficult for machines. Yet, the elicitation of this information can provide many benefits and opportunities for various applications. Benefits have also been identified for the area of Requirements Engineering. To evaluate what work has been done and is currently available, the paper at hand provides an integrative review regarding Natural Language Processing (NLP) tools for Requirements Engineering. This assessment was conducted to provide a foundation for future work as well as deduce insights from the stats quo. To conduct the review, the history of Requirements Engineering and NLP are described as well as an evaluation of over 136 NLP tools. To assess these tools, a set of criteria was defined. The results are that currently no open source approach exists that allows for the direct/primary extraction of information structure and even closed source solutions show limitations such as supervision or input limitations, which eliminates the possibility for fully automatic and universal application. As a results, the authors deduce that the current approaches are not applicable and a different methodology is necessary. An approach that allows for individual management of the algorithm, knowledge base, and text corpus is a possibility being pursued.
A computational model implementing subjectivity with the 'Room Theory'. The case of detecting Emotion from Text
May 12, 2020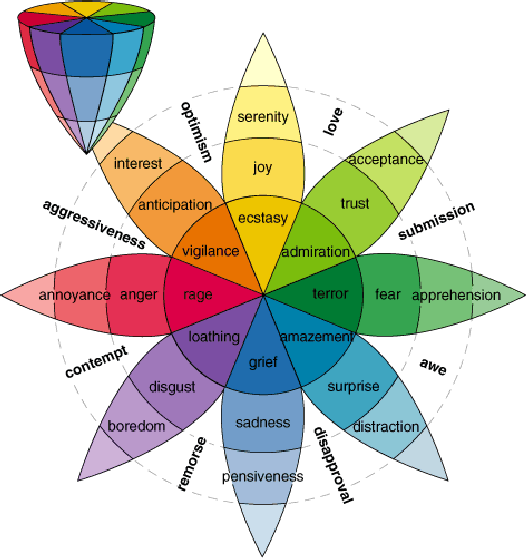
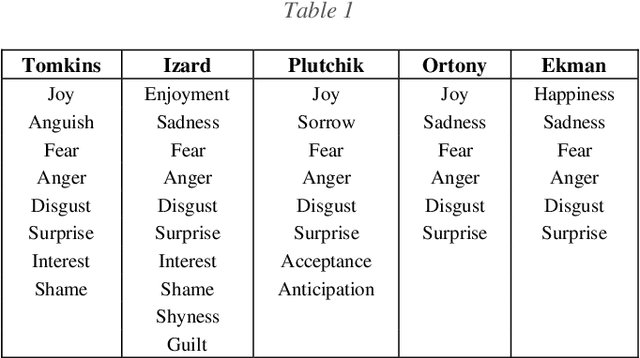
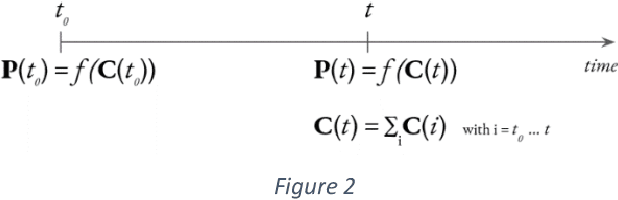

This work introduces a new method to consider subjectivity and general context dependency in text analysis and uses as example the detection of emotions conveyed in text. The proposed method takes into account subjectivity using a computational version of the Framework Theory by Marvin Minsky (1974) leveraging on the Word2Vec approach to text vectorization by Mikolov et al. (2013), used to generate distributed representation of words based on the context where they appear. Our approach is based on three components: 1. a framework/'room' representing the point of view; 2. a benchmark representing the criteria for the analysis - in this case the emotion classification, from a study of human emotions by Robert Plutchik (1980); and 3. the document to be analyzed. By using similarity measure between words, we are able to extract the relative relevance of the elements in the benchmark - intensities of emotions in our case study - for the document to be analyzed. Our method provides a measure that take into account the point of view of the entity reading the document. This method could be applied to all the cases where evaluating subjectivity is relevant to understand the relative value or meaning of a text. Subjectivity can be not limited to human reactions, but it could be used to provide a text with an interpretation related to a given domain ("room"). To evaluate our method, we used a test case in the political domain.