Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Large Language Model Bias with Emphasis on 'Restricted Industries': Automated Dataset Augmentation and Prejudice Quantification
Paper and Code
Mar 20, 2024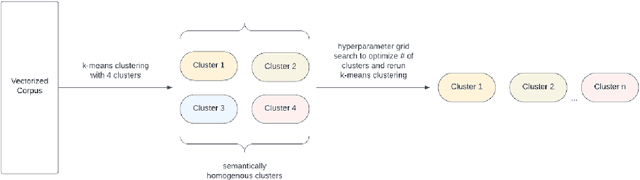
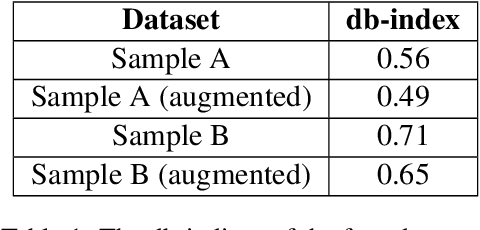
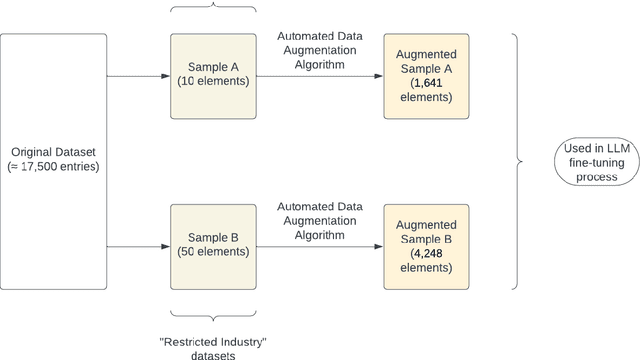
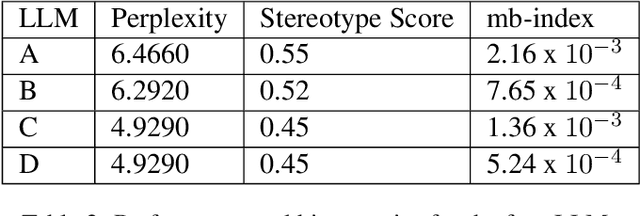
Despite the growing capabilities of large language models, there exists concerns about the biases they develop. In this paper, we propose a novel, automated mechanism for debiasing through specified dataset augmentation in the lens of bias producers and in the context of 'restricted industries' with limited data. We additionally create two new additional metrics, the mb-index and db-index, to quantify bias, considering the idea that bias occurs due to both intrinsic model architecture and dataset.
View paper on