 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEBMs Trained with Maximum Likelihood are Generator Models Trained with a Self-adverserial Loss
Paper and Code
Feb 23, 2021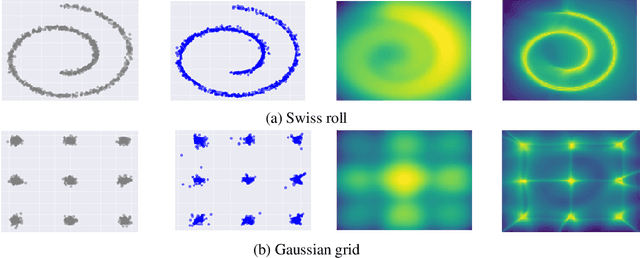



Maximum likelihood estimation is widely used in training Energy-based models (EBMs). Training requires samples from an unnormalized distribution, which is usually intractable, and in practice, these are obtained by MCMC algorithms such as Langevin dynamics. However, since MCMC in high-dimensional space converges extremely slowly, the current understanding of maximum likelihood training, which assumes approximate samples from the model can be drawn, is problematic. In this paper, we try to understand this training procedure by replacing Langevin dynamics with deterministic solutions of the associated gradient descent ODE. Doing so allows us to study the density induced by the dynamics (if the dynamics are invertible), and connect with GANs by treating the dynamics as generator models, the initial values as latent variables and the loss as optimizing a critic defined by the very same energy that determines the generator through its gradient. Hence the term - self-adversarial loss. We show that reintroducing the noise in the dynamics does not lead to a qualitative change in the behavior, and merely reduces the quality of the generator. We thus show that EBM training is effectively a self-adversarial procedure rather than maximum likelihood estimation.