 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo We Really Need to Learn Representations from In-domain Data for Outlier Detection?
Paper and Code
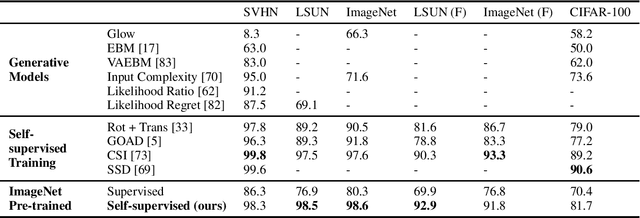
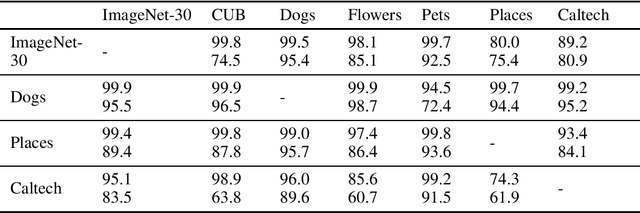
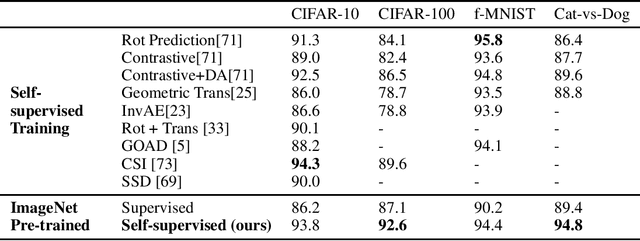

Unsupervised outlier detection, which predicts if a test sample is an outlier or not using only the information from unlabelled inlier data, is an important but challenging task. Recently, methods based on the two-stage framework achieve state-of-the-art performance on this task. The framework leverages self-supervised representation learning algorithms to train a feature extractor on inlier data, and applies a simple outlier detector in the feature space. In this paper, we explore the possibility of avoiding the high cost of training a distinct representation for each outlier detection task, and instead using a single pre-trained network as the universal feature extractor regardless of the source of in-domain data. In particular, we replace the task-specific feature extractor by one network pre-trained on ImageNet with a self-supervised loss. In experiments, we demonstrate competitive or better performance on a variety of outlier detection benchmarks compared with previous two-stage methods, suggesting that learning representations from in-domain data may be unnecessary for outlier detection.