 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Language Model Policy Optimization via Risk-aware Stepwise Alignment
Dec 30, 2025When fine-tuning pre-trained Language Models (LMs) to exhibit desired behaviors, maintaining control over risk is critical for ensuring both safety and trustworthiness. Most existing safety alignment methods, such as Safe RLHF and SACPO, typically operate under a risk-neutral paradigm that is insufficient to address the risks arising from deviations from the reference policy and offers limited robustness against rare but potentially catastrophic harmful behaviors. To address this limitation, we propose Risk-aware Stepwise Alignment (RSA), a novel alignment method that explicitly incorporates risk awareness into the policy optimization process by leveraging a class of nested risk measures. Specifically, RSA formulates safety alignment as a token-level risk-aware constrained policy optimization problem and solves it through a stepwise alignment procedure that yields token-level policy updates derived from the nested risk measures. This design offers two key benefits: (1) it mitigates risks induced by excessive model shift away from a reference policy, and (2) it explicitly suppresses low-probability yet high-impact harmful behaviors. Moreover, we provide theoretical analysis on policy optimality under mild assumptions. Experimental results demonstrate that our method achieves high levels of helpfulness while ensuring strong safety and significantly suppresses tail risks, namely low-probability yet high-impact unsafe responses.
Explaining Black-box Language Models with Knowledge Probing Systems: A Post-hoc Explanation Perspective
Aug 23, 2025Pre-trained Language Models (PLMs) are trained on large amounts of unlabeled data, yet they exhibit remarkable reasoning skills. However, the trustworthiness challenges posed by these black-box models have become increasingly evident in recent years. To alleviate this problem, this paper proposes a novel Knowledge-guided Probing approach called KnowProb in a post-hoc explanation way, which aims to probe whether black-box PLMs understand implicit knowledge beyond the given text, rather than focusing only on the surface level content of the text. We provide six potential explanations derived from the underlying content of the given text, including three knowledge-based understanding and three association-based reasoning. In experiments, we validate that current small-scale (or large-scale) PLMs only learn a single distribution of representation, and still face significant challenges in capturing the hidden knowledge behind a given text. Furthermore, we demonstrate that our proposed approach is effective for identifying the limitations of existing black-box models from multiple probing perspectives, which facilitates researchers to promote the study of detecting black-box models in an explainable way.
C-LoRA: Continual Low-Rank Adaptation for Pre-trained Models
Feb 25, 2025



Low-Rank Adaptation (LoRA) is an efficient fine-tuning method that has been extensively applied in areas such as natural language processing and computer vision. Existing LoRA fine-tuning approaches excel in static environments but struggle in dynamic learning due to reliance on multiple adapter modules, increasing overhead and complicating inference. We propose Continual Low-Rank Adaptation (C-LoRA), a novel extension of LoRA for continual learning. C-LoRA uses a learnable routing matrix to dynamically manage parameter updates across tasks, ensuring efficient reuse of learned subspaces while enforcing orthogonality to minimize interference and forgetting. Unlike existing approaches that require separate adapters for each task, C-LoRA enables a integrated approach for task adaptation, achieving both scalability and parameter efficiency in sequential learning scenarios. C-LoRA achieves state-of-the-art accuracy and parameter efficiency on benchmarks while providing theoretical insights into its routing matrix's role in retaining and transferring knowledge, establishing a scalable framework for continual learning.
Progressive Local Alignment for Medical Multimodal Pre-training
Feb 25, 2025Local alignment between medical images and text is essential for accurate diagnosis, though it remains challenging due to the absence of natural local pairings and the limitations of rigid region recognition methods. Traditional approaches rely on hard boundaries, which introduce uncertainty, whereas medical imaging demands flexible soft region recognition to handle irregular structures. To overcome these challenges, we propose the Progressive Local Alignment Network (PLAN), which designs a novel contrastive learning-based approach for local alignment to establish meaningful word-pixel relationships and introduces a progressive learning strategy to iteratively refine these relationships, enhancing alignment precision and robustness. By combining these techniques, PLAN effectively improves soft region recognition while suppressing noise interference. Extensive experiments on multiple medical datasets demonstrate that PLAN surpasses state-of-the-art methods in phrase grounding, image-text retrieval, object detection, and zero-shot classification, setting a new benchmark for medical image-text alignment.
GNN-Transformer Cooperative Architecture for Trustworthy Graph Contrastive Learning
Dec 24, 2024



Graph contrastive learning (GCL) has become a hot topic in the field of graph representation learning. In contrast to traditional supervised learning relying on a large number of labels, GCL exploits augmentation strategies to generate multiple views and positive/negative pairs, both of which greatly influence the performance. Unfortunately, commonly used random augmentations may disturb the underlying semantics of graphs. Moreover, traditional GNNs, a type of widely employed encoders in GCL, are inevitably confronted with over-smoothing and over-squashing problems. To address these issues, we propose GNN-Transformer Cooperative Architecture for Trustworthy Graph Contrastive Learning (GTCA), which inherits the advantages of both GNN and Transformer, incorporating graph topology to obtain comprehensive graph representations. Theoretical analysis verifies the trustworthiness of the proposed method. Extensive experiments on benchmark datasets demonstrate state-of-the-art empirical performance.
Towards Effective Graph Rationalization via Boosting Environment Diversity
Dec 17, 2024



Graph Neural Networks (GNNs) perform effectively when training and testing graphs are drawn from the same distribution, but struggle to generalize well in the face of distribution shifts. To address this issue, existing mainstreaming graph rationalization methods first identify rationale and environment subgraphs from input graphs, and then diversify training distributions by augmenting the environment subgraphs. However, these methods merely combine the learned rationale subgraphs with environment subgraphs in the representation space to produce augmentation samples, failing to produce sufficiently diverse distributions. Thus, in this paper, we propose to achieve an effective Graph Rationalization by Boosting Environmental diversity, a GRBE approach that generates the augmented samples in the original graph space to improve the diversity of the environment subgraph. Firstly, to ensure the effectiveness of augmentation samples, we propose a precise rationale subgraph extraction strategy in GRBE to refine the rationale subgraph learning process in the original graph space. Secondly, to ensure the diversity of augmented samples, we propose an environment diversity augmentation strategy in GRBE that mixes the environment subgraphs of different graphs in the original graph space and then combines the new environment subgraphs with rationale subgraphs to generate augmented graphs. The average improvements of 7.65% and 6.11% in rationalization and classification performance on benchmark datasets demonstrate the superiority of GRBE over state-of-the-art approaches.
Graph External Attention Enhanced Transformer
Jun 03, 2024The Transformer architecture has recently gained considerable attention in the field of graph representation learning, as it naturally overcomes several limitations of Graph Neural Networks (GNNs) with customized attention mechanisms or positional and structural encodings. Despite making some progress, existing works tend to overlook external information of graphs, specifically the correlation between graphs. Intuitively, graphs with similar structures should have similar representations. Therefore, we propose Graph External Attention (GEA) -- a novel attention mechanism that leverages multiple external node/edge key-value units to capture inter-graph correlations implicitly. On this basis, we design an effective architecture called Graph External Attention Enhanced Transformer (GEAET), which integrates local structure and global interaction information for more comprehensive graph representations. Extensive experiments on benchmark datasets demonstrate that GEAET achieves state-of-the-art empirical performance. The source code is available for reproducibility at: https://github.com/icm1018/GEAET.
PipeOptim: Ensuring Effective 1F1B Schedule with Optimizer-Dependent Weight Prediction
Dec 05, 2023Asynchronous pipeline model parallelism with a "1F1B" (one forward, one backward) schedule generates little bubble overhead and always provides quite a high throughput. However, the "1F1B" schedule inevitably leads to weight inconsistency and weight staleness issues due to the cross-training of different mini-batches across GPUs. To simultaneously address these two problems, in this paper, we propose an optimizer-dependent weight prediction strategy (a.k.a PipeOptim) for asynchronous pipeline training. The key insight of our proposal is that we employ a weight prediction strategy in the forward pass to ensure that each mini-batch uses consistent and staleness-free weights to compute the forward pass. To be concrete, we first construct the weight prediction scheme based on the update rule of the used optimizer when training the deep neural network models. Then throughout the "1F1B" pipelined training, each mini-batch is mandated to execute weight prediction ahead of the forward pass, subsequently employing the predicted weights to perform the forward pass. As a result, PipeOptim 1) inherits the advantage of the "1F1B" schedule and generates pretty high throughput, and 2) can ensure effective parameter learning regardless of the type of the used optimizer. To verify the effectiveness of our proposal, we conducted extensive experimental evaluations using eight different deep-learning models spanning three machine-learning tasks including image classification, sentiment analysis, and machine translation. The experiment results demonstrate that PipeOptim outperforms the popular pipelined approaches including GPipe, PipeDream, PipeDream-2BW, and SpecTrain. The code of PipeOptim can be accessible at https://github.com/guanleics/PipeOptim.
Towards Privacy-Aware Causal Structure Learning in Federated Setting
Nov 13, 2022



Causal structure learning has been extensively studied and widely used in machine learning and various applications. To achieve an ideal performance, existing causal structure learning algorithms often need to centralize a large amount of data from multiple data sources. However, in the privacy-preserving setting, it is impossible to centralize data from all sources and put them together as a single dataset. To preserve data privacy, federated learning as a new learning paradigm has attached much attention in machine learning in recent years. In this paper, we study a privacy-aware causal structure learning problem in the federated setting and propose a novel Federated PC (FedPC) algorithm with two new strategies for preserving data privacy without centralizing data. Specifically, we first propose a novel layer-wise aggregation strategy for a seamless adaptation of the PC algorithm into the federated learning paradigm for federated skeleton learning, then we design an effective strategy for learning consistent separation sets for federated edge orientation. The extensive experiments validate that FedPC is effective for causal structure learning in federated learning setting.
Sparse Regularized Correlation Filter for UAV Object Tracking with adaptive Contextual Learning and Keyfilter Selection
May 07, 2022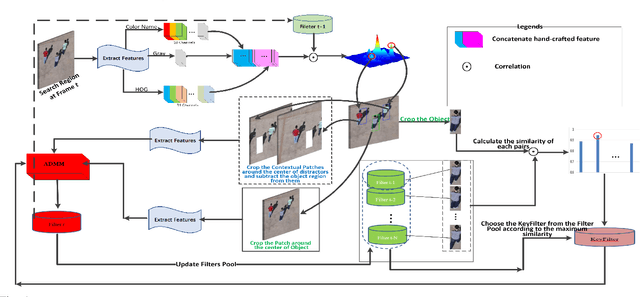
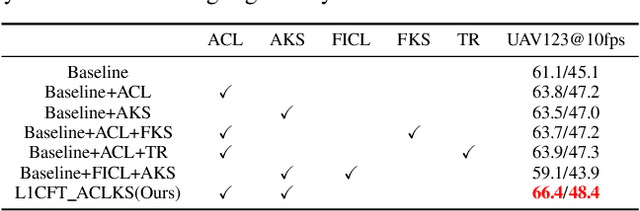
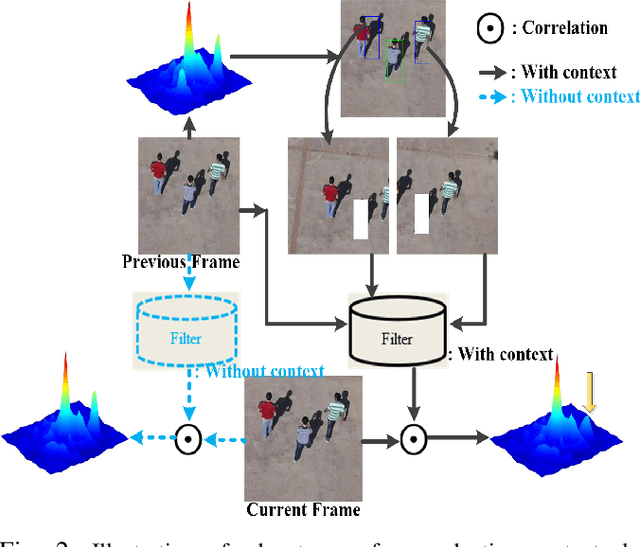

Recently, correlation filter has been widely applied in unmanned aerial vehicle (UAV) tracking due to its high frame rates, robustness and low calculation resources. However, it is fragile because of two inherent defects, i.e, boundary effect and filter corruption. Some methods by enlarging the search area can mitigate the boundary effect, yet introducing the undesired background distractors. Another approaches can alleviate the temporal degeneration of learned filters by introducing the temporal regularizer, which depends on the assumption that the filers between consecutive frames should be coherent. In fact, sometimes the filers at the ($t-1$)th frame is vulnerable to heavy occlusion from backgrounds, which causes that the assumption does not hold. To handle them, in this work, we propose a novel $\ell_{1}$ regularization correlation filter with adaptive contextual learning and keyfilter selection for UAV tracking. Firstly, we adaptively detect the positions of effective contextual distractors by the aid of the distribution of local maximum values on the response map of current frame which is generated by using the previous correlation filter model. Next, we eliminate inconsistent labels for the tracked target by removing one on each distractor and develop a new score scheme for each distractor. Then, we can select the keyfilter from the filters pool by finding the maximal similarity between the target at the current frame and the target template corresponding to each filter in the filters pool. Finally, quantitative and qualitative experiments on three authoritative UAV datasets show that the proposed method is superior to the state-of-the-art tracking methods based on correlation filter framework.