 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Deep Graph Embedding with High-Order Information Fusion for Community Discovery
Feb 08, 2021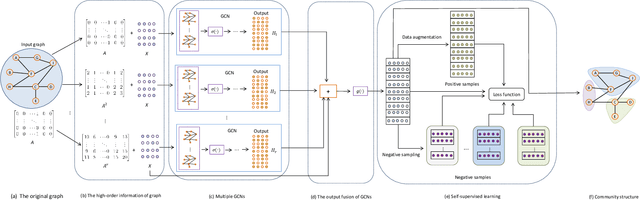
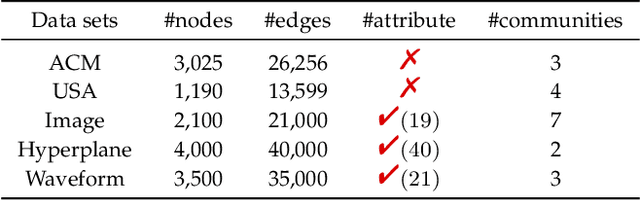

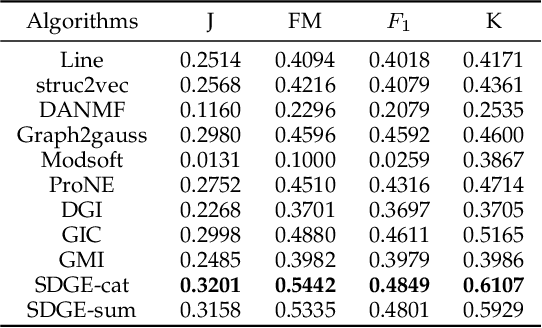
Deep graph embedding is an important approach for community discovery. Deep graph neural network with self-supervised mechanism can obtain the low-dimensional embedding vectors of nodes from unlabeled and unstructured graph data. The high-order information of graph can provide more abundant structure information for the representation learning of nodes. However, most self-supervised graph neural networks only use adjacency matrix as the input topology information of graph and cannot obtain too high-order information since the number of layers of graph neural network is fairly limited. If there are too many layers, the phenomenon of over smoothing will appear. Therefore how to obtain and fuse high-order information of graph by a shallow graph neural network is an important problem. In this paper, a deep graph embedding algorithm with self-supervised mechanism for community discovery is proposed. The proposed algorithm uses self-supervised mechanism and different high-order information of graph to train multiple deep graph convolution neural networks. The outputs of multiple graph convolution neural networks are fused to extract the representations of nodes which include the attribute and structure information of a graph. In addition, data augmentation and negative sampling are introduced into the training process to facilitate the improvement of embedding result. The proposed algorithm and the comparison algorithms are conducted on the five experimental data sets. The experimental results show that the proposed algorithm outperforms the comparison algorithms on the most experimental data sets. The experimental results demonstrate that the proposed algorithm is an effective algorithm for community discovery.
Rough extreme learning machine: a new classification method based on uncertainty measure
Mar 10, 2018
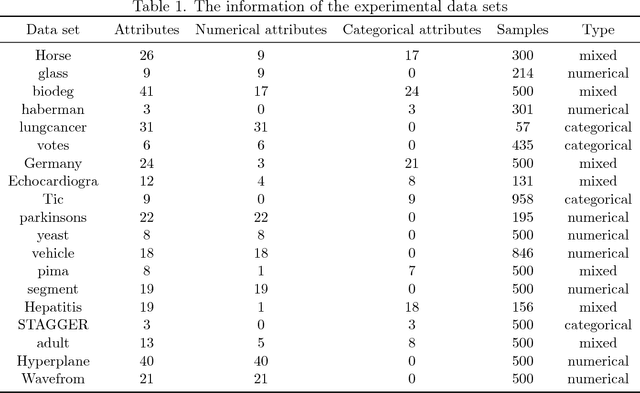
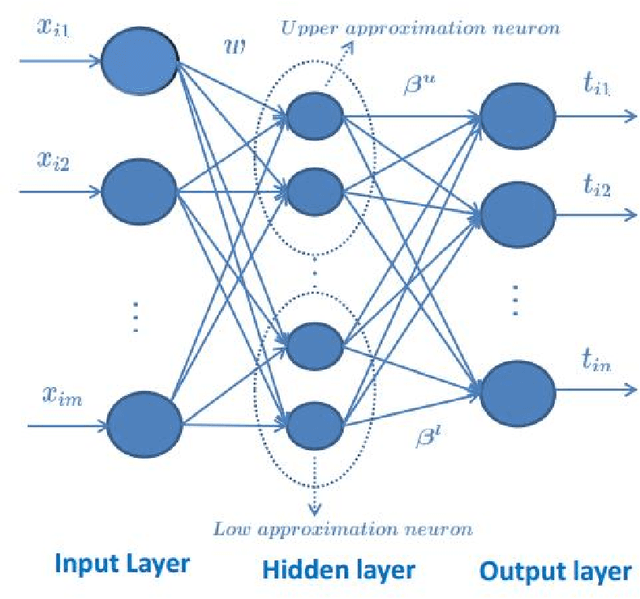
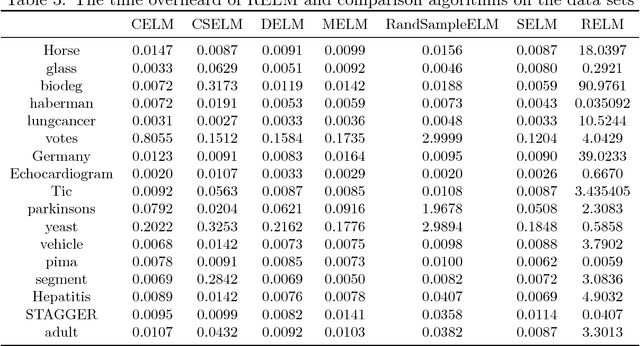
Extreme learning machine (ELM) is a new single hidden layer feedback neural network. The weights of the input layer and the biases of neurons in hidden layer are randomly generated, the weights of the output layer can be analytically determined. ELM has been achieved good results for a large number of classification tasks. In this paper, a new extreme learning machine called rough extreme learning machine (RELM) was proposed. RELM uses rough set to divide data into upper approximation set and lower approximation set, and the two approximation sets are utilized to train upper approximation neurons and lower approximation neurons. In addition, an attribute reduction is executed in this algorithm to remove redundant attributes. The experimental results showed, comparing with the comparison algorithms, RELM can get a better accuracy and repeatability in most cases, RELM can not only maintain the advantages of fast speed, but also effectively cope with the classification task for high-dimensional data.
An Ensemble Classification Algorithm Based on Information Entropy for Data Streams
Aug 11, 2017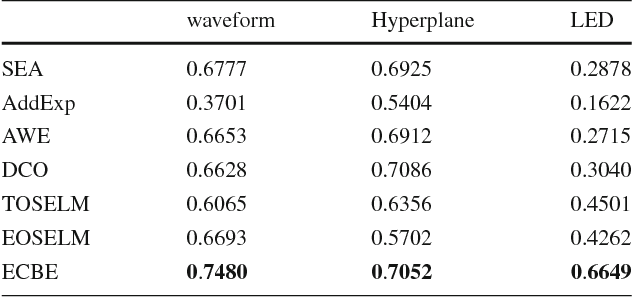
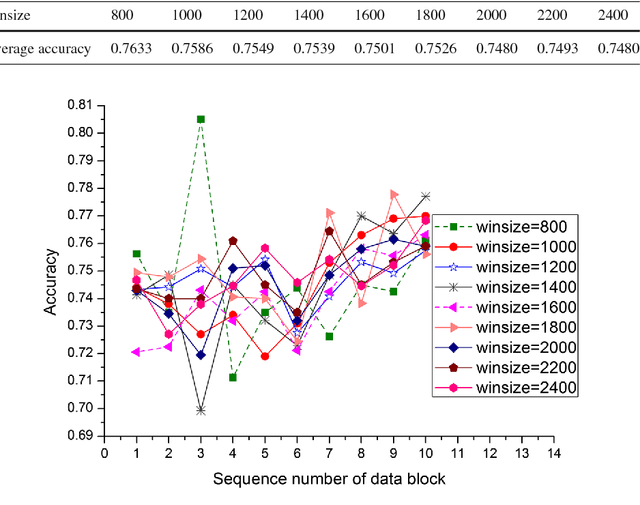
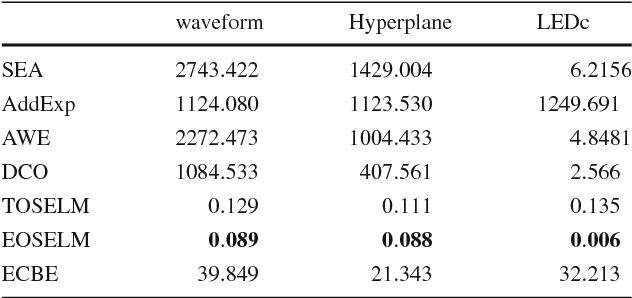
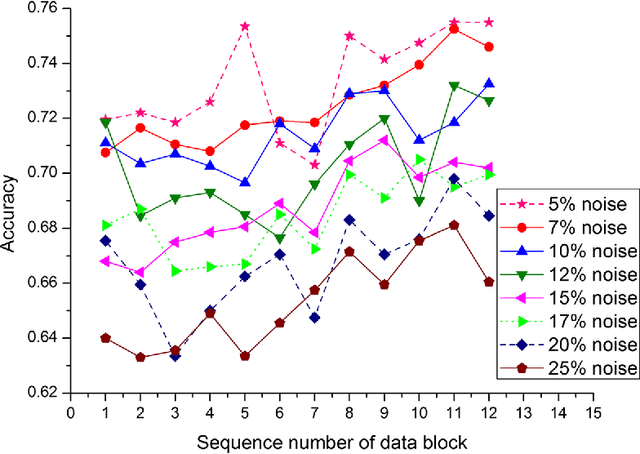
Data stream mining problem has caused widely concerns in the area of machine learning and data mining. In some recent studies, ensemble classification has been widely used in concept drift detection, however, most of them regard classification accuracy as a criterion for judging whether concept drift happening or not. Information entropy is an important and effective method for measuring uncertainty. Based on the information entropy theory, a new algorithm using information entropy to evaluate a classification result is developed. It uses ensemble classification techniques, and the weight of each classifier is decided through the entropy of the result produced by an ensemble classifiers system. When the concept in data streams changing, the classifiers' weight below a threshold value will be abandoned to adapt to a new concept in one time. In the experimental analysis section, six databases and four proposed algorithms are executed. The results show that the proposed method can not only handle concept drift effectively, but also have a better classification accuracy and time performance than the contrastive algorithms.