 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA fast online cascaded regression algorithm for face alignment
May 10, 2019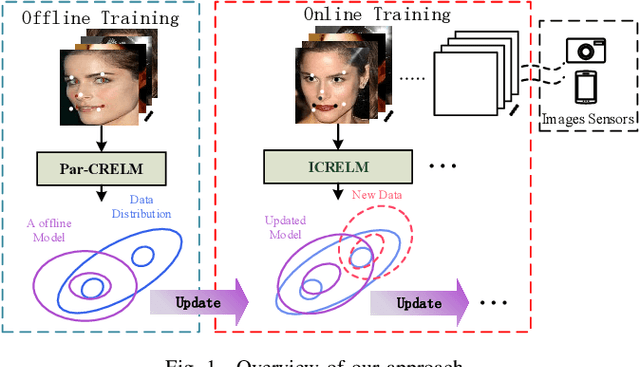
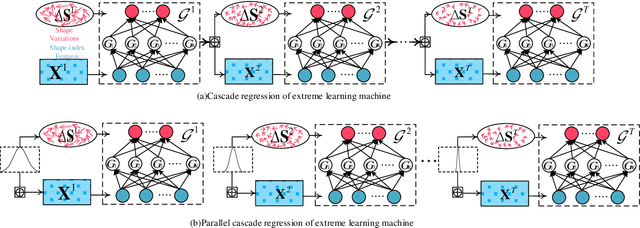
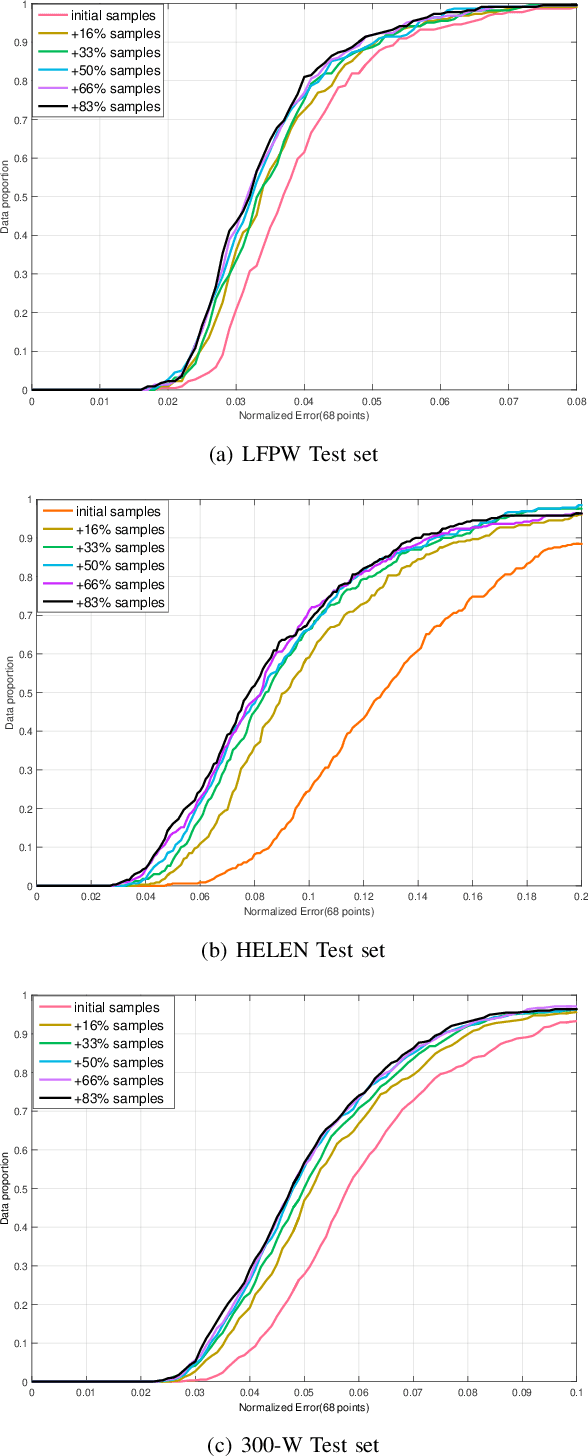
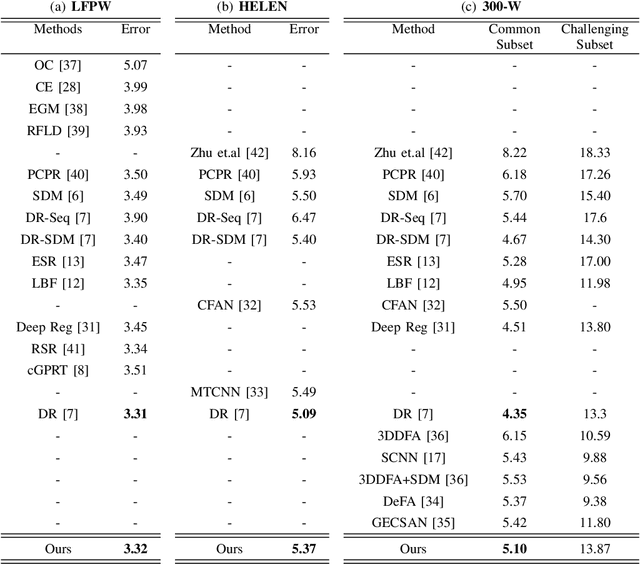
Traditional face alignment based on machine learning usually tracks the localizations of facial landmarks employing a static model trained offline where all of the training data is available in advance. When new training samples arrive, the static model must be retrained from scratch, which is excessively time-consuming and memory-consuming. In many real-time applications, the training data is obtained one by one or batch by batch. It results in that the static model limits its performance on sequential images with extensive variations. Therefore, the most critical and challenging aspect in this field is dynamically updating the tracker's models to enhance predictive and generalization capabilities continuously. In order to address this question, we develop a fast and accurate online learning algorithm for face alignment. Particularly, we incorporate on-line sequential extreme learning machine into a parallel cascaded regression framework, coined incremental cascade regression(ICR). To the best of our knowledge, this is the first incremental cascaded framework with the non-linear regressor. One main advantage of ICR is that the tracker model can be fast updated in an incremental way without the entire retraining process when a new input is incoming. Experimental results demonstrate that the proposed ICR is more accurate and efficient on still or sequential images compared with the recent state-of-the-art cascade approaches. Furthermore, the incremental learning proposed in this paper can update the trained model in real time.
Bottom-up Broadcast Neural Network For Music Genre Classification
Jan 24, 2019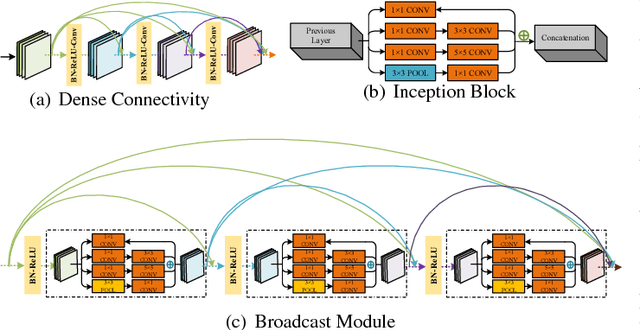

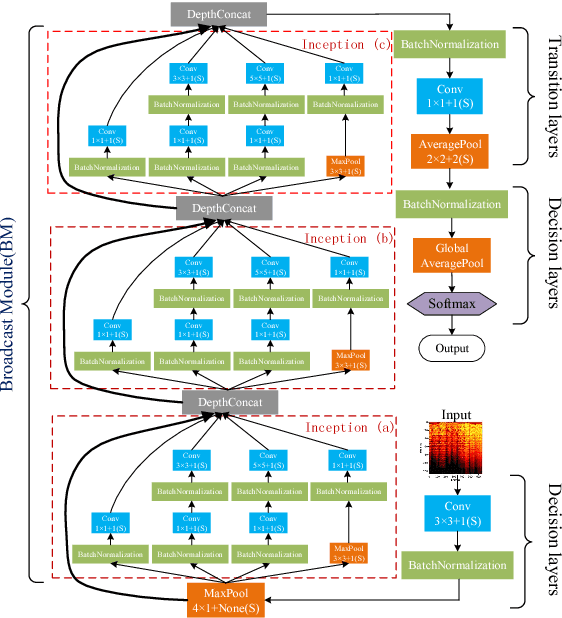
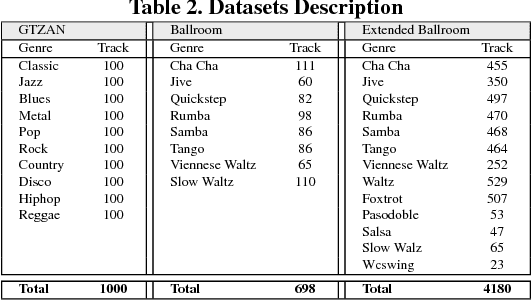
Music genre recognition based on visual representation has been successfully explored over the last years. Recently, there has been increasing interest in attempting convolutional neural networks (CNNs) to achieve the task. However, most of existing methods employ the mature CNN structures proposed in image recognition without any modification, which results in the learning features that are not adequate for music genre classification. Faced with the challenge of this issue, we fully exploit the low-level information from spectrograms of audios and develop a novel CNN architecture in this paper. The proposed CNN architecture takes the long contextual information into considerations, which transfers more suitable information for the decision-making layer. Various experiments on several benchmark datasets, including GTZAN, Ballroom, and Extended Ballroom, have verified the excellent performances of the proposed neural network. Codes and model will be available at "ttps://github.com/CaifengLiu/music-genre-classification".
An Ensemble Classification Algorithm Based on Information Entropy for Data Streams
Aug 11, 2017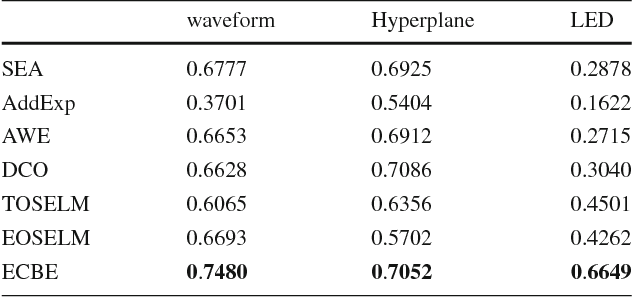
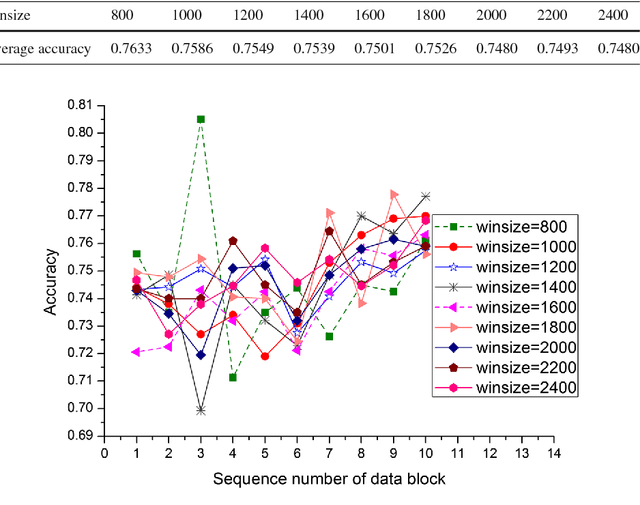
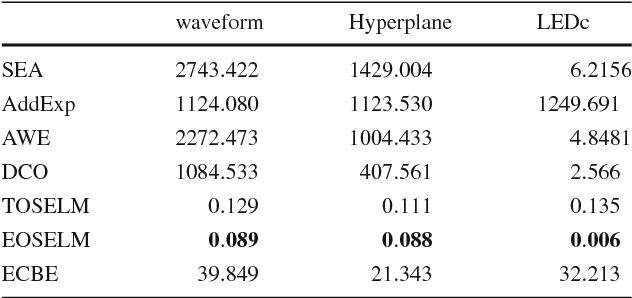
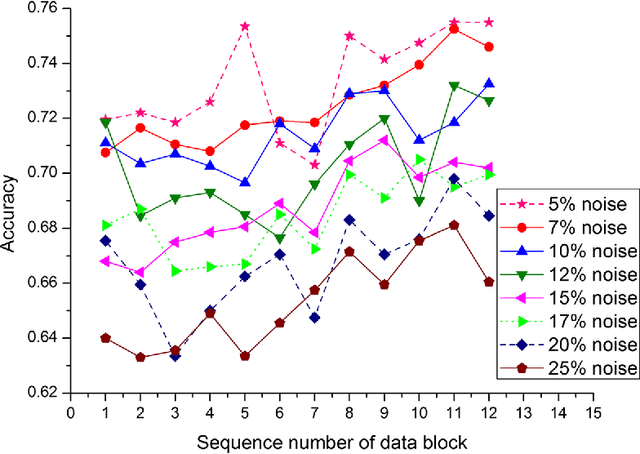
Data stream mining problem has caused widely concerns in the area of machine learning and data mining. In some recent studies, ensemble classification has been widely used in concept drift detection, however, most of them regard classification accuracy as a criterion for judging whether concept drift happening or not. Information entropy is an important and effective method for measuring uncertainty. Based on the information entropy theory, a new algorithm using information entropy to evaluate a classification result is developed. It uses ensemble classification techniques, and the weight of each classifier is decided through the entropy of the result produced by an ensemble classifiers system. When the concept in data streams changing, the classifiers' weight below a threshold value will be abandoned to adapt to a new concept in one time. In the experimental analysis section, six databases and four proposed algorithms are executed. The results show that the proposed method can not only handle concept drift effectively, but also have a better classification accuracy and time performance than the contrastive algorithms.