 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Privacy-Aware Causal Structure Learning in Federated Setting
Nov 13, 2022



Causal structure learning has been extensively studied and widely used in machine learning and various applications. To achieve an ideal performance, existing causal structure learning algorithms often need to centralize a large amount of data from multiple data sources. However, in the privacy-preserving setting, it is impossible to centralize data from all sources and put them together as a single dataset. To preserve data privacy, federated learning as a new learning paradigm has attached much attention in machine learning in recent years. In this paper, we study a privacy-aware causal structure learning problem in the federated setting and propose a novel Federated PC (FedPC) algorithm with two new strategies for preserving data privacy without centralizing data. Specifically, we first propose a novel layer-wise aggregation strategy for a seamless adaptation of the PC algorithm into the federated learning paradigm for federated skeleton learning, then we design an effective strategy for learning consistent separation sets for federated edge orientation. The extensive experiments validate that FedPC is effective for causal structure learning in federated learning setting.
Causality-based Feature Selection: Methods and Evaluations
Nov 17, 2019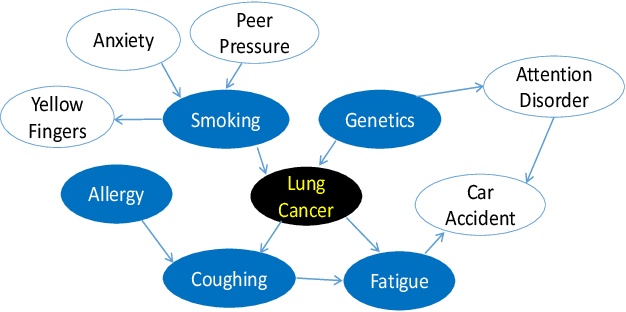
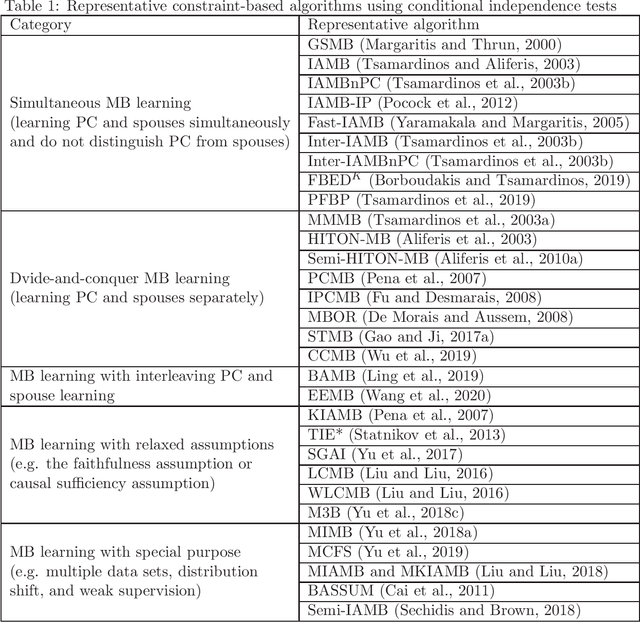

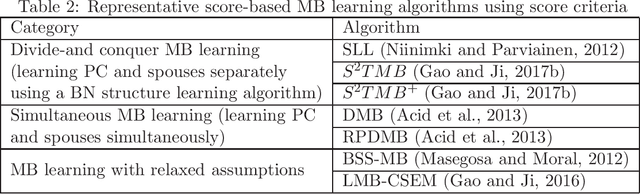
Feature selection is a crucial preprocessing step in data analytics and machine learning. Classical feature selection algorithms select features based on the correlations between predictive features and the class variable and do not attempt to capture causal relationships between them. It has been shown that the knowledge about the causal relationships between features and the class variable has potential benefits for building interpretable and robust prediction models, since causal relationships imply the underlying mechanism of a system. Consequently, causality-based feature selection has gradually attracted greater attentions and many algorithms have been proposed. In this paper, we present a comprehensive review of recent advances in causality-based feature selection. To facilitate the development of new algorithms in the research area and make it easy for the comparisons between new methods and existing ones, we develop the first open-source package, called CausalFS, which consists of most of the representative causality-based feature selection algorithms (available at https://github.com/kuiy/CausalFS). Using CausalFS, we conduct extensive experiments to compare the representative algorithms with both synthetic and real-world data sets. Finally, we discuss some challenging problems to be tackled in future causality-based feature selection research.