 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEMENTO: Teaching LLMs to Manage Their Own Context
Apr 10, 2026Reasoning models think in long, unstructured streams with no mechanism for compressing or organizing their own intermediate state. We introduce MEMENTO: a method that teaches models to segment reasoning into blocks, compress each block into a memento, i.e., a dense state summary, and reason forward by attending only to mementos, reducing context, KV cache, and compute. To train MEMENTO models, we release OpenMementos, a public dataset of 228K reasoning traces derived from OpenThoughts-v3, segmented and annotated with intermediate summaries. We show that a two-stage SFT recipe on OpenMementos is effective across different model families (Qwen3, Phi-4, Olmo 3) and scales (8B--32B parameters). Trained models maintain strong accuracy on math, science, and coding benchmarks while achieving ${\sim}2.5\times$ peak KV cache reduction. We extend vLLM to support our inference method, achieving ${\sim}1.75\times$ throughput improvement while also enabling us to perform RL and further improve accuracy. Finally, we identify a dual information stream: information from each reasoning block is carried both by the memento text and by the corresponding KV states, which retain implicit information from the original block. Removing this channel drops accuracy by 15\,pp on AIME24.
Demonstrations, CoT, and Prompting: A Theoretical Analysis of ICL
Mar 20, 2026In-Context Learning (ICL) enables pretrained LLMs to adapt to downstream tasks by conditioning on a small set of input-output demonstrations, without any parameter updates. Although there have been many theoretical efforts to explain how ICL works, most either rely on strong architectural or data assumptions, or fail to capture the impact of key practical factors such as demonstration selection, Chain-of-Thought (CoT) prompting, the number of demonstrations, and prompt templates. We address this gap by establishing a theoretical analysis of ICL under mild assumptions that links these design choices to generalization behavior. We derive an upper bound on the ICL test loss, showing that performance is governed by (i) the quality of selected demonstrations, quantified by Lipschitz constants of the ICL loss along paths connecting test prompts to pretraining samples, (ii) an intrinsic ICL capability of the pretrained model, and (iii) the degree of distribution shift. Within the same framework, we analyze CoT prompting as inducing a task decomposition and show that it is beneficial when demonstrations are well chosen at each substep and the resulting subtasks are easier to learn. Finally, we characterize how ICL performance sensitivity to prompt templates varies with the number of demonstrations. Together, our study shows that pretraining equips the model with the ability to generalize beyond observed tasks, while CoT enables the model to compose simpler subtasks into more complex ones, and demonstrations and instructions enable it to retrieve similar or complex tasks, including those that can be composed into more complex ones, jointly supporting generalization to unseen tasks. All theoretical insights are corroborated by experiments.
ParallelBench: Understanding the Trade-offs of Parallel Decoding in Diffusion LLMs
Oct 06, 2025While most autoregressive LLMs are constrained to one-by-one decoding, diffusion LLMs (dLLMs) have attracted growing interest for their potential to dramatically accelerate inference through parallel decoding. Despite this promise, the conditional independence assumption in dLLMs causes parallel decoding to ignore token dependencies, inevitably degrading generation quality when these dependencies are strong. However, existing works largely overlook these inherent challenges, and evaluations on standard benchmarks (e.g., math and coding) are not sufficient to capture the quality degradation caused by parallel decoding. To address this gap, we first provide an information-theoretic analysis of parallel decoding. We then conduct case studies on analytically tractable synthetic list operations from both data distribution and decoding strategy perspectives, offering quantitative insights that highlight the fundamental limitations of parallel decoding. Building on these insights, we propose ParallelBench, the first benchmark specifically designed for dLLMs, featuring realistic tasks that are trivial for humans and autoregressive LLMs yet exceptionally challenging for dLLMs under parallel decoding. Using ParallelBench, we systematically analyze both dLLMs and autoregressive LLMs, revealing that: (i) dLLMs under parallel decoding can suffer dramatic quality degradation in real-world scenarios, and (ii) current parallel decoding strategies struggle to adapt their degree of parallelism based on task difficulty, thus failing to achieve meaningful speedup without compromising quality. Our findings underscore the pressing need for innovative decoding methods that can overcome the current speed-quality trade-off. We release our benchmark to help accelerate the development of truly efficient dLLMs.
We-Math 2.0: A Versatile MathBook System for Incentivizing Visual Mathematical Reasoning
Aug 14, 2025Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities across various tasks, but still struggle with complex mathematical reasoning. Existing research primarily focuses on dataset construction and method optimization, often overlooking two critical aspects: comprehensive knowledge-driven design and model-centric data space modeling. In this paper, we introduce We-Math 2.0, a unified system that integrates a structured mathematical knowledge system, model-centric data space modeling, and a reinforcement learning (RL)-based training paradigm to comprehensively enhance the mathematical reasoning abilities of MLLMs. The key contributions of We-Math 2.0 are fourfold: (1) MathBook Knowledge System: We construct a five-level hierarchical system encompassing 491 knowledge points and 1,819 fundamental principles. (2) MathBook-Standard & Pro: We develop MathBook-Standard, a dataset that ensures broad conceptual coverage and flexibility through dual expansion. Additionally, we define a three-dimensional difficulty space and generate 7 progressive variants per problem to build MathBook-Pro, a challenging dataset for robust training. (3) MathBook-RL: We propose a two-stage RL framework comprising: (i) Cold-Start Fine-tuning, which aligns the model with knowledge-oriented chain-of-thought reasoning; and (ii) Progressive Alignment RL, leveraging average-reward learning and dynamic data scheduling to achieve progressive alignment across difficulty levels. (4) MathBookEval: We introduce a comprehensive benchmark covering all 491 knowledge points with diverse reasoning step distributions. Experimental results show that MathBook-RL performs competitively with existing baselines on four widely-used benchmarks and achieves strong results on MathBookEval, suggesting promising generalization in mathematical reasoning.
TabFlex: Scaling Tabular Learning to Millions with Linear Attention
Jun 05, 2025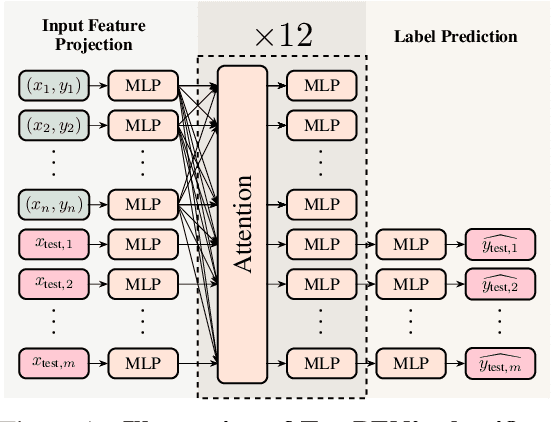
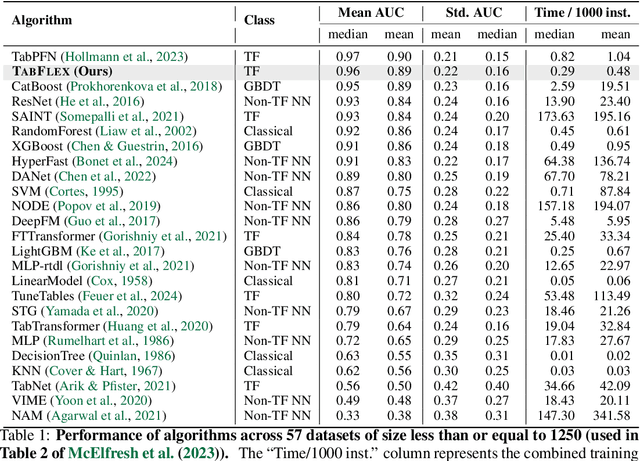
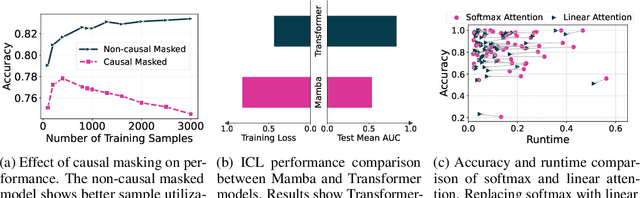
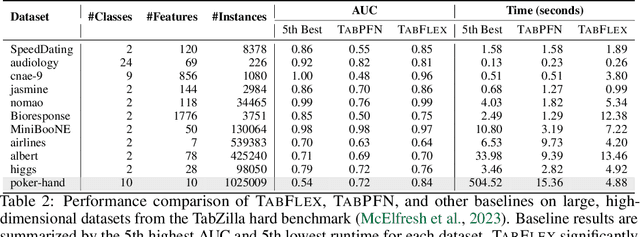
Leveraging the in-context learning (ICL) capability of Large Language Models (LLMs) for tabular classification has gained significant attention for its training-free adaptability across diverse datasets. Recent advancements, like TabPFN, excel in small-scale tabular datasets but struggle to scale for large and complex datasets. Our work enhances the efficiency and scalability of TabPFN for larger datasets by incorporating linear attention mechanisms as a scalable alternative to complexity-quadratic self-attention. Our model, TabFlex, efficiently handles tabular datasets with thousands of features and hundreds of classes, scaling seamlessly to millions of samples. For instance, TabFlex processes the poker-hand dataset with over a million samples in just 5 seconds. Our extensive evaluations demonstrate that TabFlex can achieve over a 2x speedup compared to TabPFN and a 1.5x speedup over XGBoost, outperforming 25 tested baselines in terms of efficiency across a diverse range of datasets. Furthermore, TabFlex remains highly effective on large-scale datasets, delivering strong performance with significantly reduced computational costs, especially when combined with data-efficient techniques such as dimensionality reduction and data sampling.
State-offset Tuning: State-based Parameter-Efficient Fine-Tuning for State Space Models
Mar 05, 2025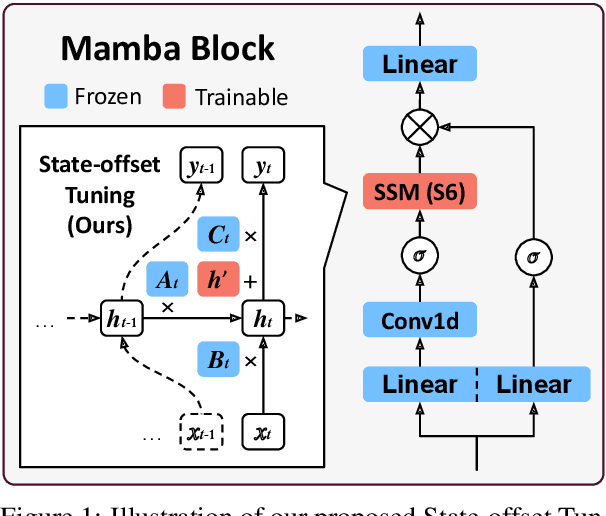


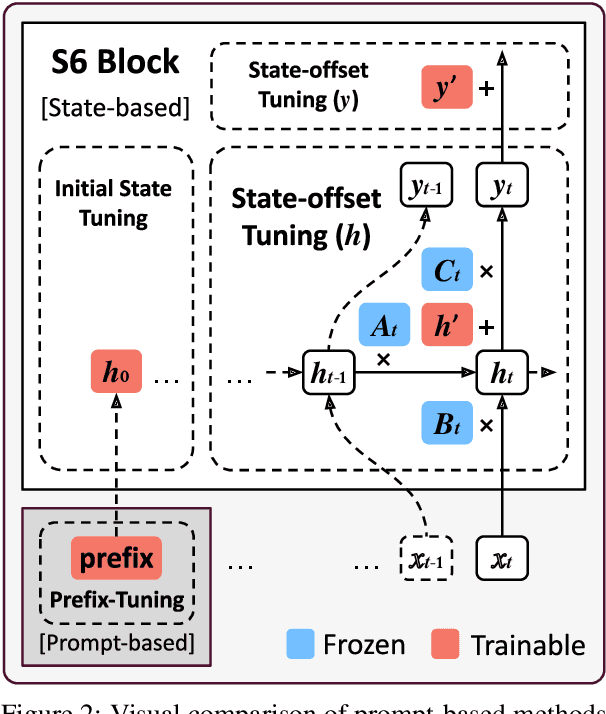
State Space Models (SSMs) have emerged as efficient alternatives to Transformers, mitigating their quadratic computational cost. However, the application of Parameter-Efficient Fine-Tuning (PEFT) methods to SSMs remains largely unexplored. In particular, prompt-based methods like Prompt Tuning and Prefix-Tuning, which are widely used in Transformers, do not perform well on SSMs. To address this, we propose state-based methods as a superior alternative to prompt-based methods. This new family of methods naturally stems from the architectural characteristics of SSMs. State-based methods adjust state-related features directly instead of depending on external prompts. Furthermore, we introduce a novel state-based PEFT method: State-offset Tuning. At every timestep, our method directly affects the state at the current step, leading to more effective adaptation. Through extensive experiments across diverse datasets, we demonstrate the effectiveness of our method. Code is available at https://github.com/furiosa-ai/ssm-state-tuning.
DARWIN 1.5: Large Language Models as Materials Science Adapted Learners
Dec 16, 2024Materials discovery and design aim to find components and structures with desirable properties over highly complex and diverse search spaces. Traditional solutions, such as high-throughput simulations and machine learning (ML), often rely on complex descriptors, which hinder generalizability and transferability across tasks. Moreover, these descriptors may deviate from experimental data due to inevitable defects and purity issues in the real world, which may reduce their effectiveness in practical applications. To address these challenges, we propose Darwin 1.5, an open-source large language model (LLM) tailored for materials science. By leveraging natural language as input, Darwin eliminates the need for task-specific descriptors and enables a flexible, unified approach to material property prediction and discovery. We employ a two-stage training strategy combining question-answering (QA) fine-tuning with multi-task learning (MTL) to inject domain-specific knowledge in various modalities and facilitate cross-task knowledge transfer. Through our strategic approach, we achieved a significant enhancement in the prediction accuracy of LLMs, with a maximum improvement of 60\% compared to LLaMA-7B base models. It further outperforms traditional machine learning models on various tasks in material science, showcasing the potential of LLMs to provide a more versatile and scalable foundation model for materials discovery and design.
Parameter-Efficient Fine-Tuning of State Space Models
Oct 11, 2024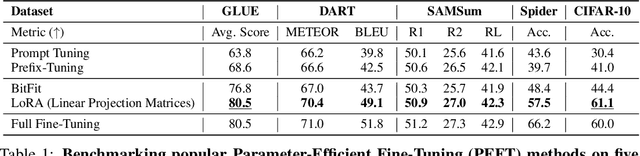
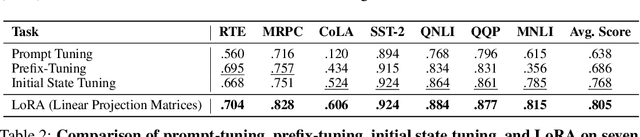
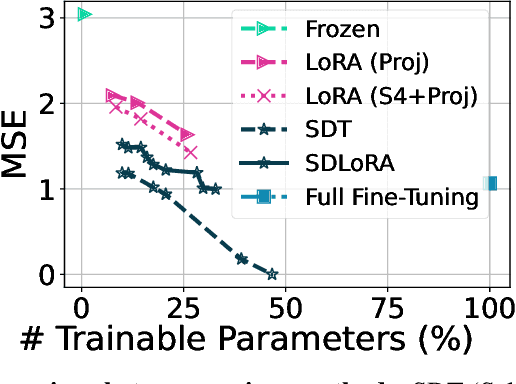
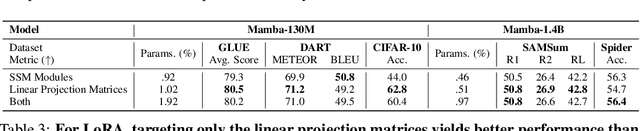
Deep State Space Models (SSMs), such as Mamba (Gu & Dao, 2024), have emerged as powerful tools for language modeling, offering high performance with efficient inference and linear scaling in sequence length. However, the application of parameter-efficient fine-tuning (PEFT) methods to SSM-based models remains largely unexplored. This paper aims to systematically study two key questions: (i) How do existing PEFT methods perform on SSM-based models? (ii) Which modules are most effective for fine-tuning? We conduct an empirical benchmark of four basic PEFT methods on SSM-based models. Our findings reveal that prompt-based methods (e.g., prefix-tuning) are no longer effective, an empirical result further supported by theoretical analysis. In contrast, LoRA remains effective for SSM-based models. We further investigate the optimal application of LoRA within these models, demonstrating both theoretically and experimentally that applying LoRA to linear projection matrices without modifying SSM modules yields the best results, as LoRA is not effective at tuning SSM modules. To further improve performance, we introduce LoRA with Selective Dimension tuning (SDLoRA), which selectively updates certain channels and states on SSM modules while applying LoRA to linear projection matrices. Extensive experimental results show that this approach outperforms standard LoRA.
Can MLLMs Perform Text-to-Image In-Context Learning?
Feb 02, 2024



The evolution from Large Language Models (LLMs) to Multimodal Large Language Models (MLLMs) has spurred research into extending In-Context Learning (ICL) to its multimodal counterpart. Existing such studies have primarily concentrated on image-to-text ICL. However, the Text-to-Image ICL (T2I-ICL), with its unique characteristics and potential applications, remains underexplored. To address this gap, we formally define the task of T2I-ICL and present CoBSAT, the first T2I-ICL benchmark dataset, encompassing ten tasks. Utilizing our dataset to benchmark six state-of-the-art MLLMs, we uncover considerable difficulties MLLMs encounter in solving T2I-ICL. We identify the primary challenges as the inherent complexity of multimodality and image generation. To overcome these challenges, we explore strategies like fine-tuning and Chain-of-Thought prompting, demonstrating notable improvements. Our code and dataset are available at \url{https://github.com/UW-Madison-Lee-Lab/CoBSAT}.
The Expressive Power of Low-Rank Adaptation
Oct 27, 2023Low-Rank Adaptation (LoRA), a parameter-efficient fine-tuning method that leverages low-rank adaptation of weight matrices, has emerged as a prevalent technique for fine-tuning pre-trained models such as large language models and diffusion models. Despite its huge success in practice, the theoretical underpinnings of LoRA have largely remained unexplored. This paper takes the first step to bridge this gap by theoretically analyzing the expressive power of LoRA. We prove that, for fully connected neural networks, LoRA can adapt any model $f$ to accurately represent any smaller target model $\overline{f}$ if LoRA-rank $\geq(\text{width of }f) \times \frac{\text{depth of }\overline{f}}{\text{depth of }f}$. We also quantify the approximation error when LoRA-rank is lower than the threshold. For Transformer networks, we show any model can be adapted to a target model of the same size with rank-$(\frac{\text{embedding size}}{2})$ LoRA adapters.