 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Bin Batching for Increasing LLM Inference Throughput
Dec 03, 2024



As large language models (LLMs) grow in popularity for their diverse capabilities, improving the efficiency of their inference systems has become increasingly critical. Batching LLM requests is a critical step in scheduling the inference jobs on servers (e.g. GPUs), enabling the system to maximize throughput by allowing multiple requests to be processed in parallel. However, requests often have varying generation lengths, causing resource underutilization, as hardware must wait for the longest-running request in the batch to complete before moving to the next batch. We formalize this problem from a queueing-theoretic perspective, and aim to design a control policy which is throughput-optimal. We propose Multi-Bin Batching, a simple yet effective method that can provably improve LLM inference throughput by grouping requests with similar (predicted) execution times into predetermined bins. Through a combination of theoretical analysis and experiments, including real-world LLM inference scenarios, we demonstrate significant throughput gains compared to standard batching approaches.
Long-Term Fairness in Sequential Multi-Agent Selection with Positive Reinforcement
Jul 10, 2024



While much of the rapidly growing literature on fair decision-making focuses on metrics for one-shot decisions, recent work has raised the intriguing possibility of designing sequential decision-making to positively impact long-term social fairness. In selection processes such as college admissions or hiring, biasing slightly towards applicants from under-represented groups is hypothesized to provide positive feedback that increases the pool of under-represented applicants in future selection rounds, thus enhancing fairness in the long term. In this paper, we examine this hypothesis and its consequences in a setting in which multiple agents are selecting from a common pool of applicants. We propose the Multi-agent Fair-Greedy policy, that balances greedy score maximization and fairness. Under this policy, we prove that the resource pool and the admissions converge to a long-term fairness target set by the agents when the score distributions across the groups in the population are identical. We provide empirical evidence of existence of equilibria under non-identical score distributions through synthetic and adapted real-world datasets. We then sound a cautionary note for more complex applicant pool evolution models, under which uncoordinated behavior by the agents can cause negative reinforcement, leading to a reduction in the fraction of under-represented applicants. Our results indicate that, while positive reinforcement is a promising mechanism for long-term fairness, policies must be designed carefully to be robust to variations in the evolution model, with a number of open issues that remain to be explored by algorithm designers, social scientists, and policymakers.
Equal Improvability: A New Fairness Notion Considering the Long-term Impact
Oct 13, 2022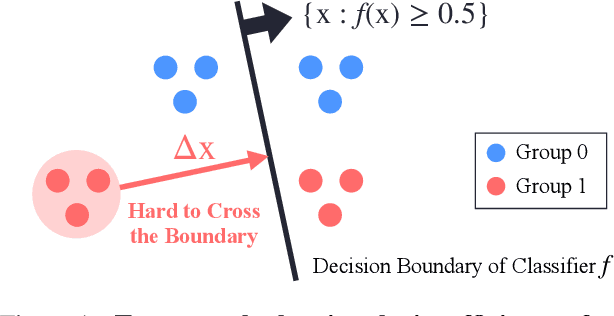

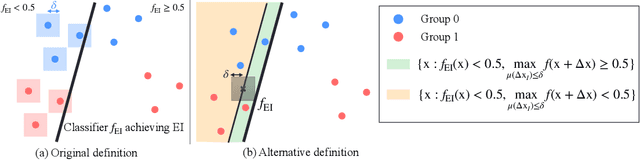
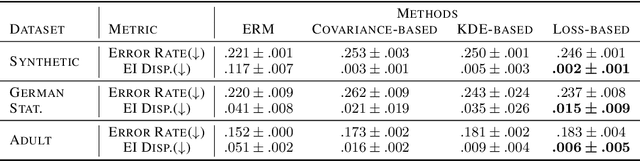
Devising a fair classifier that does not discriminate against different groups is an important problem in machine learning. Although researchers have proposed various ways of defining group fairness, most of them only focused on the immediate fairness, ignoring the long-term impact of a fair classifier under the dynamic scenario where each individual can improve its feature over time. Such dynamic scenarios happen in real world, e.g., college admission and credit loaning, where each rejected sample makes effort to change its features to get accepted afterwards. In this dynamic setting, the long-term fairness should equalize the samples' feature distribution across different groups after the rejected samples make some effort to improve. In order to promote long-term fairness, we propose a new fairness notion called Equal Improvability (EI), which equalizes the potential acceptance rate of the rejected samples across different groups assuming a bounded level of effort will be spent by each rejected sample. We analyze the properties of EI and its connections with existing fairness notions. To find a classifier that satisfies the EI requirement, we propose and study three different approaches that solve EI-regularized optimization problems. Through experiments on both synthetic and real datasets, we demonstrate that the proposed EI-regularized algorithms encourage us to find a fair classifier in terms of EI. Finally, we provide experimental results on dynamic scenarios which highlight the advantages of our EI metric in achieving the long-term fairness. Codes are available in a GitHub repository, see https://github.com/guldoganozgur/ei_fairness.