 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient Fine-Tuning of State Space Models
Paper and Code
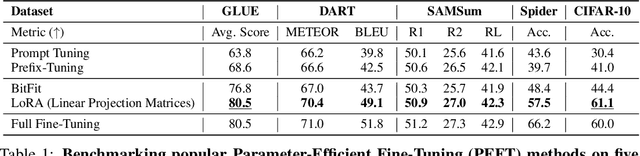
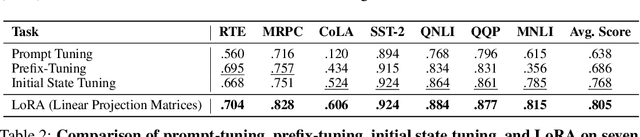
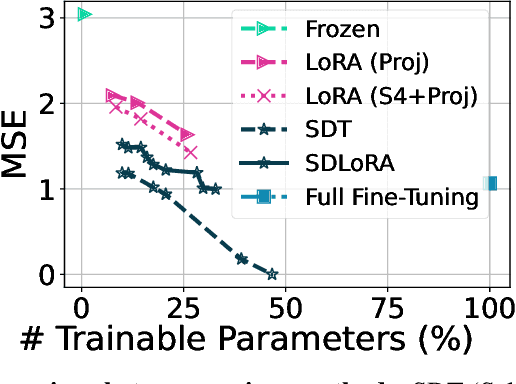
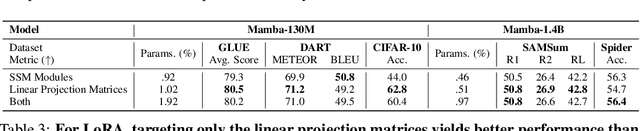
Deep State Space Models (SSMs), such as Mamba (Gu & Dao, 2024), have emerged as powerful tools for language modeling, offering high performance with efficient inference and linear scaling in sequence length. However, the application of parameter-efficient fine-tuning (PEFT) methods to SSM-based models remains largely unexplored. This paper aims to systematically study two key questions: (i) How do existing PEFT methods perform on SSM-based models? (ii) Which modules are most effective for fine-tuning? We conduct an empirical benchmark of four basic PEFT methods on SSM-based models. Our findings reveal that prompt-based methods (e.g., prefix-tuning) are no longer effective, an empirical result further supported by theoretical analysis. In contrast, LoRA remains effective for SSM-based models. We further investigate the optimal application of LoRA within these models, demonstrating both theoretically and experimentally that applying LoRA to linear projection matrices without modifying SSM modules yields the best results, as LoRA is not effective at tuning SSM modules. To further improve performance, we introduce LoRA with Selective Dimension tuning (SDLoRA), which selectively updates certain channels and states on SSM modules while applying LoRA to linear projection matrices. Extensive experimental results show that this approach outperforms standard LoRA.