 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransLaw: Benchmarking Large Language Models in Multi-Agent Simulation of the Collaborative Translation
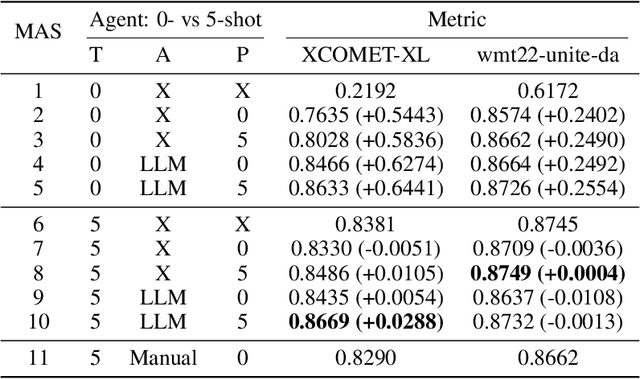
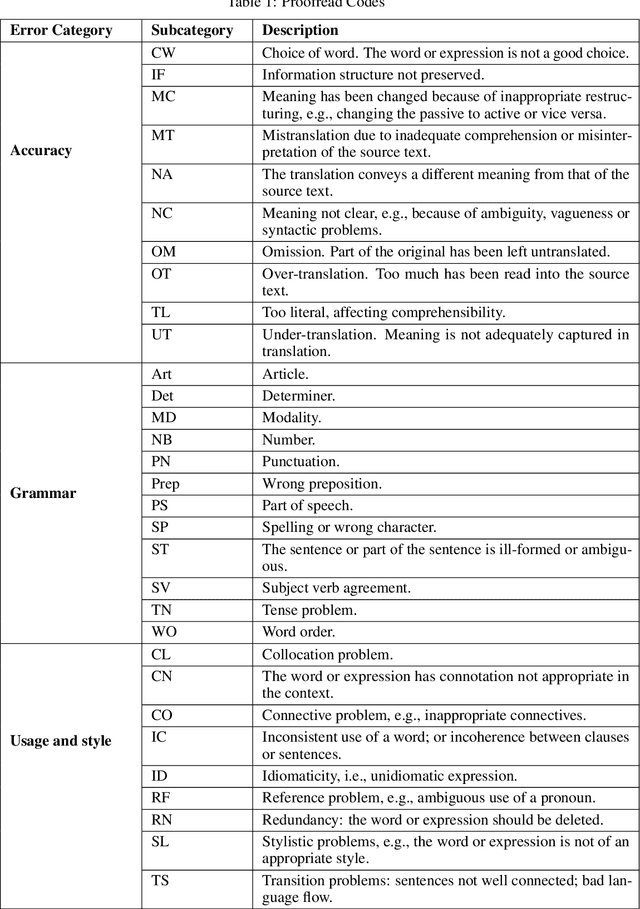
Jul 01, 2025Multi-agent systems empowered by large language models (LLMs) have demonstrated remarkable capabilities in a wide range of downstream applications, including machine translation. However, the potential of LLMs in translating Hong Kong legal judgments remains uncertain due to challenges such as intricate legal terminology, culturally embedded nuances, and strict linguistic structures. In this work, we introduce TransLaw, a novel multi-agent framework implemented for real-world Hong Kong case law translation. It employs three specialized agents, namely, Translator, Annotator, and Proofreader, to collaboratively produce translations for high accuracy in legal meaning, appropriateness in style, and adequate coherence and cohesion in structure. This framework supports customizable LLM configurations and achieves tremendous cost reduction compared to professional human translation services. We evaluated its performance using 13 open-source and commercial LLMs as agents and obtained interesting findings, including that it surpasses GPT-4o in legal semantic accuracy, structural coherence, and stylistic fidelity, yet trails human experts in contextualizing complex terminology and stylistic naturalness. Our platform website is available at CityUHK, and our bilingual judgment corpus used for the evaluation is available at Hugging Face.
Solving the unsolvable: Translating case law in Hong Kong
Jan 16, 2025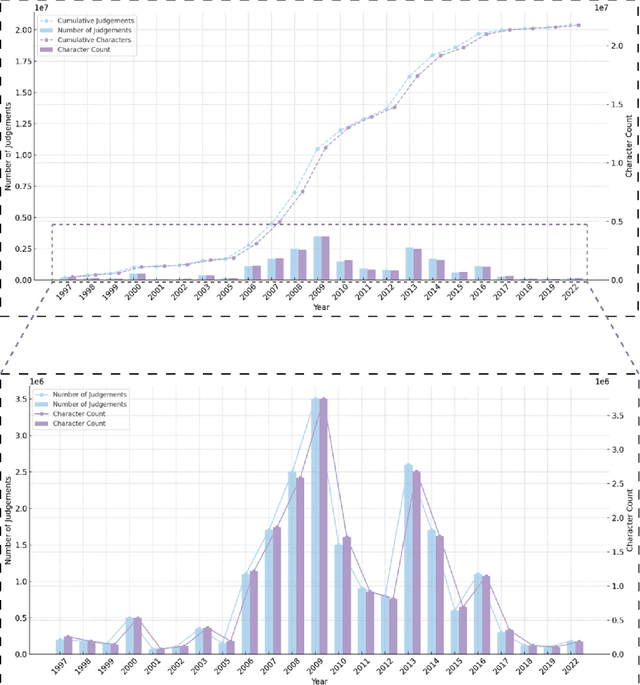

This paper addresses the challenges translating case law under Hong Kong's bilingual legal system. It highlights the initial success of translating all written statutes into Chinese before the 1997 handover, a task mandated by the Basic Law. The effort involved significant collaboration among legal, linguistic, and translation experts, resulting in a comprehensive and culturally appropriate bilingual legal system. However, translating case law remains a significant challenge due to the sheer volume and continuous growth of judicial decisions. The paper critiques the governments and judiciarys sporadic and uncoordinated efforts to translate case law, contrasting it with the thorough approach previously taken for statute translation. Although the government acknowledges the importance of legal bilingualism, it lacks a sustainable strategy for translating case law. The Judiciarys position that translating all judgments is unnecessary, unrealistic, and not cost-effectiveis analyzed and critiqued for its impact on legal transparency and public trust. A proposed solution involves leveraging machine translation technology through a human-machine interactive translation platform, which undergoes two major transitions. Initially based on a neural model, the platform transitions to using a large language model for improved translation accuracy. Furthermore, it evolves from a single-agent system to a multi-agent system, incorporating Translator, Annotator, and Proofreader agents. This multi-agent approach, supported by a grant, aims to facilitate efficient, high-quality translation of judicial judgments by integrating advanced artificial intelligence and continuous feedback mechanisms, thus better meeting the needs of a bilingual legal system.
DARWIN 1.5: Large Language Models as Materials Science Adapted Learners
Dec 16, 2024Materials discovery and design aim to find components and structures with desirable properties over highly complex and diverse search spaces. Traditional solutions, such as high-throughput simulations and machine learning (ML), often rely on complex descriptors, which hinder generalizability and transferability across tasks. Moreover, these descriptors may deviate from experimental data due to inevitable defects and purity issues in the real world, which may reduce their effectiveness in practical applications. To address these challenges, we propose Darwin 1.5, an open-source large language model (LLM) tailored for materials science. By leveraging natural language as input, Darwin eliminates the need for task-specific descriptors and enables a flexible, unified approach to material property prediction and discovery. We employ a two-stage training strategy combining question-answering (QA) fine-tuning with multi-task learning (MTL) to inject domain-specific knowledge in various modalities and facilitate cross-task knowledge transfer. Through our strategic approach, we achieved a significant enhancement in the prediction accuracy of LLMs, with a maximum improvement of 60\% compared to LLaMA-7B base models. It further outperforms traditional machine learning models on various tasks in material science, showcasing the potential of LLMs to provide a more versatile and scalable foundation model for materials discovery and design.
ByteScience: Bridging Unstructured Scientific Literature and Structured Data with Auto Fine-tuned Large Language Model in Token Granularity
Nov 18, 2024



Natural Language Processing (NLP) is widely used to supply summarization ability from long context to structured information. However, extracting structured knowledge from scientific text by NLP models remains a challenge because of its domain-specific nature to complex data preprocessing and the granularity of multi-layered device-level information. To address this, we introduce ByteScience, a non-profit cloud-based auto fine-tuned Large Language Model (LLM) platform, which is designed to extract structured scientific data and synthesize new scientific knowledge from vast scientific corpora. The platform capitalizes on DARWIN, an open-source, fine-tuned LLM dedicated to natural science. The platform was built on Amazon Web Services (AWS) and provides an automated, user-friendly workflow for custom model development and data extraction. The platform achieves remarkable accuracy with only a small amount of well-annotated articles. This innovative tool streamlines the transition from the science literature to structured knowledge and data and benefits the advancements in natural informatics.
From Tokens to Materials: Leveraging Language Models for Scientific Discovery
Oct 21, 2024



Exploring the predictive capabilities of language models in material science is an ongoing interest. This study investigates the application of language model embeddings to enhance material property prediction in materials science. By evaluating various contextual embedding methods and pre-trained models, including Bidirectional Encoder Representations from Transformers (BERT) and Generative Pre-trained Transformers (GPT), we demonstrate that domain-specific models, particularly MatBERT significantly outperform general-purpose models in extracting implicit knowledge from compound names and material properties. Our findings reveal that information-dense embeddings from the third layer of MatBERT, combined with a context-averaging approach, offer the most effective method for capturing material-property relationships from the scientific literature. We also identify a crucial "tokenizer effect," highlighting the importance of specialized text processing techniques that preserve complete compound names while maintaining consistent token counts. These insights underscore the value of domain-specific training and tokenization in materials science applications and offer a promising pathway for accelerating the discovery and development of new materials through AI-driven approaches.
SciQAG: A Framework for Auto-Generated Scientific Question Answering Dataset with Fine-grained Evaluation
May 16, 2024
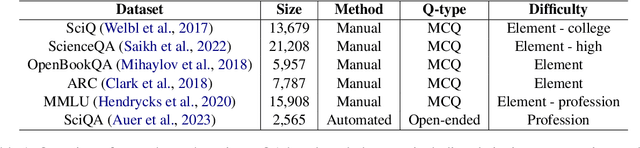


The use of question-answer (QA) pairs for training and evaluating large language models (LLMs) has attracted considerable attention. Yet few available QA datasets are based on knowledge from the scientific literature. Here we bridge this gap by presenting Automatic Generation of Scientific Question Answers (SciQAG), a framework for automatic generation and evaluation of scientific QA pairs sourced from published scientific literature. We fine-tune an open-source LLM to generate \num{960000} scientific QA pairs from full-text scientific papers and propose a five-dimensional metric to evaluate the quality of the generated QA pairs. We show via LLM-based evaluation that the generated QA pairs consistently achieve an average score of 2.5 out of 3 across five dimensions, indicating that our framework can distill key knowledge from papers into high-quality QA pairs at scale. We make the dataset, models, and evaluation codes publicly available.
DARWIN Series: Domain Specific Large Language Models for Natural Science
Aug 25, 2023



Emerging tools bring forth fresh approaches to work, and the field of natural science is no different. In natural science, traditional manual, serial, and labour-intensive work is being augmented by automated, parallel, and iterative processes driven by artificial intelligence-based experimental automation and more. To add new capabilities in natural science, enabling the acceleration and enrichment of automation of the discovery process, we present DARWIN, a series of tailored LLMs for natural science, mainly in physics, chemistry, and material science. This series relies on open-source LLM, incorporating structured and unstructured scientific knowledge from public datasets and literature. We fine-tuned the models using over 60,000 instruction data points, emphasizing factual correctness. During the fine-tuning, we introduce the Scientific Instruction Generation (SIG) model, automating instruction generation from scientific texts. This eliminates the need for manual extraction or domain-specific knowledge graphs and efficiently injects scientific knowledge into the model. We also explore multi-task training strategies, revealing interconnections between scientific tasks. DARWIN series not only achieves state-of-the-art results on various scientific tasks but also diminishes reliance on closed-source AI models. Our research showcases the ability of LLM in the scientific domain, with the overarching goal of fostering prosperity within the broader AI for science community.
Large Language Models as Master Key: Unlocking the Secrets of Materials Science with GPT
Apr 12, 2023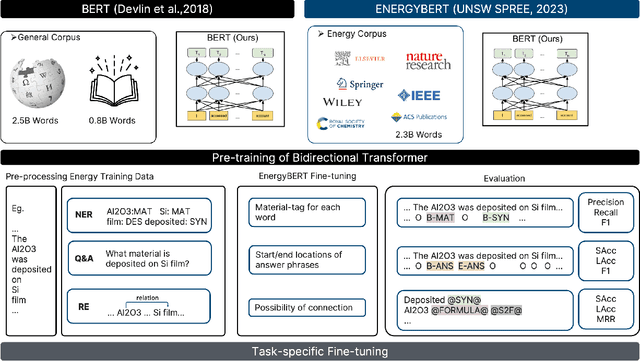

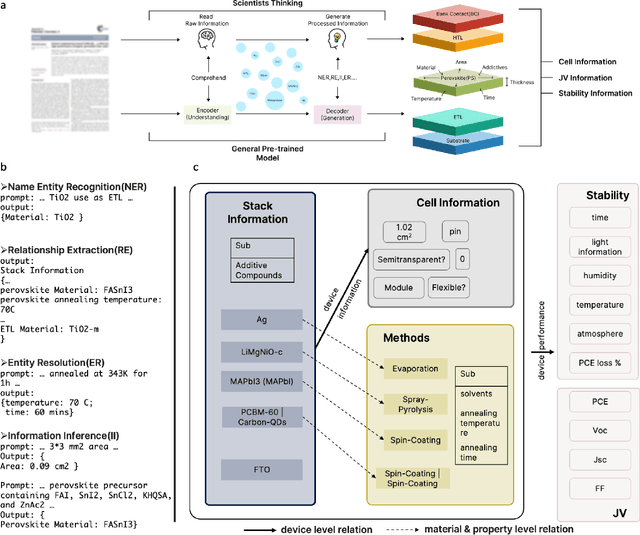

The amount of data has growing significance in exploring cutting-edge materials and a number of datasets have been generated either by hand or automated approaches. However, the materials science field struggles to effectively utilize the abundance of data, especially in applied disciplines where materials are evaluated based on device performance rather than their properties. This article presents a new natural language processing (NLP) task called structured information inference (SII) to address the complexities of information extraction at the device level in materials science. We accomplished this task by tuning GPT-3 on an existing perovskite solar cell FAIR (Findable, Accessible, Interoperable, Reusable) dataset with 91.8% F1-score and extended the dataset with data published since its release. The produced data is formatted and normalized, enabling its direct utilization as input in subsequent data analysis. This feature empowers materials scientists to develop models by selecting high-quality review articles within their domain. Additionally, we designed experiments to predict the electrical performance of solar cells and design materials or devices with targeted parameters using large language models (LLMs). Our results demonstrate comparable performance to traditional machine learning methods without feature selection, highlighting the potential of LLMs to acquire scientific knowledge and design new materials akin to materials scientists.
Interdisciplinary Discovery of Nanomaterials Based on Convolutional Neural Networks
Dec 06, 2022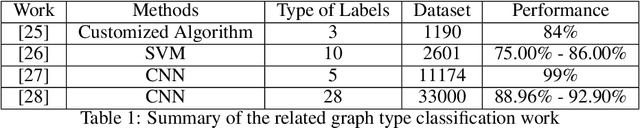
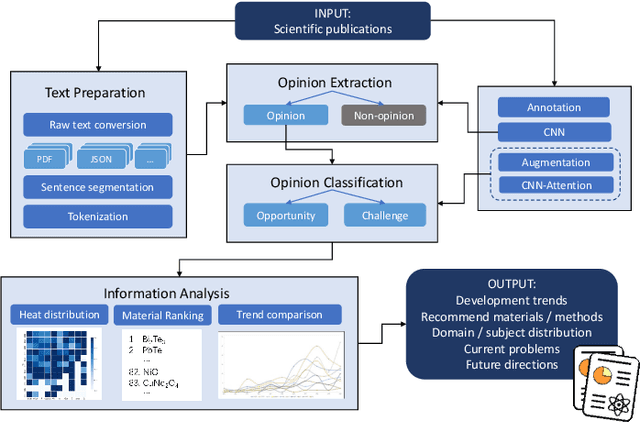
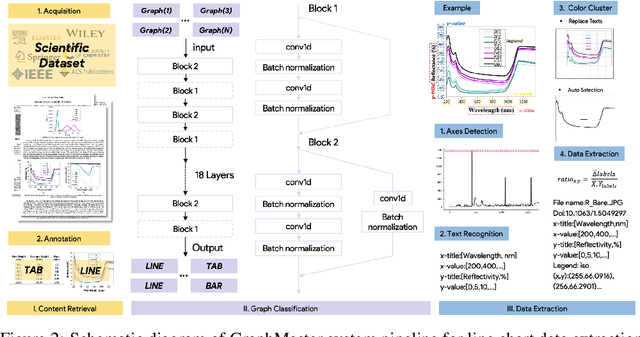
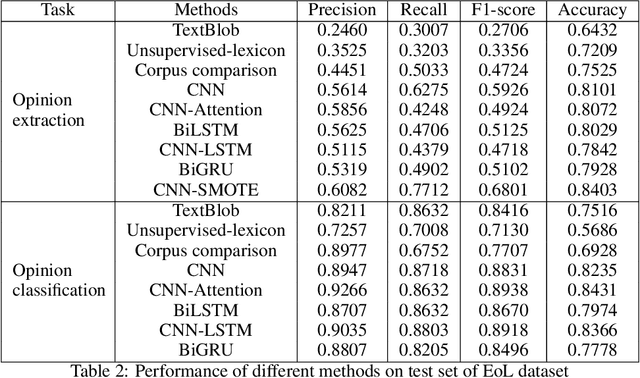
The material science literature contains up-to-date and comprehensive scientific knowledge of materials. However, their content is unstructured and diverse, resulting in a significant gap in providing sufficient information for material design and synthesis. To this end, we used natural language processing (NLP) and computer vision (CV) techniques based on convolutional neural networks (CNN) to discover valuable experimental-based information about nanomaterials and synthesis methods in energy-material-related publications. Our first system, TextMaster, extracts opinions from texts and classifies them into challenges and opportunities, achieving 94% and 92% accuracy, respectively. Our second system, GraphMaster, realizes data extraction of tables and figures from publications with 98.3\% classification accuracy and 4.3% data extraction mean square error. Our results show that these systems could assess the suitability of materials for a certain application by evaluation of synthesis insights and case analysis with detailed references. This work offers a fresh perspective on mining knowledge from scientific literature, providing a wide swatch to accelerate nanomaterial research through CNN.
Chinese Word Segmentation: Another Decade Review (2007-2017)
Jan 18, 2019This paper reviews the development of Chinese word segmentation (CWS) in the most recent decade, 2007-2017. Special attention was paid to the deep learning technologies that has already permeated into most areas of natural language processing (NLP). The basic view we have arrived at is that compared to traditional supervised learning methods, neural network based methods have not shown any superior performance. The most critical challenge still lies on balancing of recognition of in-vocabulary (IV) and out-of-vocabulary (OOV) words. However, as neural models have potentials to capture the essential linguistic structure of natural language, we are optimistic about significant progresses may arrive in the near future.