 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Visual Query Segmentation in the Wild
Mar 09, 2026In this paper, we introduce visual query segmentation (VQS), a new paradigm of visual query localization (VQL) that aims to segment all pixel-level occurrences of an object of interest in an untrimmed video, given an external visual query. Compared to existing VQL locating only the last appearance of a target using bounding boxes, VQS enables more comprehensive (i.e., all object occurrences) and precise (i.e., pixel-level masks) localization, making it more practical for real-world scenarios. To foster research on this task, we present VQS-4K, a large-scale benchmark dedicated to VQS. Specifically, VQS-4K contains 4,111 videos with more than 1.3 million frames and covers a diverse set of 222 object categories. Each video is paired with a visual query defined by a frame outside the search video and its target mask, and annotated with spatial-temporal masklets corresponding to the queried target. To ensure high quality, all videos in VQS-4K are manually labeled with meticulous inspection and iterative refinement. To the best of our knowledge, VQS-4K is the first benchmark specifically designed for VQS. Furthermore, to stimulate future research, we present a simple yet effective method, named VQ-SAM, which extends SAM 2 by leveraging target-specific and background distractor cues from the video to progressively evolve the memory through a novel multi-stage framework with an adaptive memory generation (AMG) module for VQS, significantly improving the performance. In our extensive experiments on VQS-4K, VQ-SAM achieves promising results and surpasses all existing approaches, demonstrating its effectiveness. With the proposed VQS-4K and VQ-SAM, we expect to go beyond the current VQL paradigm and inspire more future research and practical applications on VQS. Our benchmark, code, and results will be made publicly available.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Poly-FEVER: A Multilingual Fact Verification Benchmark for Hallucination Detection in Large Language Models
Mar 19, 2025Hallucinations in generative AI, particularly in Large Language Models (LLMs), pose a significant challenge to the reliability of multilingual applications. Existing benchmarks for hallucination detection focus primarily on English and a few widely spoken languages, lacking the breadth to assess inconsistencies in model performance across diverse linguistic contexts. To address this gap, we introduce Poly-FEVER, a large-scale multilingual fact verification benchmark specifically designed for evaluating hallucination detection in LLMs. Poly-FEVER comprises 77,973 labeled factual claims spanning 11 languages, sourced from FEVER, Climate-FEVER, and SciFact. It provides the first large-scale dataset tailored for analyzing hallucination patterns across languages, enabling systematic evaluation of LLMs such as ChatGPT and the LLaMA series. Our analysis reveals how topic distribution and web resource availability influence hallucination frequency, uncovering language-specific biases that impact model accuracy. By offering a multilingual benchmark for fact verification, Poly-FEVER facilitates cross-linguistic comparisons of hallucination detection and contributes to the development of more reliable, language-inclusive AI systems. The dataset is publicly available to advance research in responsible AI, fact-checking methodologies, and multilingual NLP, promoting greater transparency and robustness in LLM performance. The proposed Poly-FEVER is available at: https://huggingface.co/datasets/HanzhiZhang/Poly-FEVER.
ByteScience: Bridging Unstructured Scientific Literature and Structured Data with Auto Fine-tuned Large Language Model in Token Granularity
Nov 18, 2024



Natural Language Processing (NLP) is widely used to supply summarization ability from long context to structured information. However, extracting structured knowledge from scientific text by NLP models remains a challenge because of its domain-specific nature to complex data preprocessing and the granularity of multi-layered device-level information. To address this, we introduce ByteScience, a non-profit cloud-based auto fine-tuned Large Language Model (LLM) platform, which is designed to extract structured scientific data and synthesize new scientific knowledge from vast scientific corpora. The platform capitalizes on DARWIN, an open-source, fine-tuned LLM dedicated to natural science. The platform was built on Amazon Web Services (AWS) and provides an automated, user-friendly workflow for custom model development and data extraction. The platform achieves remarkable accuracy with only a small amount of well-annotated articles. This innovative tool streamlines the transition from the science literature to structured knowledge and data and benefits the advancements in natural informatics.
HALO: Hallucination Analysis and Learning Optimization to Empower LLMs with Retrieval-Augmented Context for Guided Clinical Decision Making
Sep 16, 2024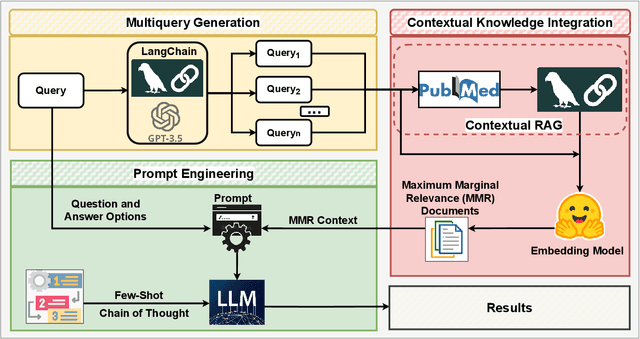
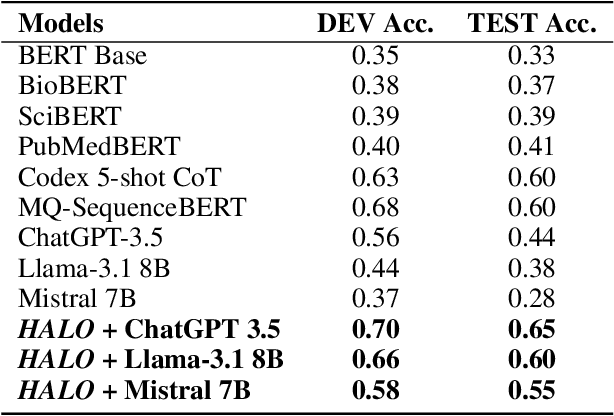


Large language models (LLMs) have significantly advanced natural language processing tasks, yet they are susceptible to generating inaccurate or unreliable responses, a phenomenon known as hallucination. In critical domains such as health and medicine, these hallucinations can pose serious risks. This paper introduces HALO, a novel framework designed to enhance the accuracy and reliability of medical question-answering (QA) systems by focusing on the detection and mitigation of hallucinations. Our approach generates multiple variations of a given query using LLMs and retrieves relevant information from external open knowledge bases to enrich the context. We utilize maximum marginal relevance scoring to prioritize the retrieved context, which is then provided to LLMs for answer generation, thereby reducing the risk of hallucinations. The integration of LangChain further streamlines this process, resulting in a notable and robust increase in the accuracy of both open-source and commercial LLMs, such as Llama-3.1 (from 44% to 65%) and ChatGPT (from 56% to 70%). This framework underscores the critical importance of addressing hallucinations in medical QA systems, ultimately improving clinical decision-making and patient care. The open-source HALO is available at: https://github.com/ResponsibleAILab/HALO.