 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoly-FEVER: A Multilingual Fact Verification Benchmark for Hallucination Detection in Large Language Models
Mar 19, 2025Hallucinations in generative AI, particularly in Large Language Models (LLMs), pose a significant challenge to the reliability of multilingual applications. Existing benchmarks for hallucination detection focus primarily on English and a few widely spoken languages, lacking the breadth to assess inconsistencies in model performance across diverse linguistic contexts. To address this gap, we introduce Poly-FEVER, a large-scale multilingual fact verification benchmark specifically designed for evaluating hallucination detection in LLMs. Poly-FEVER comprises 77,973 labeled factual claims spanning 11 languages, sourced from FEVER, Climate-FEVER, and SciFact. It provides the first large-scale dataset tailored for analyzing hallucination patterns across languages, enabling systematic evaluation of LLMs such as ChatGPT and the LLaMA series. Our analysis reveals how topic distribution and web resource availability influence hallucination frequency, uncovering language-specific biases that impact model accuracy. By offering a multilingual benchmark for fact verification, Poly-FEVER facilitates cross-linguistic comparisons of hallucination detection and contributes to the development of more reliable, language-inclusive AI systems. The dataset is publicly available to advance research in responsible AI, fact-checking methodologies, and multilingual NLP, promoting greater transparency and robustness in LLM performance. The proposed Poly-FEVER is available at: https://huggingface.co/datasets/HanzhiZhang/Poly-FEVER.
HALO: Hallucination Analysis and Learning Optimization to Empower LLMs with Retrieval-Augmented Context for Guided Clinical Decision Making
Sep 16, 2024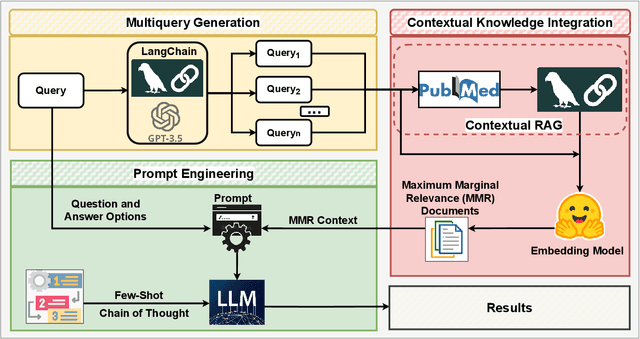
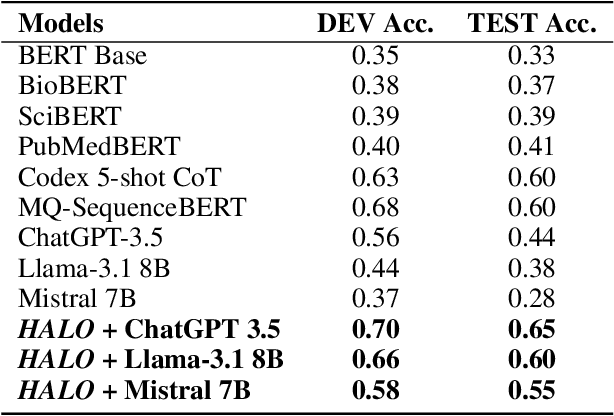


Large language models (LLMs) have significantly advanced natural language processing tasks, yet they are susceptible to generating inaccurate or unreliable responses, a phenomenon known as hallucination. In critical domains such as health and medicine, these hallucinations can pose serious risks. This paper introduces HALO, a novel framework designed to enhance the accuracy and reliability of medical question-answering (QA) systems by focusing on the detection and mitigation of hallucinations. Our approach generates multiple variations of a given query using LLMs and retrieves relevant information from external open knowledge bases to enrich the context. We utilize maximum marginal relevance scoring to prioritize the retrieved context, which is then provided to LLMs for answer generation, thereby reducing the risk of hallucinations. The integration of LangChain further streamlines this process, resulting in a notable and robust increase in the accuracy of both open-source and commercial LLMs, such as Llama-3.1 (from 44% to 65%) and ChatGPT (from 56% to 70%). This framework underscores the critical importance of addressing hallucinations in medical QA systems, ultimately improving clinical decision-making and patient care. The open-source HALO is available at: https://github.com/ResponsibleAILab/HALO.