 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDiT: Semantic Region-Adaptive for Diffusion Transformers
Jan 18, 2026Diffusion Transformers (DiTs) achieve state-of-the-art performance in text-to-image synthesis but remain computationally expensive due to the iterative nature of denoising and the quadratic cost of global attention. In this work, we observe that denoising dynamics are spatially non-uniform-background regions converge rapidly while edges and textured areas evolve much more actively. Building on this insight, we propose SDiT, a Semantic Region-Adaptive Diffusion Transformer that allocates computation according to regional complexity. SDiT introduces a training-free framework combining (1) semantic-aware clustering via fast Quickshift-based segmentation, (2) complexity-driven regional scheduling to selectively update informative areas, and (3) boundary-aware refinement to maintain spatial coherence. Without any model retraining or architectural modification, SDiT achieves up to 3.0x acceleration while preserving nearly identical perceptual and semantic quality to full-attention inference.
Poly-FEVER: A Multilingual Fact Verification Benchmark for Hallucination Detection in Large Language Models
Mar 19, 2025Hallucinations in generative AI, particularly in Large Language Models (LLMs), pose a significant challenge to the reliability of multilingual applications. Existing benchmarks for hallucination detection focus primarily on English and a few widely spoken languages, lacking the breadth to assess inconsistencies in model performance across diverse linguistic contexts. To address this gap, we introduce Poly-FEVER, a large-scale multilingual fact verification benchmark specifically designed for evaluating hallucination detection in LLMs. Poly-FEVER comprises 77,973 labeled factual claims spanning 11 languages, sourced from FEVER, Climate-FEVER, and SciFact. It provides the first large-scale dataset tailored for analyzing hallucination patterns across languages, enabling systematic evaluation of LLMs such as ChatGPT and the LLaMA series. Our analysis reveals how topic distribution and web resource availability influence hallucination frequency, uncovering language-specific biases that impact model accuracy. By offering a multilingual benchmark for fact verification, Poly-FEVER facilitates cross-linguistic comparisons of hallucination detection and contributes to the development of more reliable, language-inclusive AI systems. The dataset is publicly available to advance research in responsible AI, fact-checking methodologies, and multilingual NLP, promoting greater transparency and robustness in LLM performance. The proposed Poly-FEVER is available at: https://huggingface.co/datasets/HanzhiZhang/Poly-FEVER.
GFormer: Accelerating Large Language Models with Optimized Transformers on Gaudi Processors
Dec 19, 2024



Heterogeneous hardware like Gaudi processor has been developed to enhance computations, especially matrix operations for Transformer-based large language models (LLMs) for generative AI tasks. However, our analysis indicates that Transformers are not fully optimized on such emerging hardware, primarily due to inadequate optimizations in non-matrix computational kernels like Softmax and in heterogeneous resource utilization, particularly when processing long sequences. To address these issues, we propose an integrated approach (called GFormer) that merges sparse and linear attention mechanisms. GFormer aims to maximize the computational capabilities of the Gaudi processor's Matrix Multiplication Engine (MME) and Tensor Processing Cores (TPC) without compromising model quality. GFormer includes a windowed self-attention kernel and an efficient outer product kernel for causal linear attention, aiming to optimize LLM inference on Gaudi processors. Evaluation shows that GFormer significantly improves efficiency and model performance across various tasks on the Gaudi processor and outperforms state-of-the-art GPUs.
S3LLM: Large-Scale Scientific Software Understanding with LLMs using Source, Metadata, and Document
Mar 15, 2024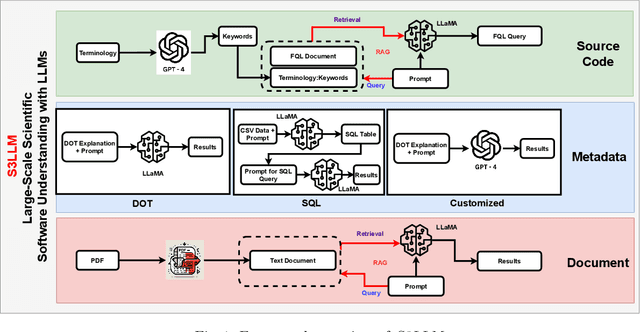


The understanding of large-scale scientific software poses significant challenges due to its diverse codebase, extensive code length, and target computing architectures. The emergence of generative AI, specifically large language models (LLMs), provides novel pathways for understanding such complex scientific codes. This paper presents S3LLM, an LLM-based framework designed to enable the examination of source code, code metadata, and summarized information in conjunction with textual technical reports in an interactive, conversational manner through a user-friendly interface. S3LLM leverages open-source LLaMA-2 models to enhance code analysis through the automatic transformation of natural language queries into domain-specific language (DSL) queries. Specifically, it translates these queries into Feature Query Language (FQL), enabling efficient scanning and parsing of entire code repositories. In addition, S3LLM is equipped to handle diverse metadata types, including DOT, SQL, and customized formats. Furthermore, S3LLM incorporates retrieval augmented generation (RAG) and LangChain technologies to directly query extensive documents. S3LLM demonstrates the potential of using locally deployed open-source LLMs for the rapid understanding of large-scale scientific computing software, eliminating the need for extensive coding expertise, and thereby making the process more efficient and effective. S3LLM is available at https://github.com/ResponsibleAILab/s3llm.
Rapid detection of rare events from in situ X-ray diffraction data using machine learning
Dec 07, 2023High-energy X-ray diffraction methods can non-destructively map the 3D microstructure and associated attributes of metallic polycrystalline engineering materials in their bulk form. These methods are often combined with external stimuli such as thermo-mechanical loading to take snapshots over time of the evolving microstructure and attributes. However, the extreme data volumes and the high costs of traditional data acquisition and reduction approaches pose a barrier to quickly extracting actionable insights and improving the temporal resolution of these snapshots. Here we present a fully automated technique capable of rapidly detecting the onset of plasticity in high-energy X-ray microscopy data. Our technique is computationally faster by at least 50 times than the traditional approaches and works for data sets that are up to 9 times sparser than a full data set. This new technique leverages self-supervised image representation learning and clustering to transform massive data into compact, semantic-rich representations of visually salient characteristics (e.g., peak shapes). These characteristics can be a rapid indicator of anomalous events such as changes in diffraction peak shapes. We anticipate that this technique will provide just-in-time actionable information to drive smarter experiments that effectively deploy multi-modal X-ray diffraction methods that span many decades of length scales.
Benchmarking and In-depth Performance Study of Large Language Models on Habana Gaudi Processors
Sep 29, 2023

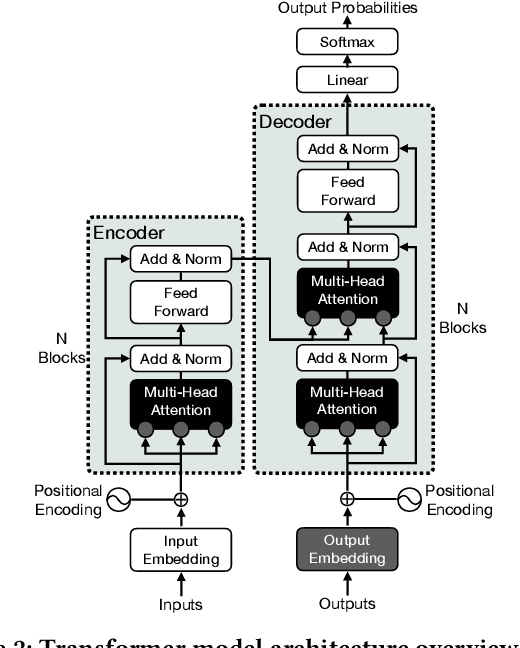

Transformer models have achieved remarkable success in various machine learning tasks but suffer from high computational complexity and resource requirements. The quadratic complexity of the self-attention mechanism further exacerbates these challenges when dealing with long sequences and large datasets. Specialized AI hardware accelerators, such as the Habana GAUDI architecture, offer a promising solution to tackle these issues. GAUDI features a Matrix Multiplication Engine (MME) and a cluster of fully programmable Tensor Processing Cores (TPC). This paper explores the untapped potential of using GAUDI processors to accelerate Transformer-based models, addressing key challenges in the process. Firstly, we provide a comprehensive performance comparison between the MME and TPC components, illuminating their relative strengths and weaknesses. Secondly, we explore strategies to optimize MME and TPC utilization, offering practical insights to enhance computational efficiency. Thirdly, we evaluate the performance of Transformers on GAUDI, particularly in handling long sequences and uncovering performance bottlenecks. Lastly, we evaluate the end-to-end performance of two Transformer-based large language models (LLM) on GAUDI. The contributions of this work encompass practical insights for practitioners and researchers alike. We delve into GAUDI's capabilities for Transformers through systematic profiling, analysis, and optimization exploration. Our study bridges a research gap and offers a roadmap for optimizing Transformer-based model training on the GAUDI architecture.